Toggle Poster Visibility
Fri Dec 09 08:30 AM -- 09:00 AM (PST) None
Tobias Gerstenberg
Fri Dec 09 09:00 AM -- 09:15 AM (PST) None
ESCHER: ESCHEWING IMPORTANCE SAMPLING IN GAMES BY COMPUTING A HISTORY VALUE FUNCTION TO ESTIMATE REGRET
[
Poster]
[
OpenReview]
[
Topia]
{kind=link}
Fri Dec 09 09:15 AM -- 09:30 AM (PST) None
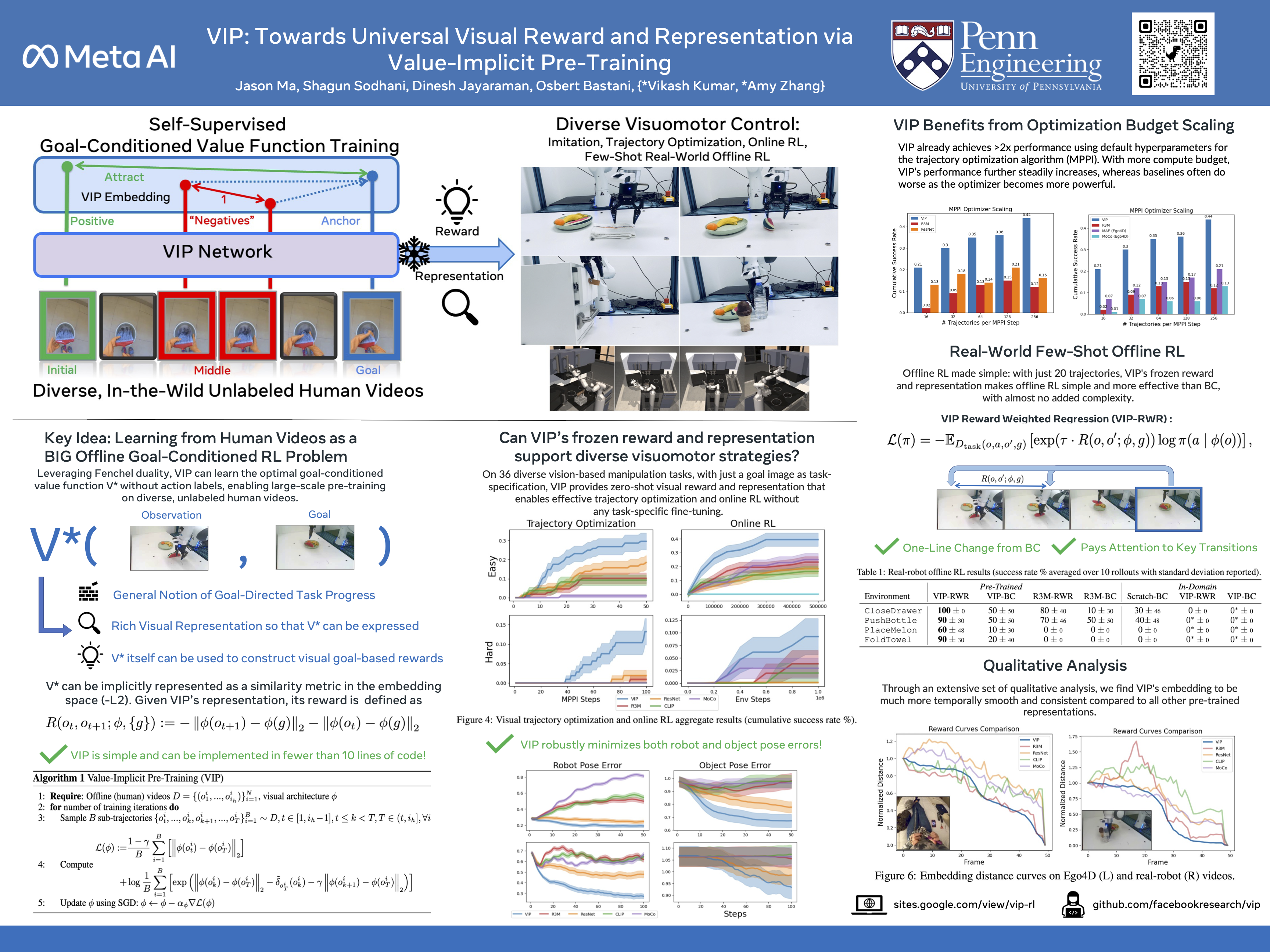
Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
[
Poster]
[
OpenReview]
[
Topia]
{kind=link}
Fri Dec 09 09:30 AM -- 09:45 AM (PST) None
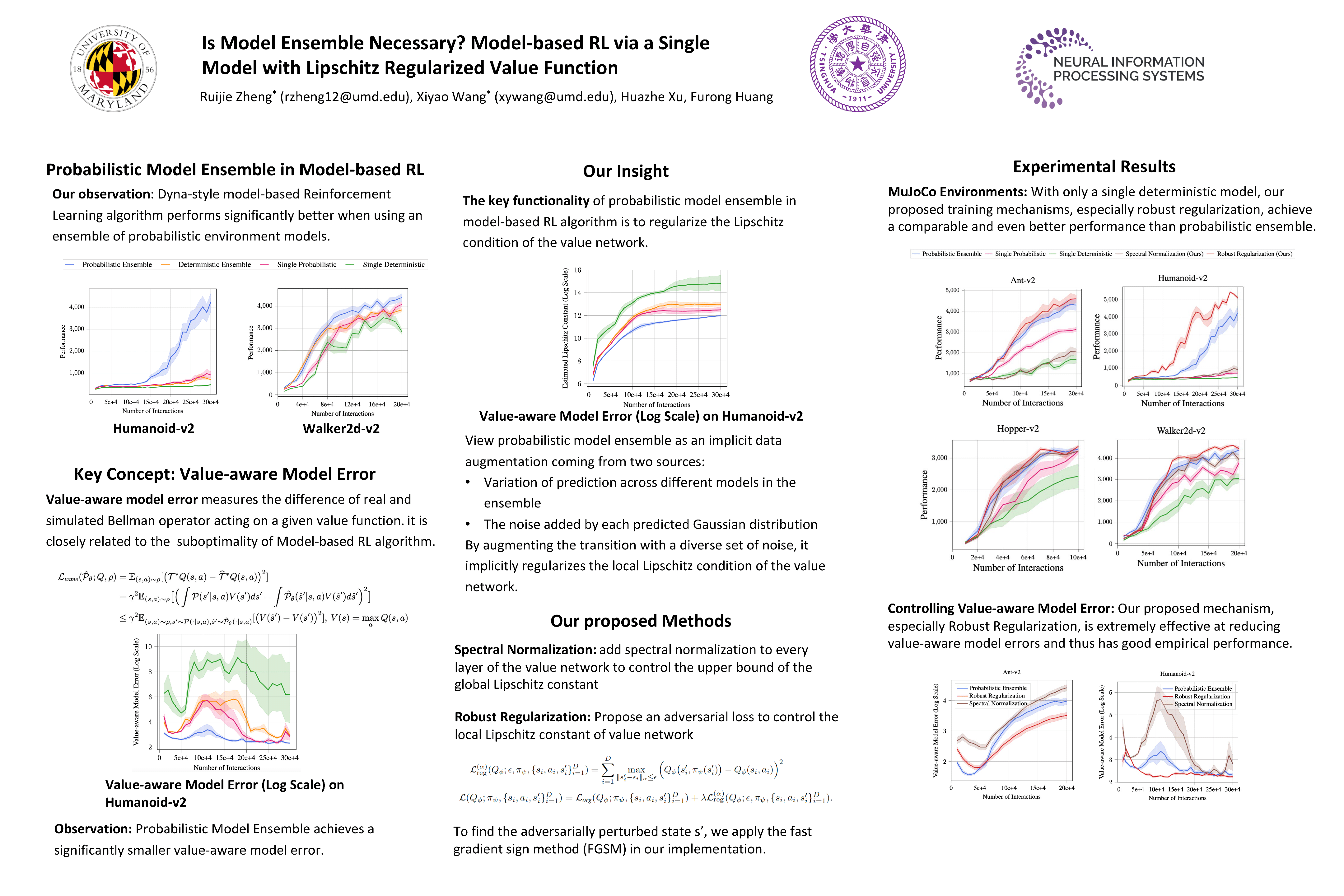
Is Model Ensemble Necessary? Model-based RL via a Single Model with Lipschitz Regularized Value Function
[
Poster]
[
OpenReview]
[
Topia]
{kind=link}
Fri Dec 09 09:45 AM -- 10:00 AM (PST) None
Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes
[
OpenReview]
[
Topia]
Fri Dec 09 11:00 AM -- 11:30 AM (PST) None
Scientific Experiments in Reinforcement Learning
Fri Dec 09 11:30 AM -- 11:45 AM (PST) None
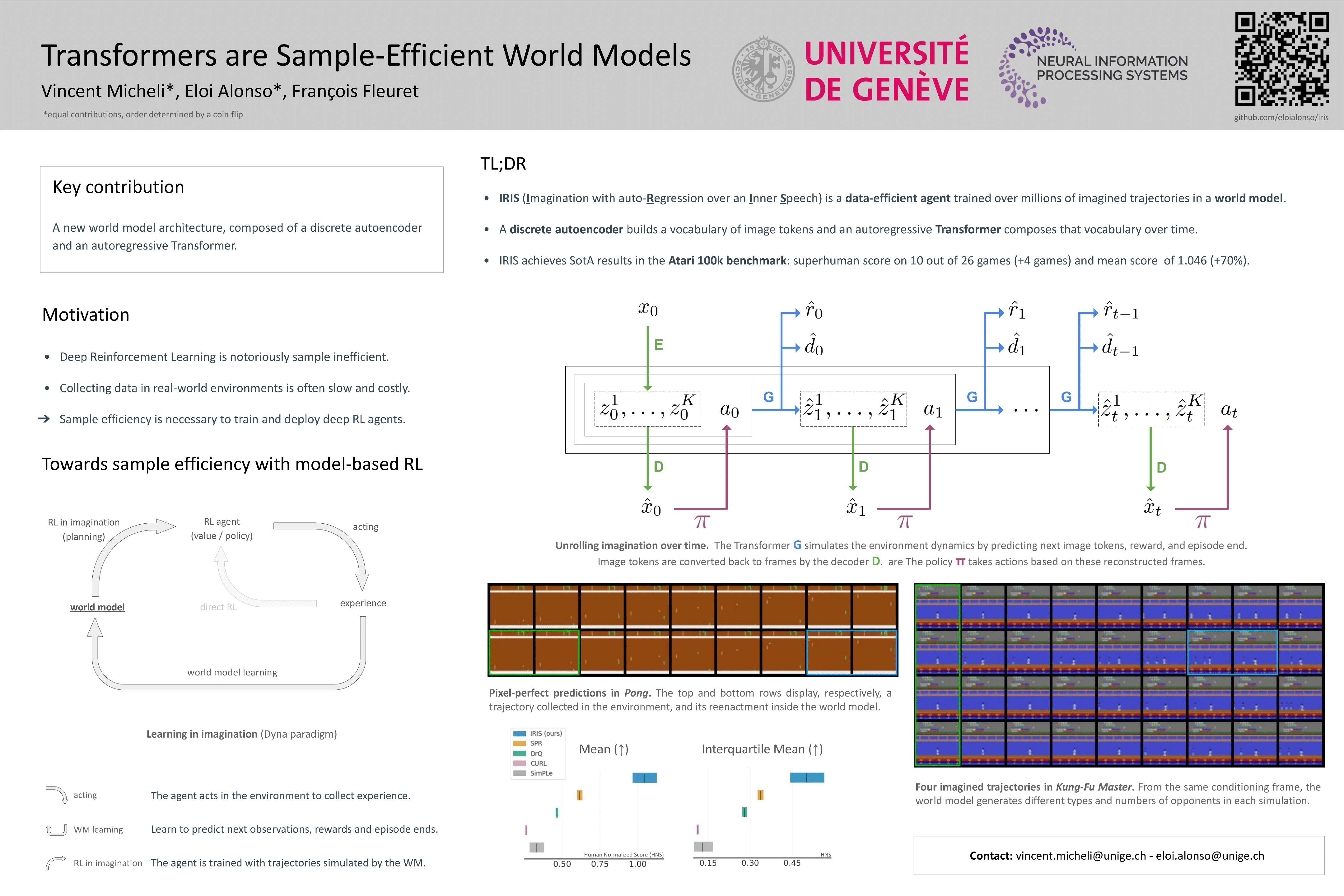
Transformers are Sample-Efficient World Models
[
Poster]
[
OpenReview]
[
Topia]
{kind=link}
Fri Dec 09 11:45 AM -- 12:00 PM (PST) None
Scaling Laws for a Multi-Agent Reinforcement Learning Model
[
Poster]
[
OpenReview]
[
Topia]
{kind=link}
Fri Dec 09 01:30 PM -- 02:00 PM (PST) None
The World is not Uniformly Distributed; Important Implications for Deep RL
Fri Dec 09 04:00 PM -- 04:15 PM (PST) None
Kristian Hartikainen
Fri Dec 09 04:15 PM -- 04:30 PM (PST) None
Ilya Kostrikov, Aviral Kumar
None
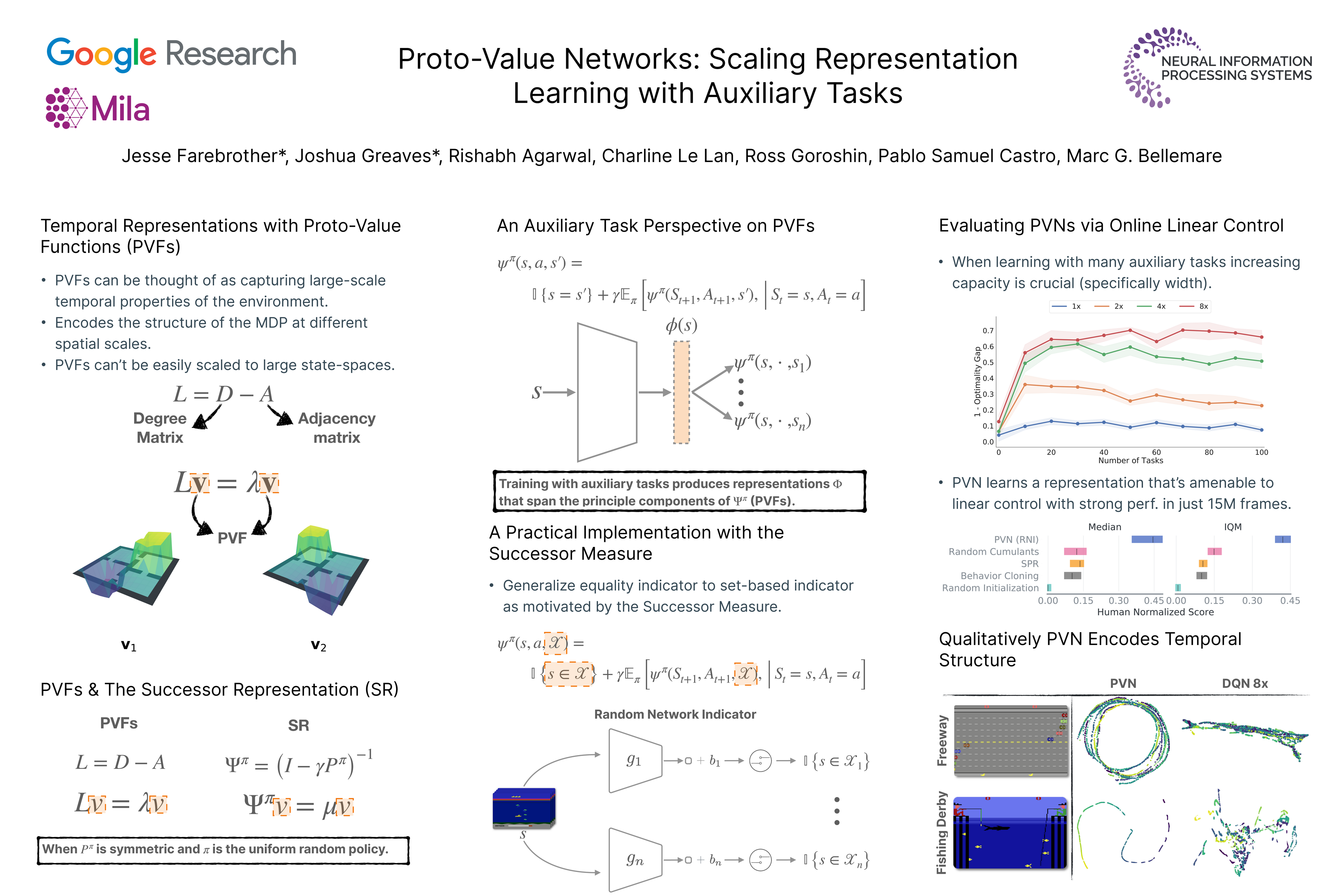
Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks
{kind=link}
None
A Game-Theoretic Perspective of Generalization in Reinforcement Learning
{kind=link}
None
Quantization-aware Policy Distillation (QPD)
{kind=link}
None
Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search
{kind=link}
None
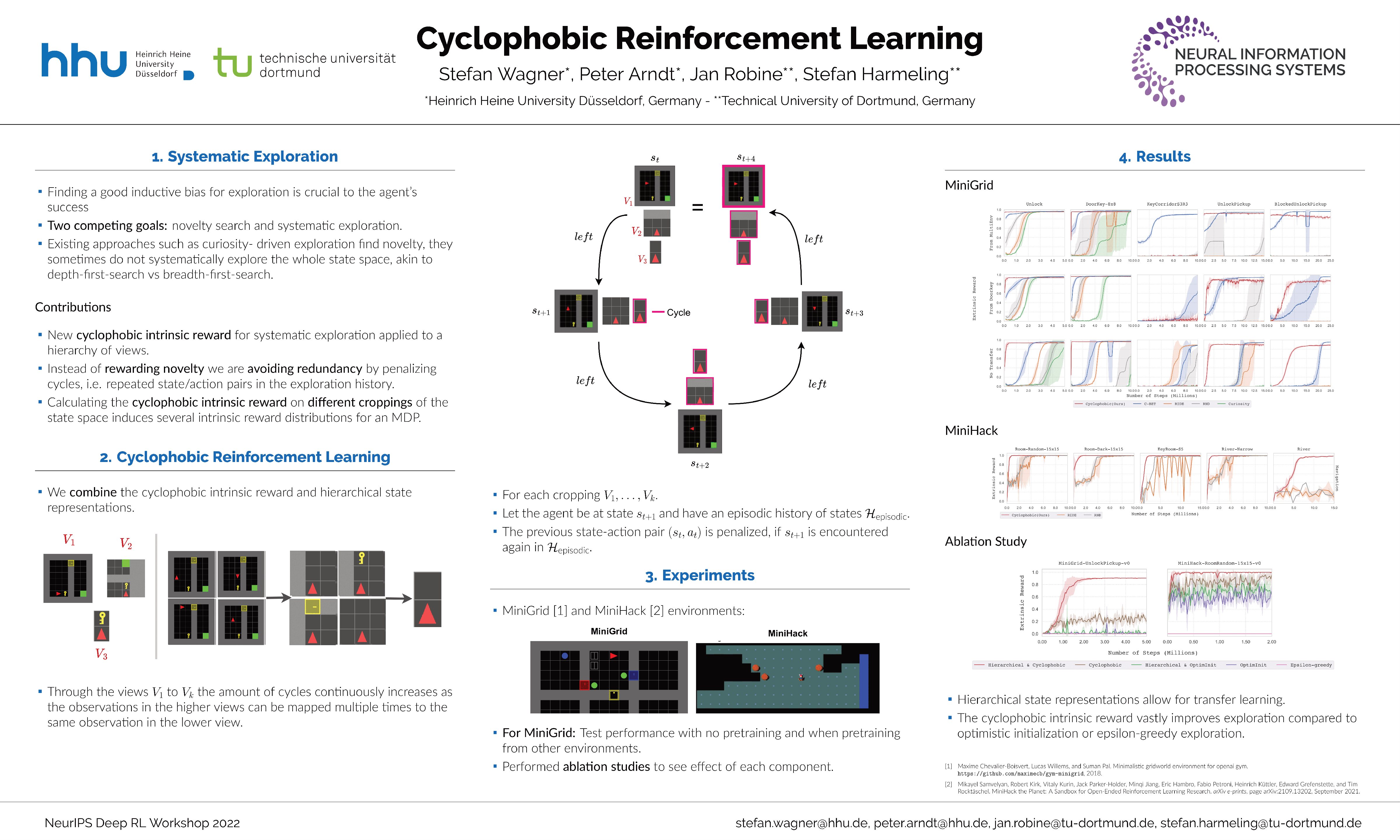
Cyclophobic Reinforcement Learning
{kind=link}
None
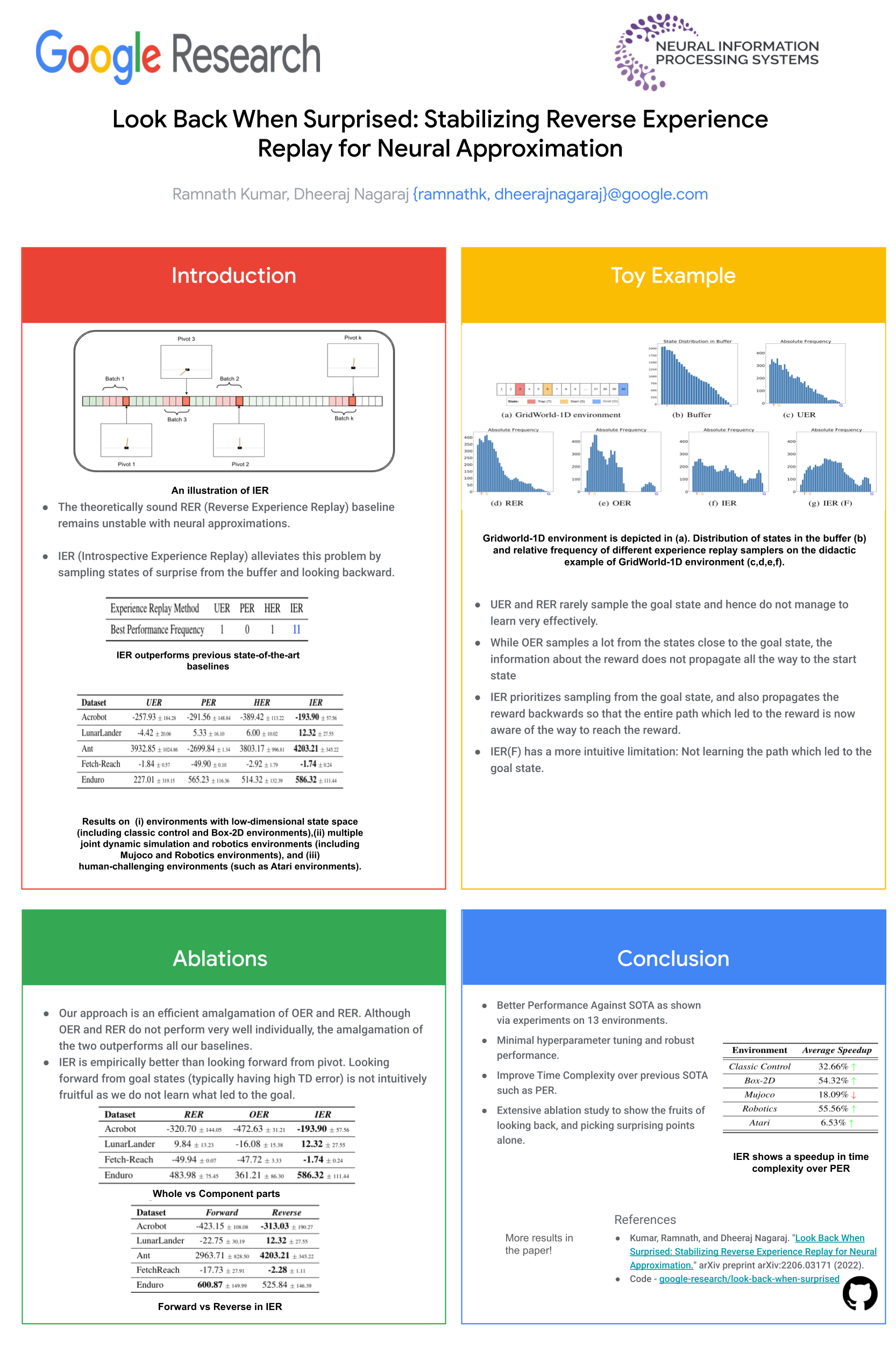
Look Back When Surprised: Stabilizing Reverse Experience Replay for Neural Approximation
{kind=link}
None
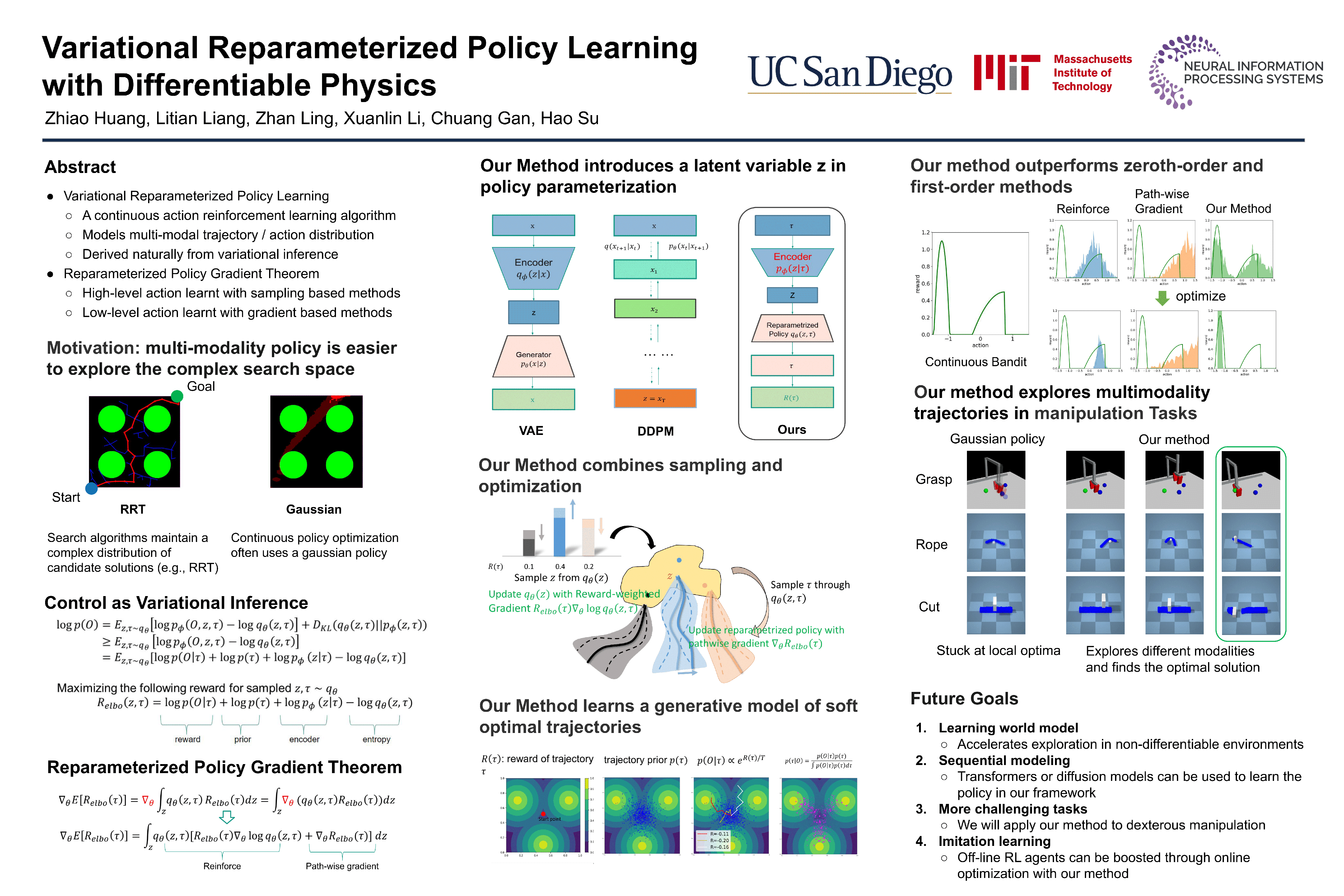
VARIATIONAL REPARAMETRIZED POLICY LEARNING WITH DIFFERENTIABLE PHYSICS
{kind=link}
None
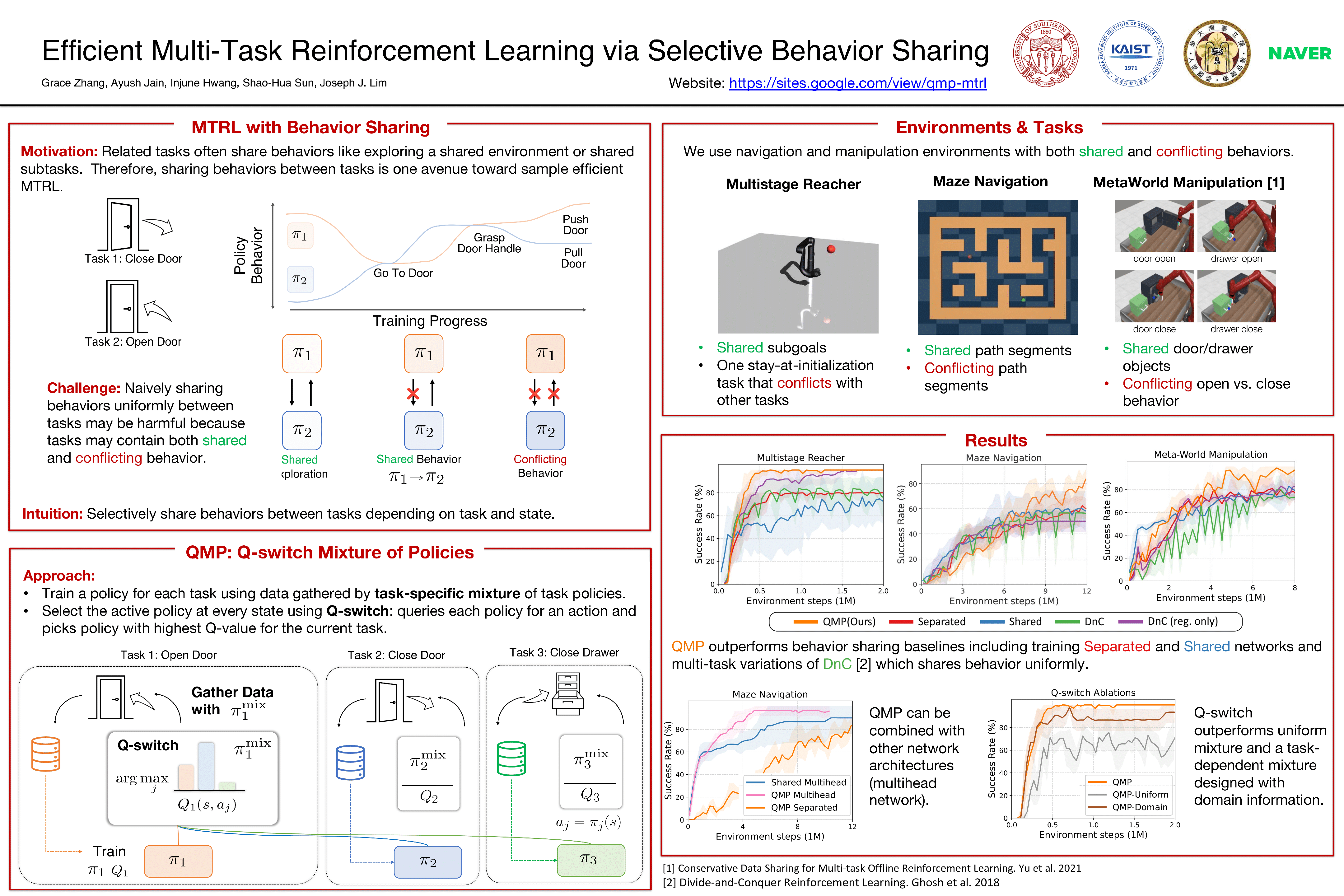
Efficient Multi-Task Reinforcement Learning via Selective Behavior Sharing
{kind=link}
None
A study of natural robustness of deep reinforcement learning algorithms towards adversarial perturbations
{kind=link}
None
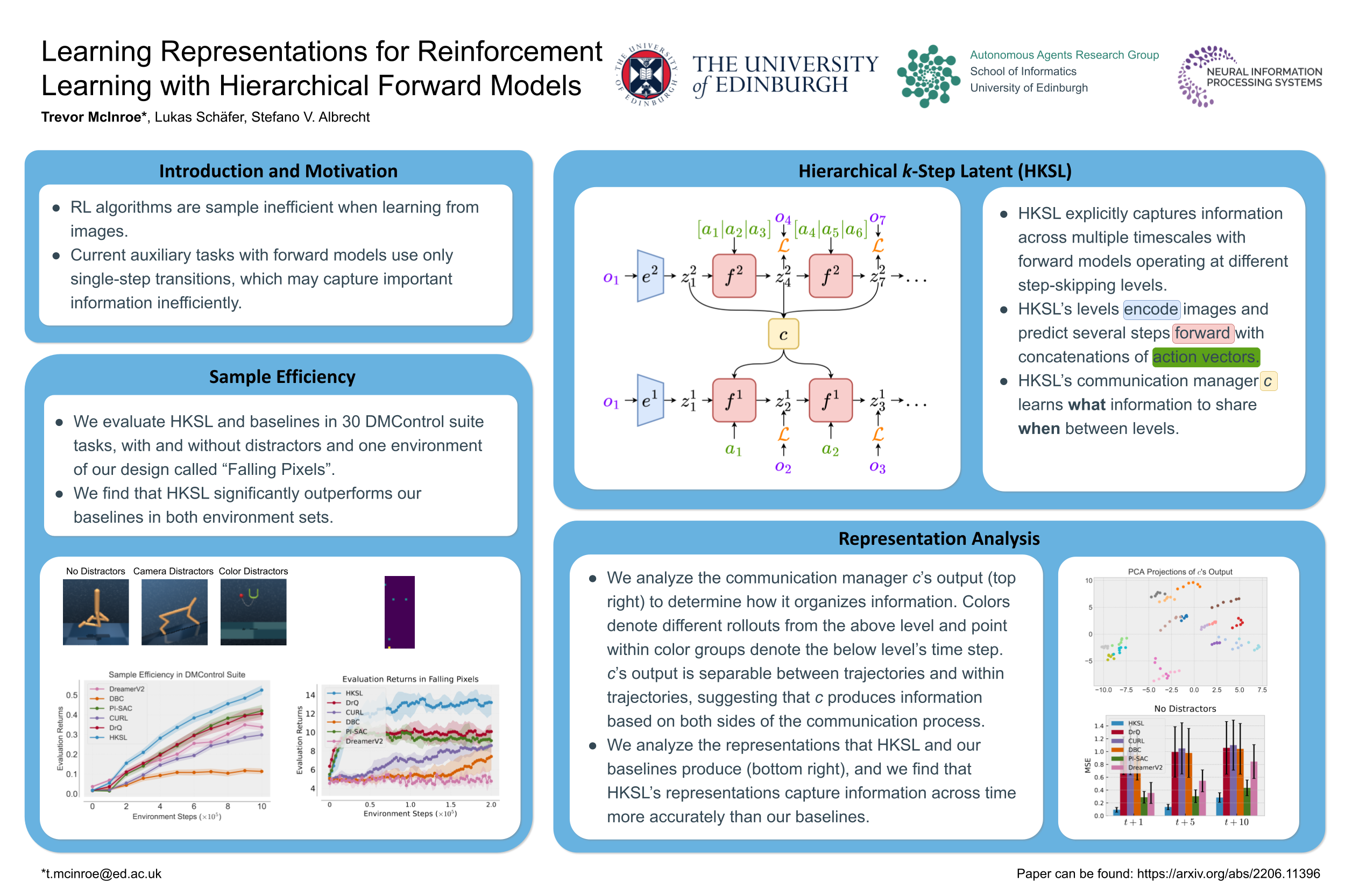
Learning Representations for Reinforcement Learning with Hierarchical Forward Models
{kind=link}
None
Towards True Lossless Sparse Communication in Multi-Agent Systems
{kind=link}
None
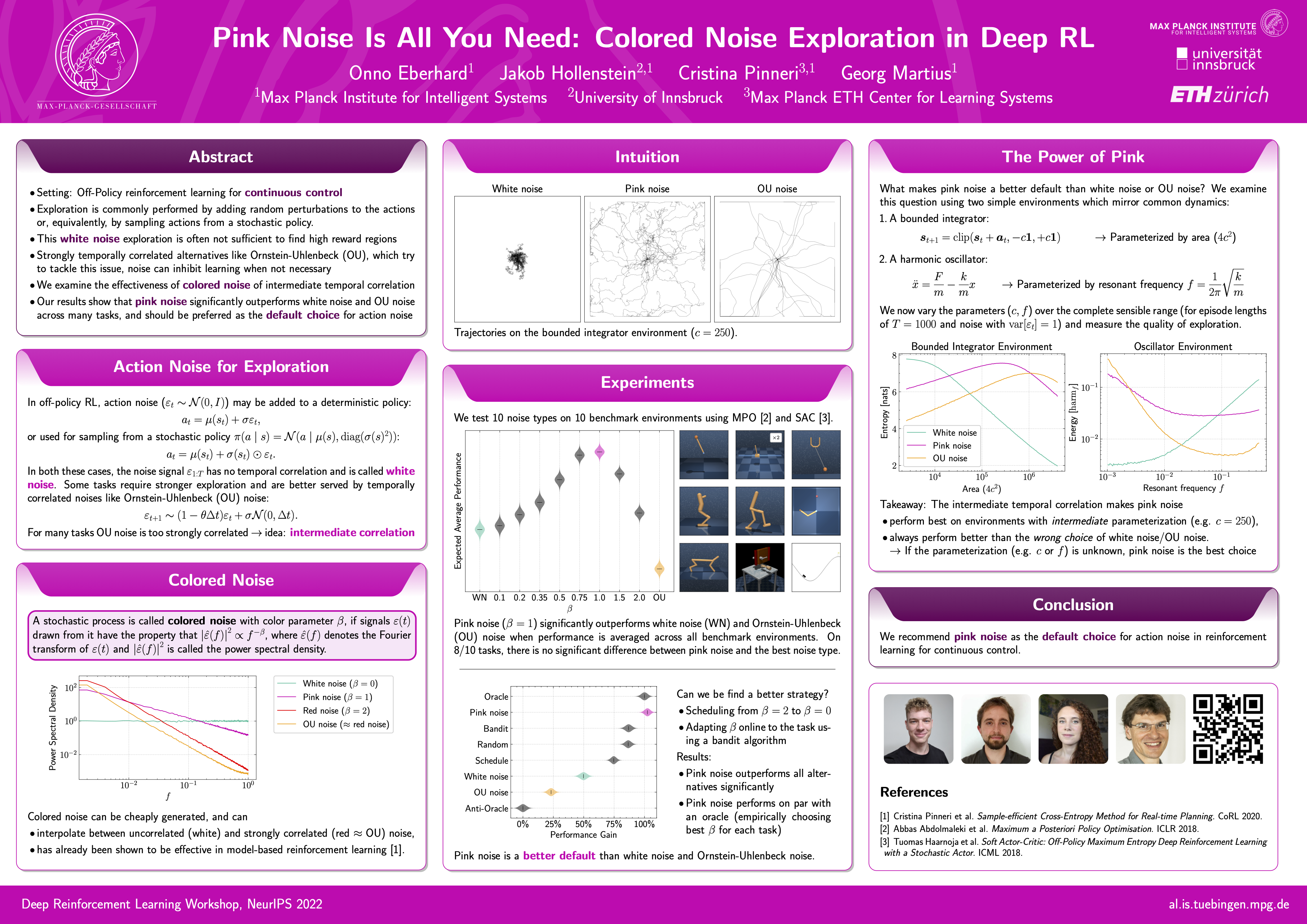
Pink Noise Is All You Need: Colored Noise Exploration in Deep Reinforcement Learning
{kind=link}
None
Learning a Domain-Agnostic Policy through Adversarial Representation Matching for Cross-Domain Policy Transfer
{kind=link}
None
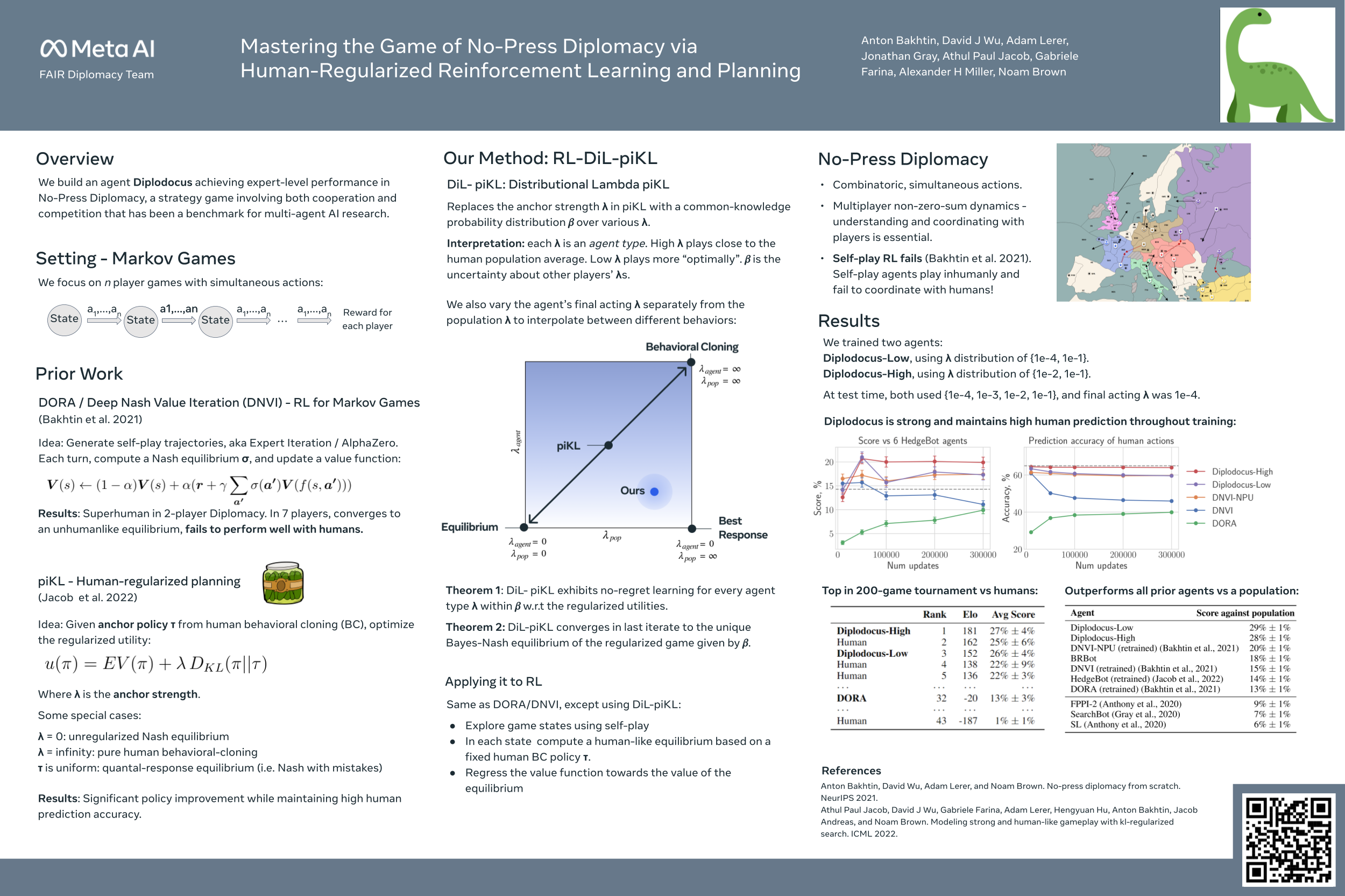
Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
{kind=link}
None
Choreographer: Learning and Adapting Skills in Imagination
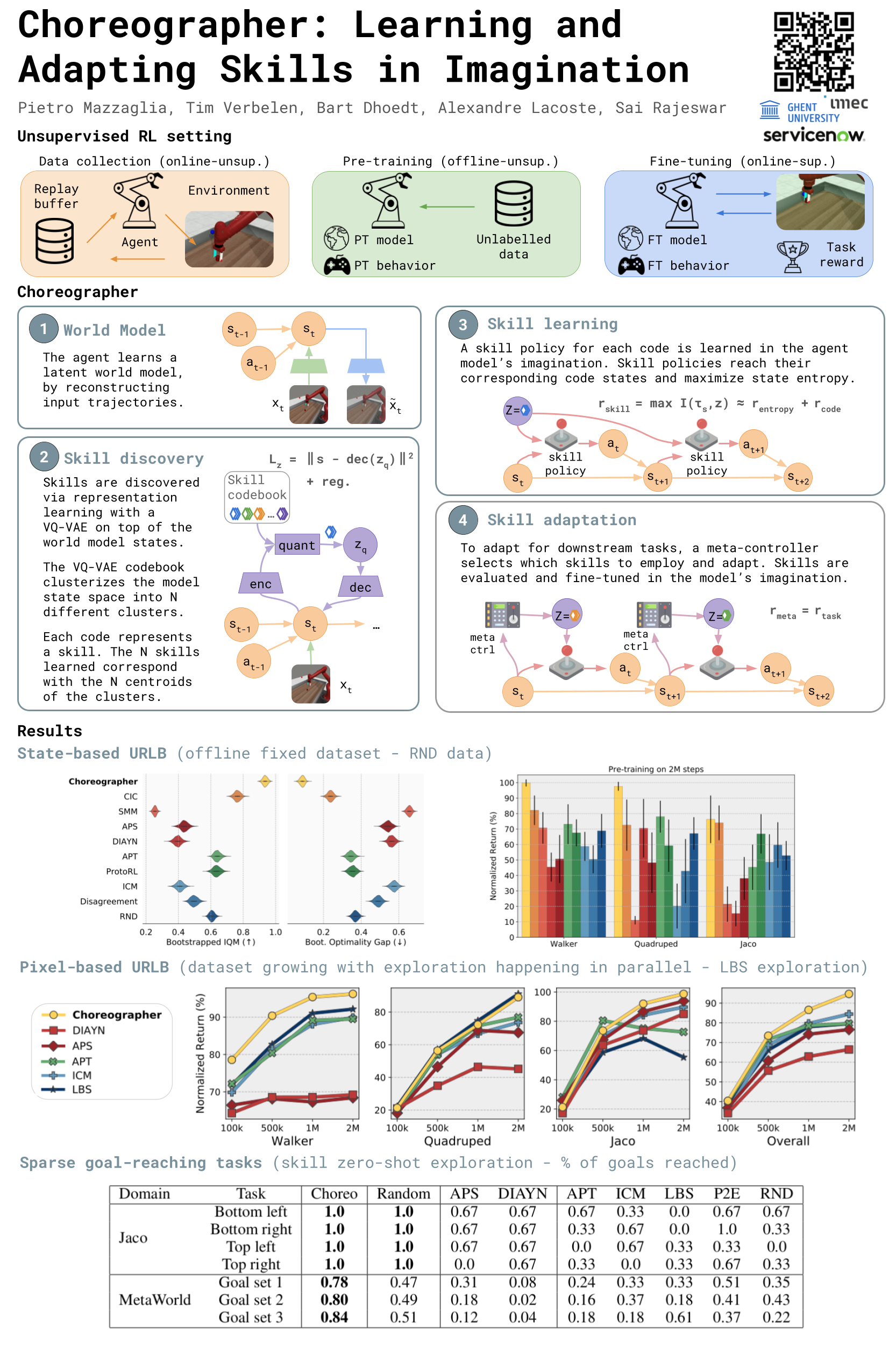{kind=link}
None
Efficient Offline Policy Optimization with a Learned Model
{kind=link}
None
Language Models Can Teach Themselves to Program Better
{kind=link}
None
Graph Q-Learning for Combinatorial Optimization
{kind=link}
None
CASA: Bridging the Gap between Policy Improvement and Policy Evaluation with Conflict Averse Policy Iteration
[
OpenReview]
[
Topia]
None
Hierarchical Abstraction for Combinatorial Generalization in Object Rearrangement
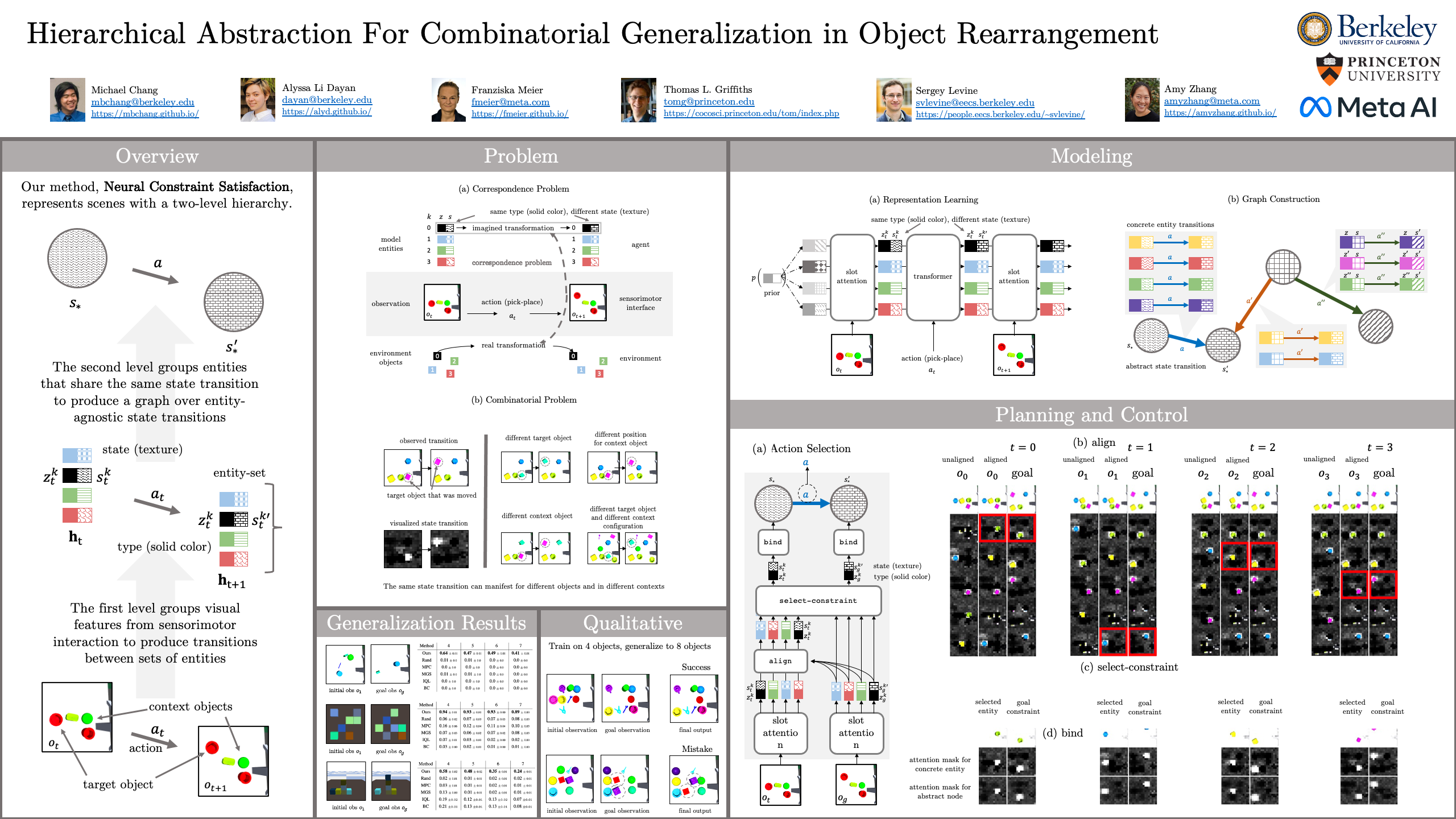{kind=link}
None
A Ranking Game for Imitation Learning
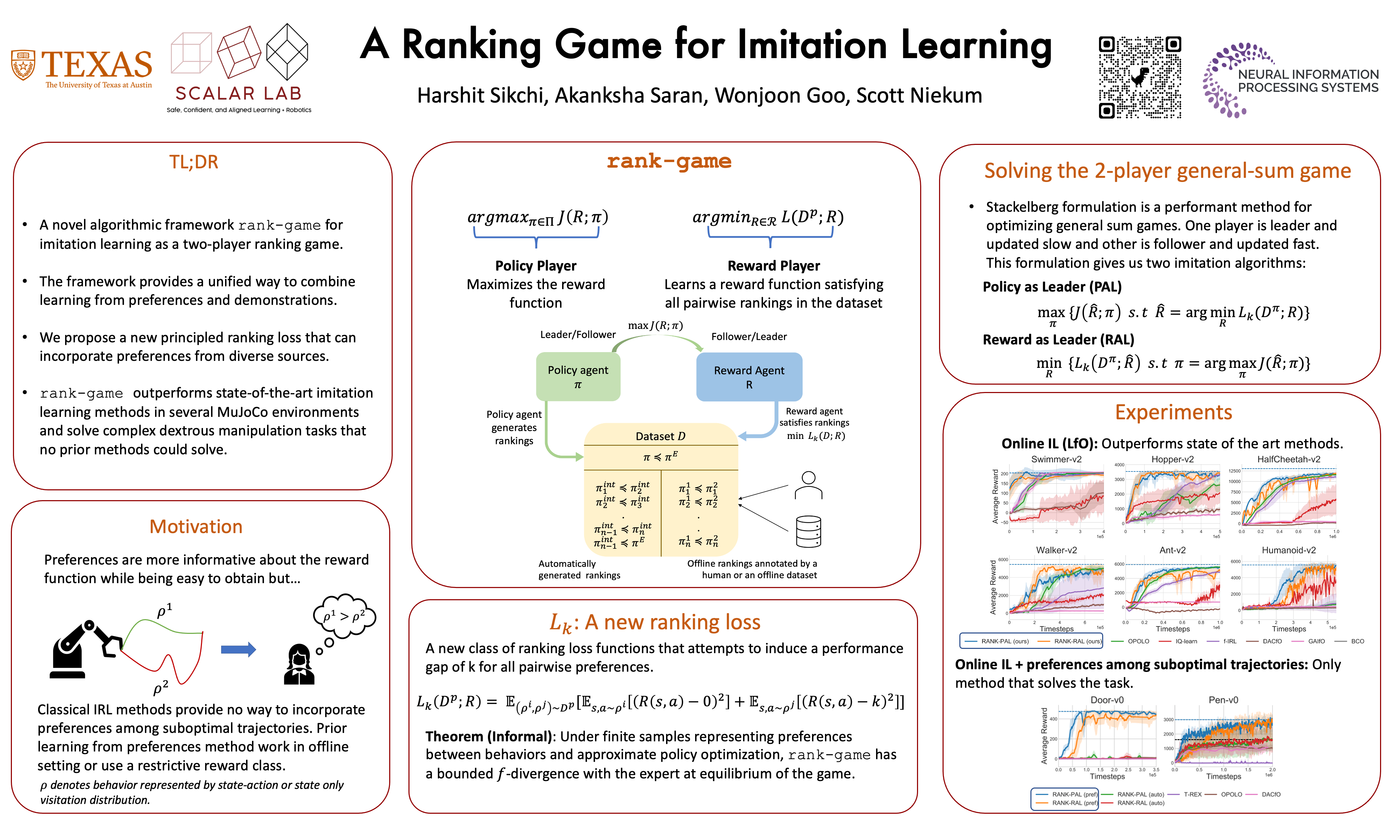{kind=link}
None
Distributional deep Q-learning with CVaR regression
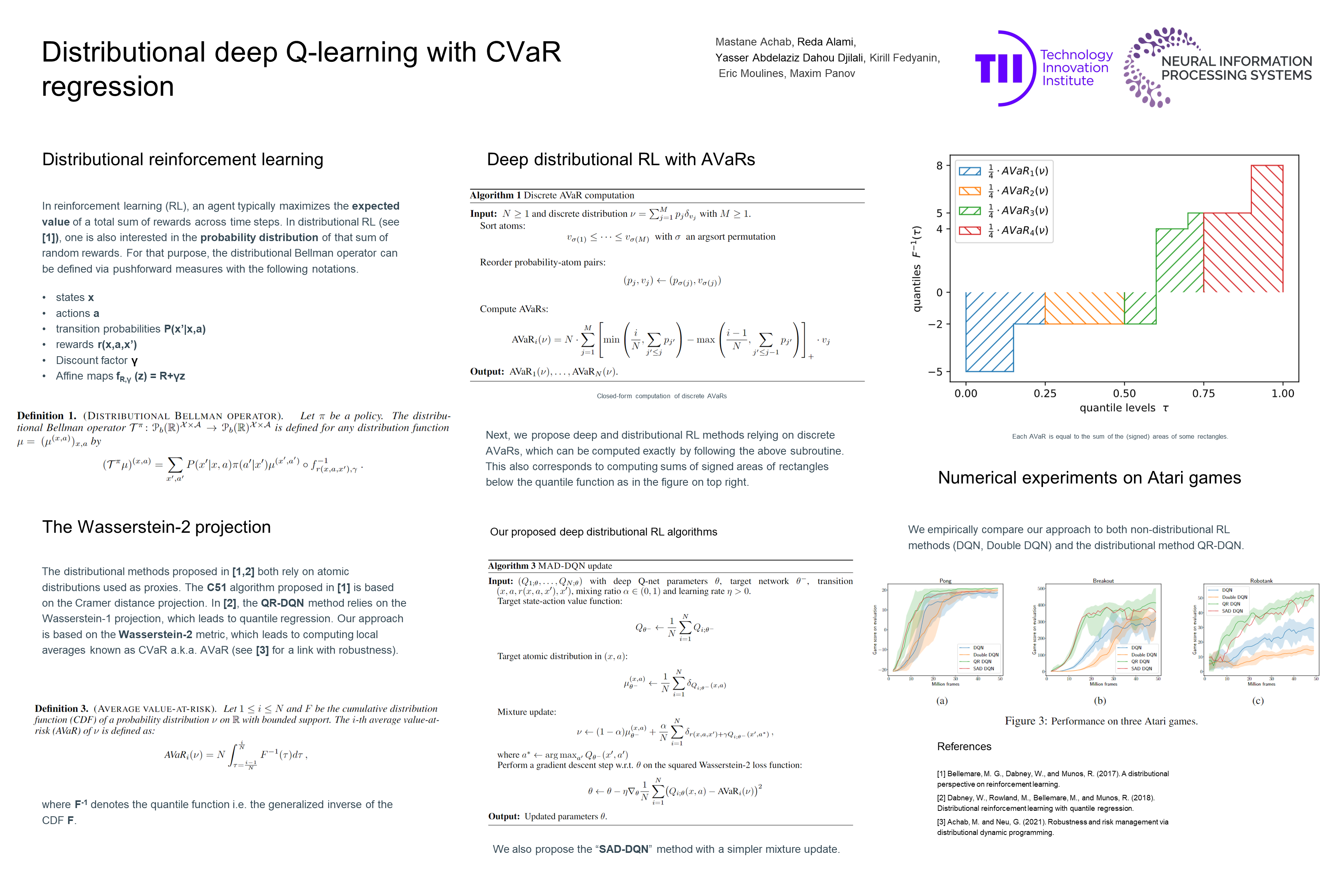{kind=link}
None
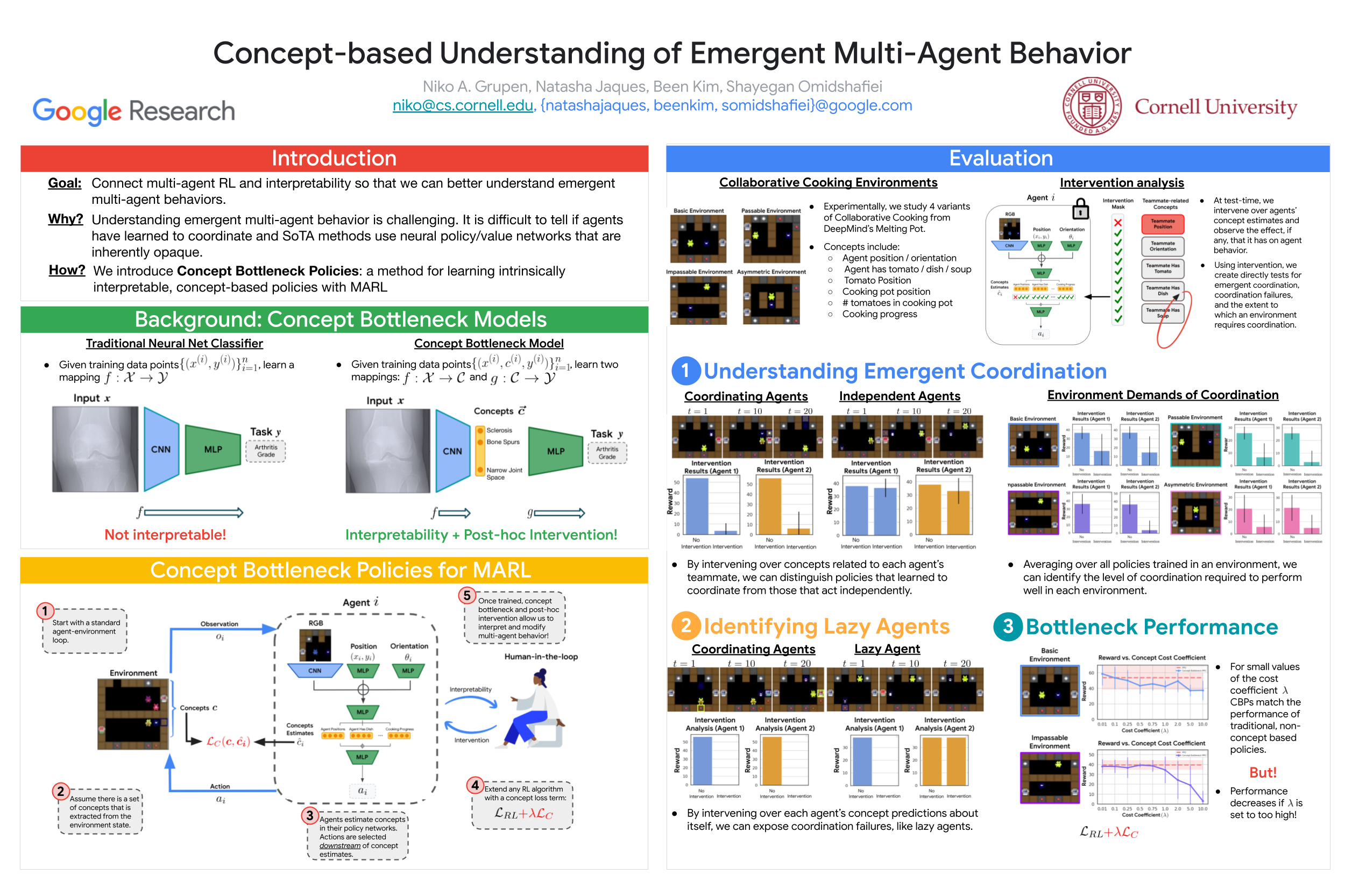
Concept-based Understanding of Emergent Multi-Agent Behavior
{kind=link}
None
Constrained Imitation Q-learning with Earth Mover’s Distance reward
{kind=link}
None
SoftTreeMax: Policy Gradient with Tree Search
{kind=link}
None
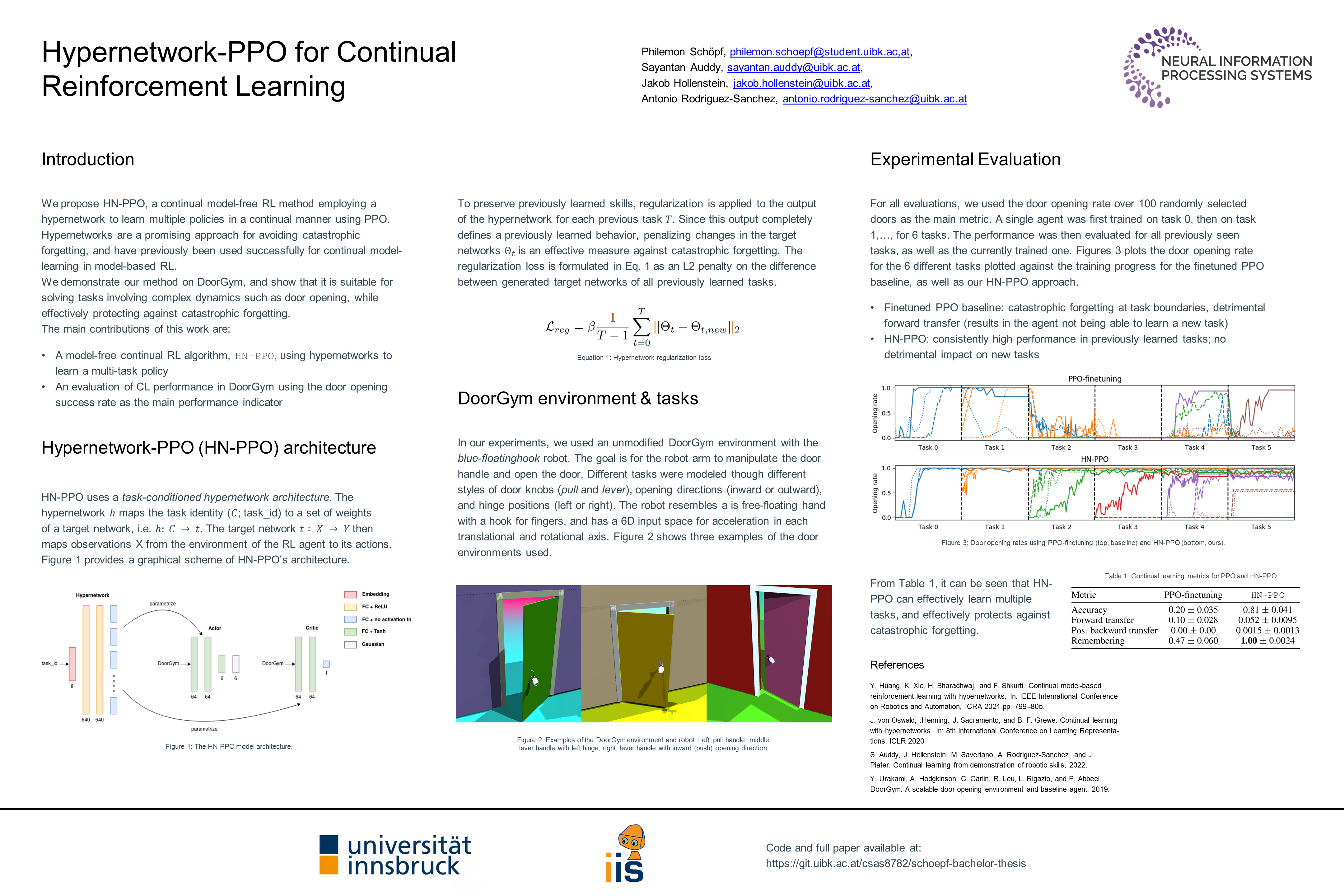
Hypernetwork-PPO for Continual Reinforcement Learning
{kind=link}
None
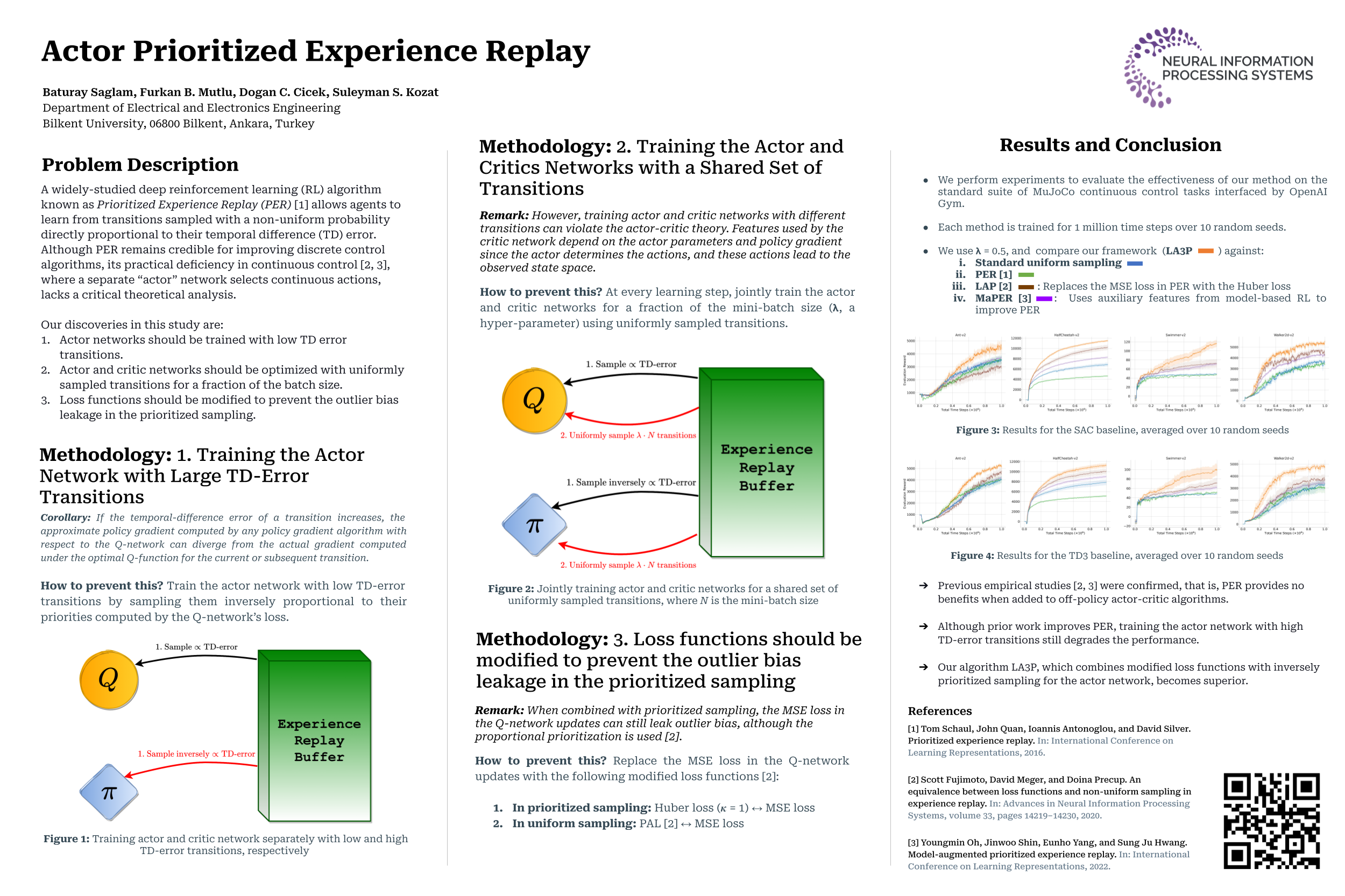
Actor Prioritized Experience Replay
{kind=link}
None
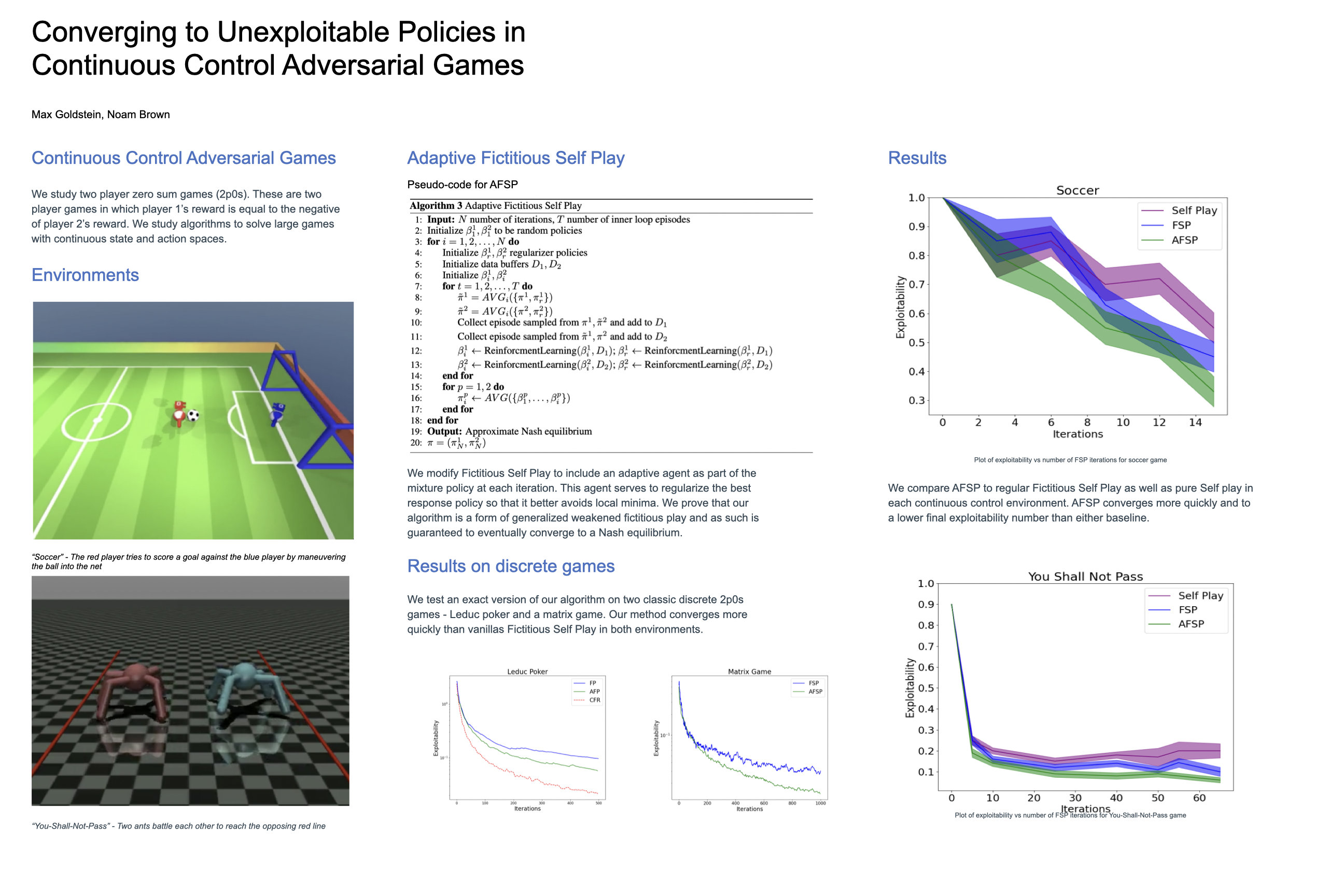
Converging to Unexploitable Policies in Continuous Control Adversarial Games
{kind=link}
None
A Connection between One-Step Regularization and Critic Regularization in Reinforcement Learning
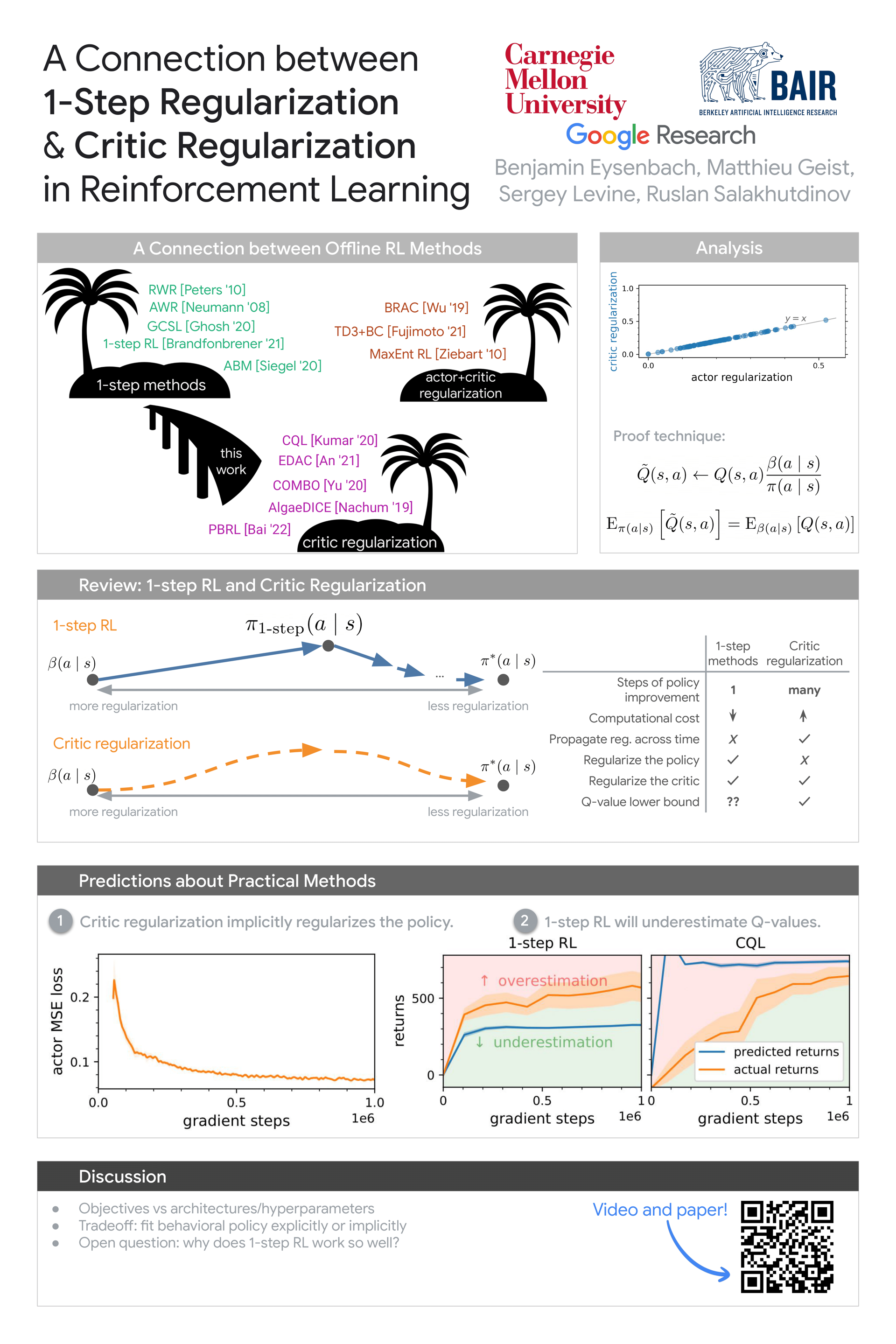{kind=link}
None
Training graph neural networks with policy gradients to perform tree search
{kind=link}
None
Co-Imitation: Learning Design and Behaviour by Imitation
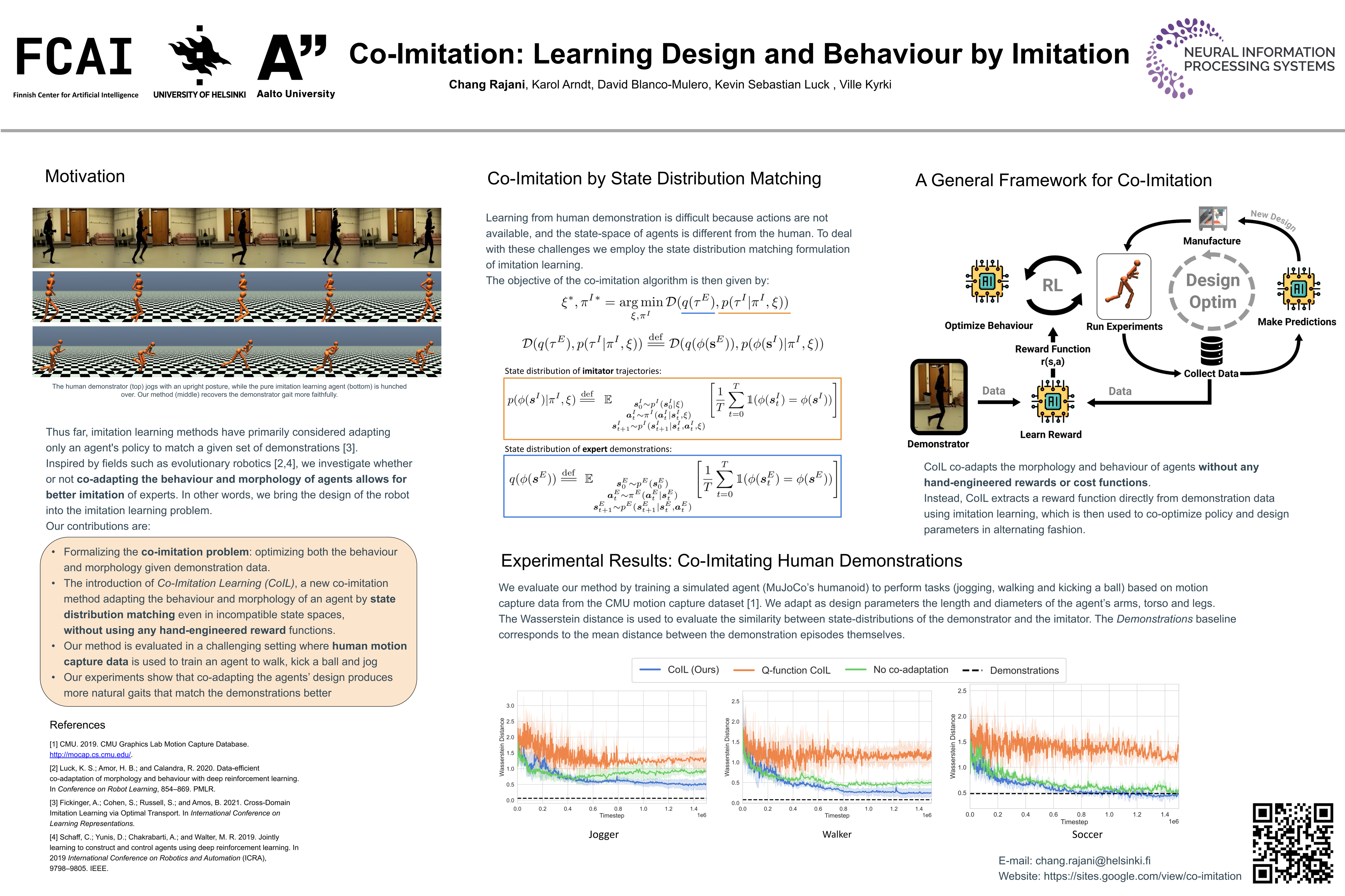{kind=link}
None
Rewarding Episodic Visitation Discrepancy for Exploration in Reinforcement Learning
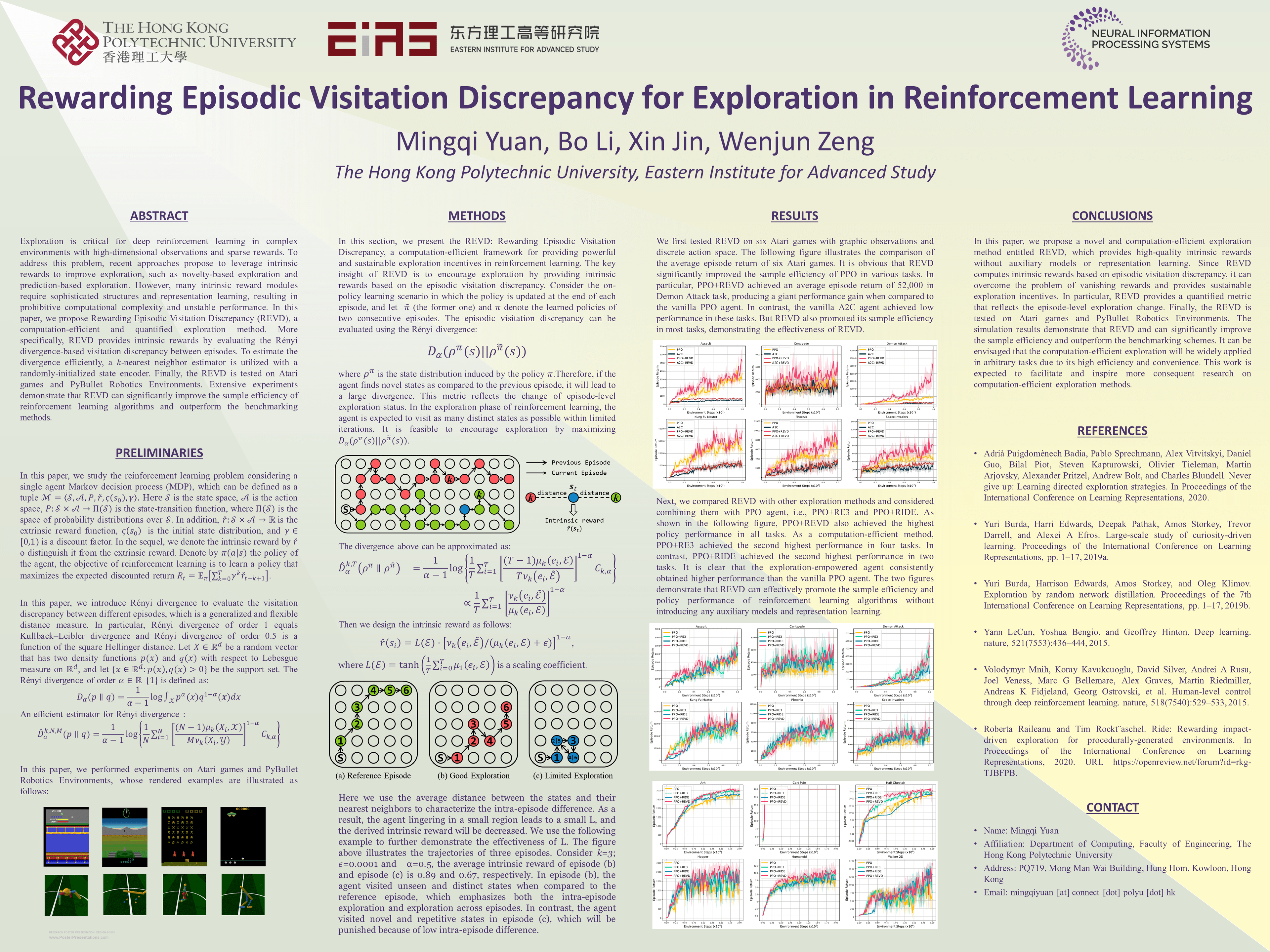{kind=link}
None
PCRL: Priority Convention Reinforcement Learning for Microscopically Sequencable Multi-agent Problems
{kind=link}
None
PD-MORL: Preference-Driven Multi-Objective Reinforcement Learning Algorithm
{kind=link}
None
Selectively Sharing Experiences Improves Multi-Agent Reinforcement Learning
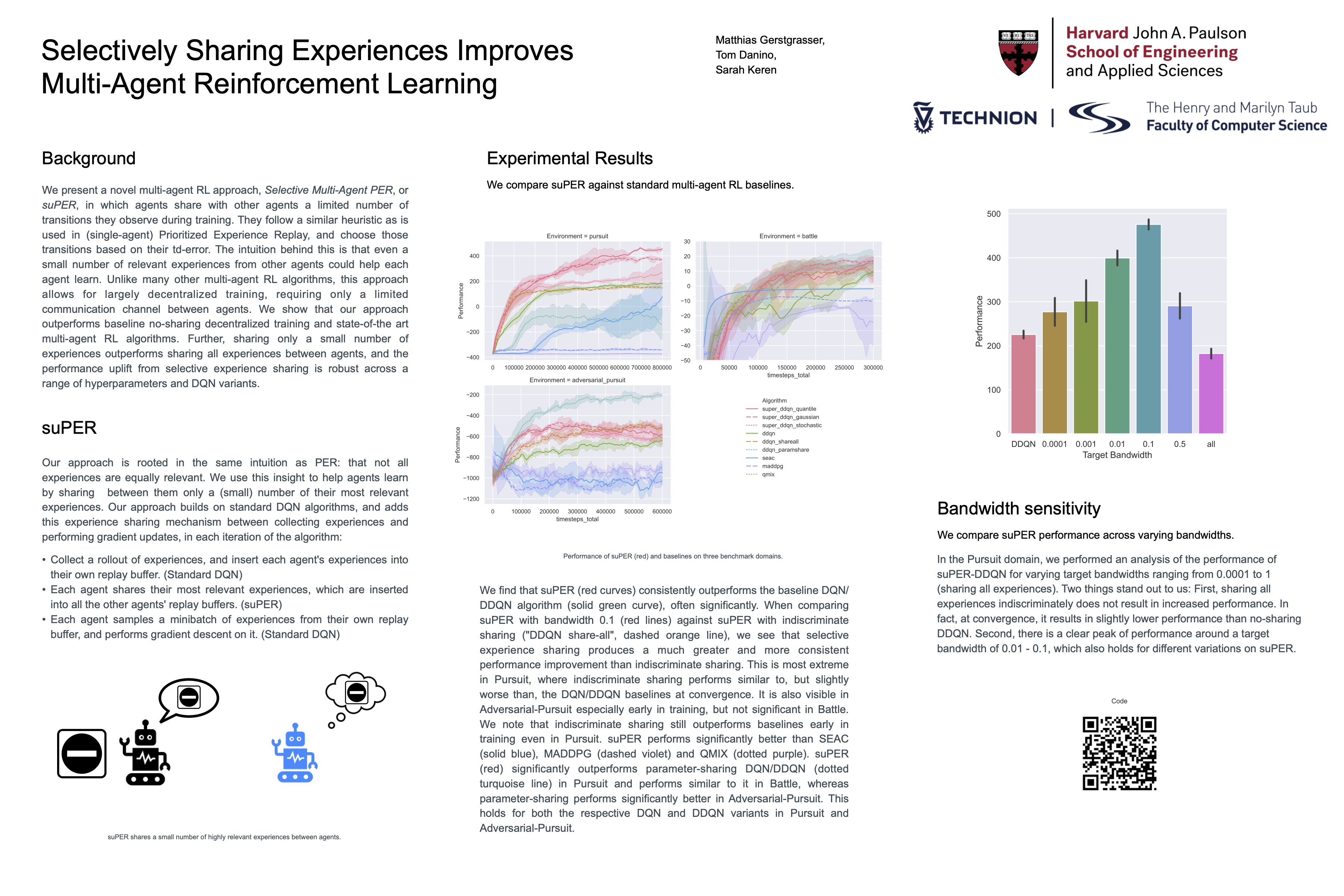{kind=link}
None
Pretraining the Vision Transformer using self-supervised methods for vision based Deep Reinforcement Learning
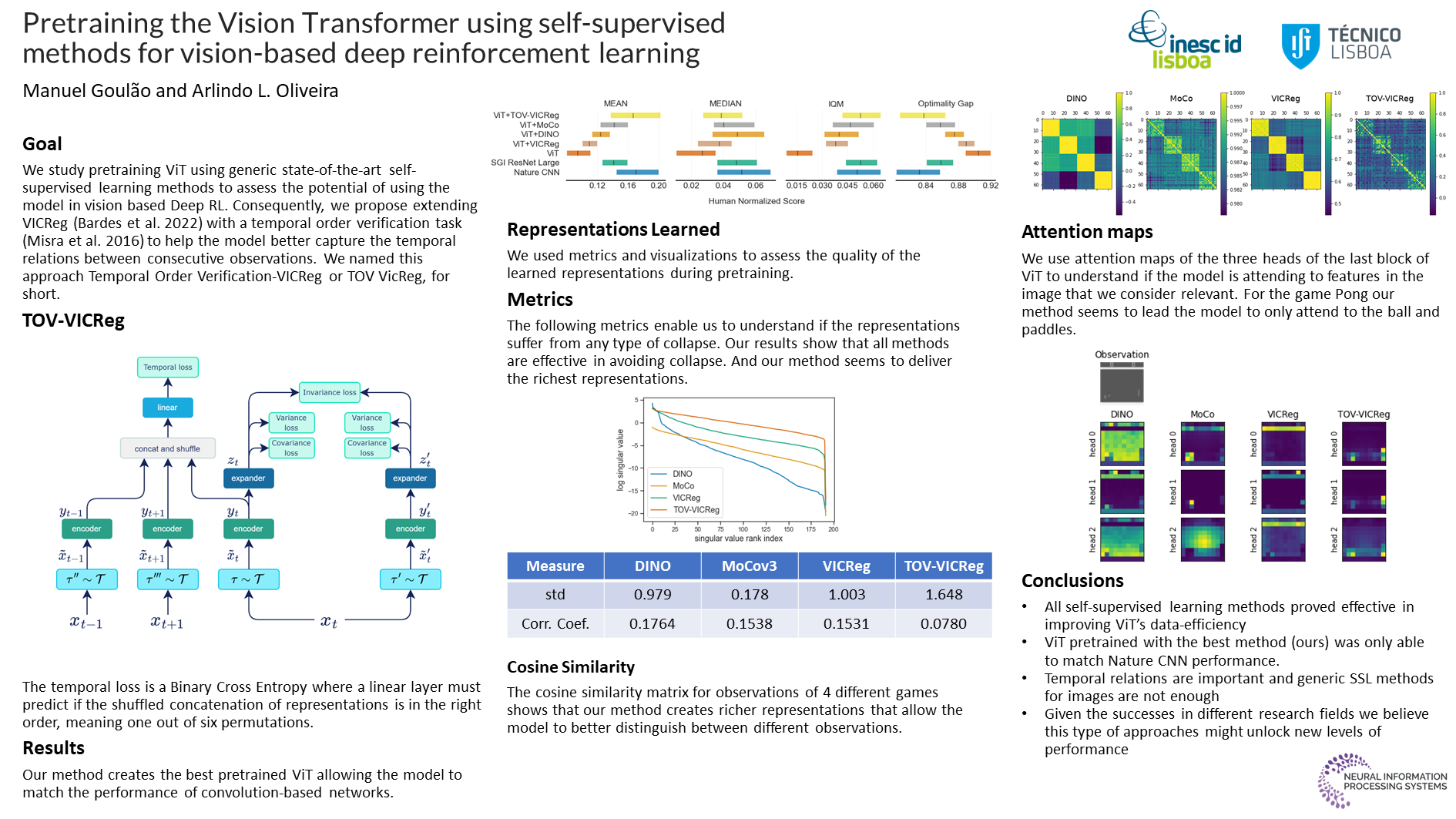{kind=link}
None
Guided Skill Learning and Abstraction for Long-Horizon Manipulation
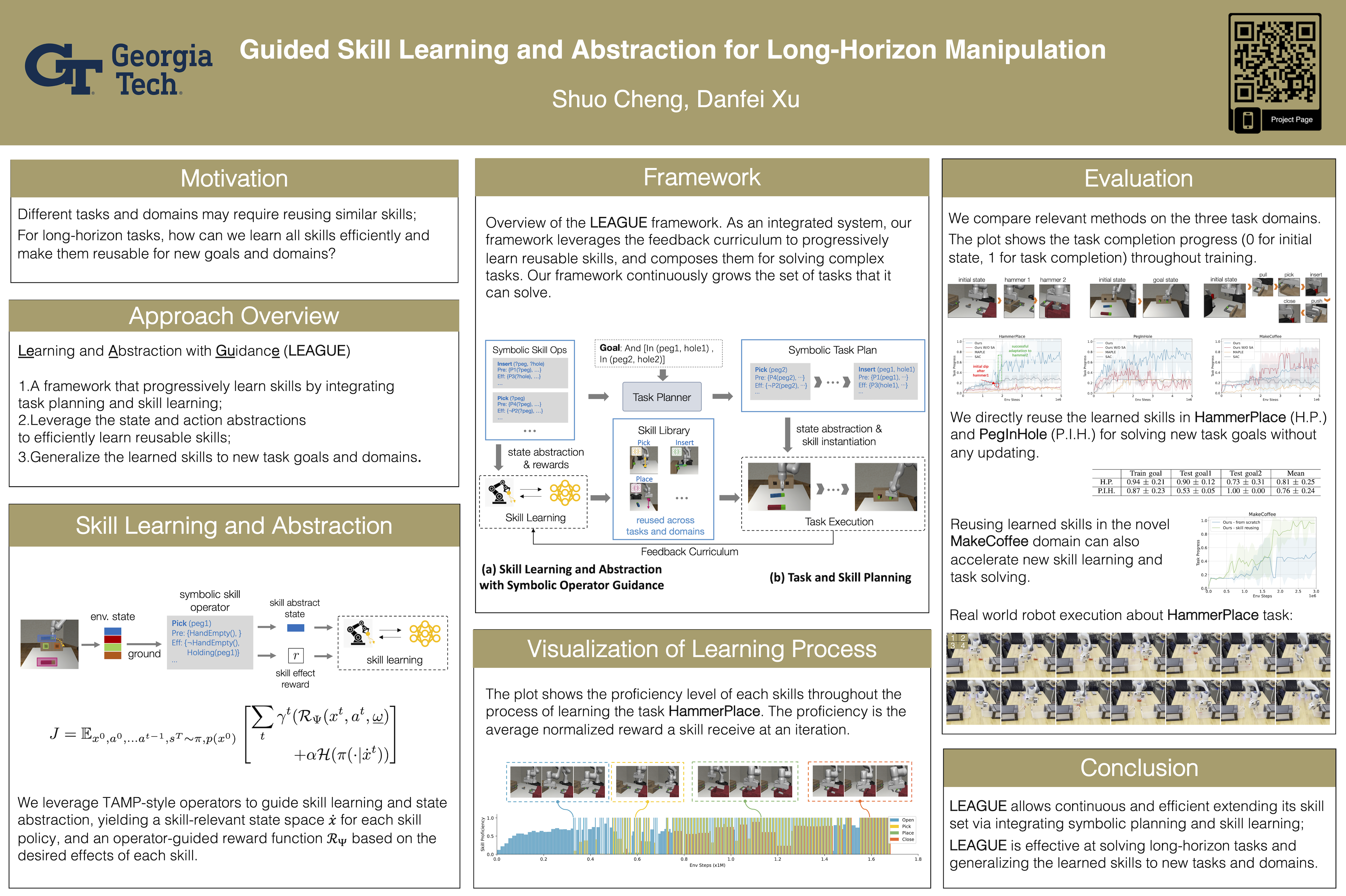{kind=link}
None
Sample-efficient Adversarial Imitation Learning
{kind=link}
None
Robust Option Learning for Adversarial Generalization
{kind=link}
None
Inducing Functions through Reinforcement Learning without Task Specification
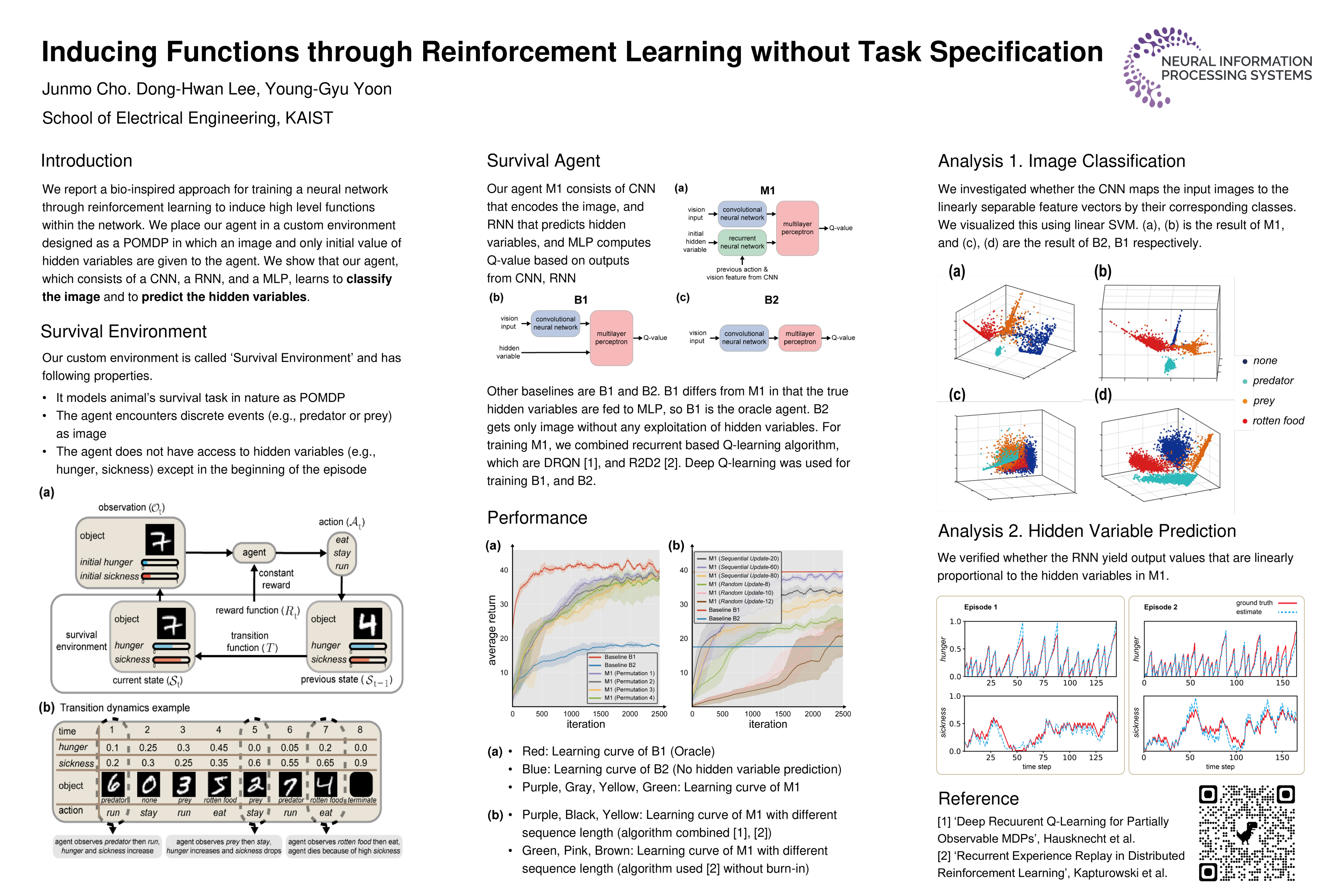{kind=link}
None
Informative rewards and generalization in curriculum learning
{kind=link}
None
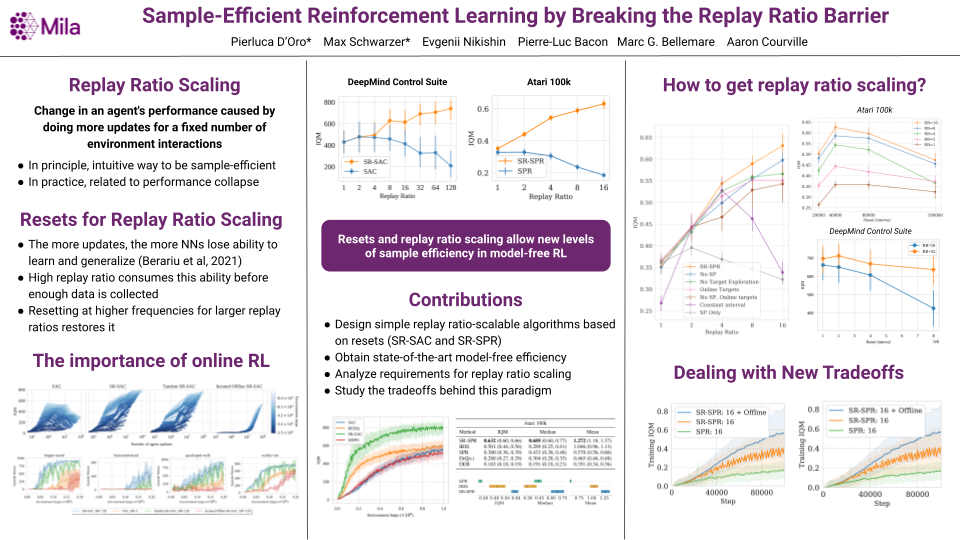
Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier
{kind=link}
None
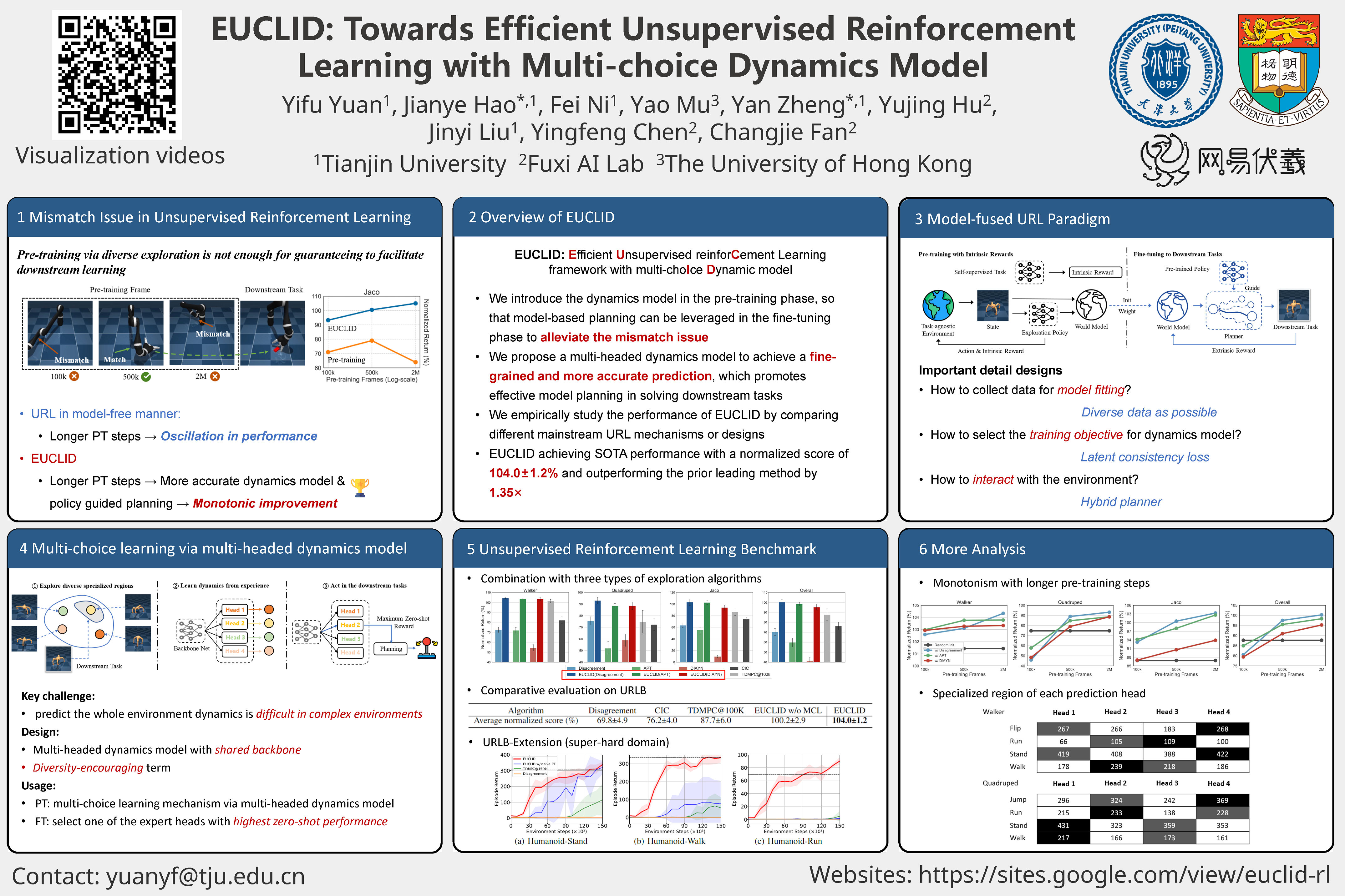
EUCLID: Towards Efficient Unsupervised Reinforcement Learning with Multi-choice Dynamics Model
{kind=link}
None
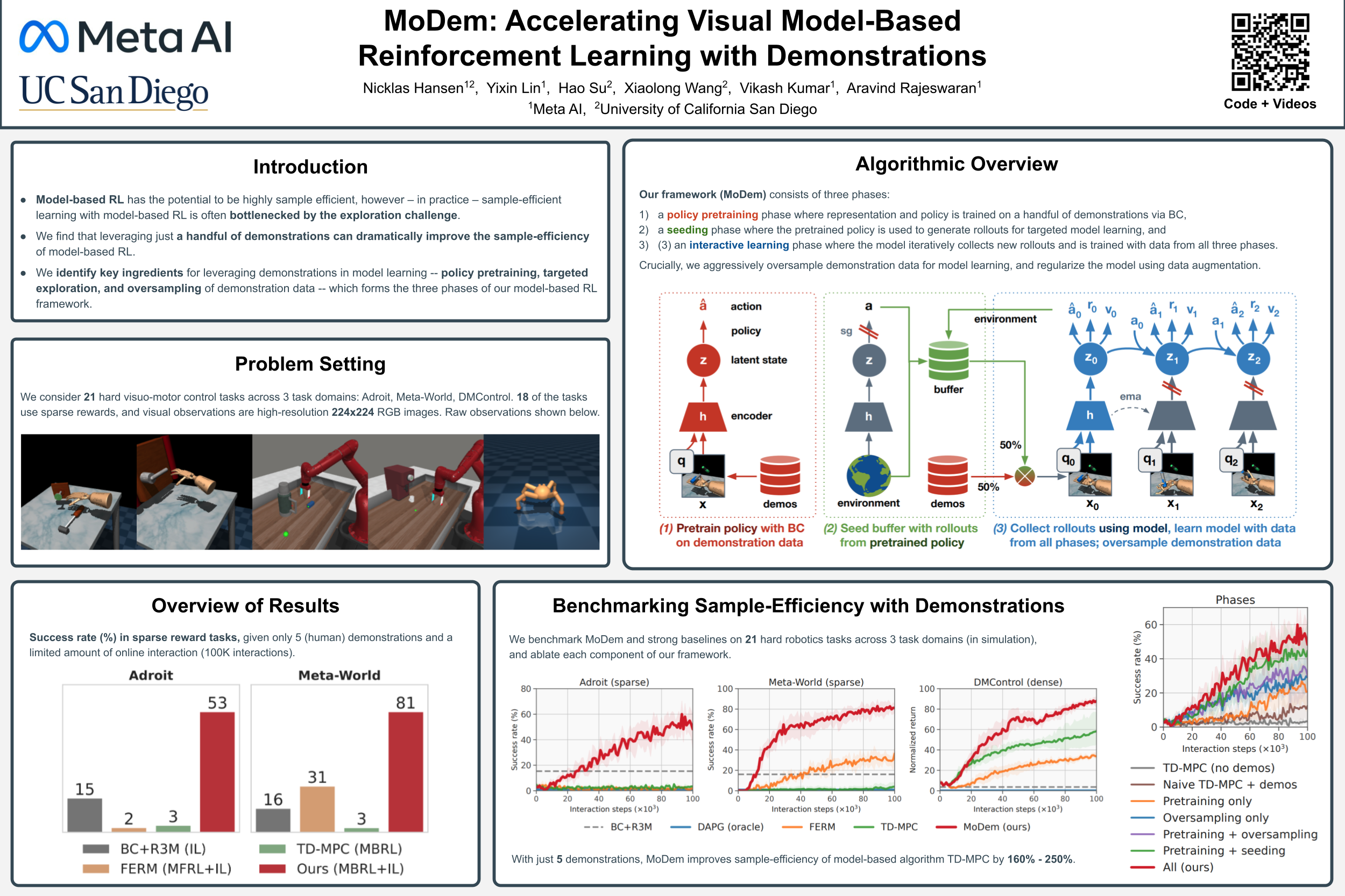
MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations
{kind=link}
None
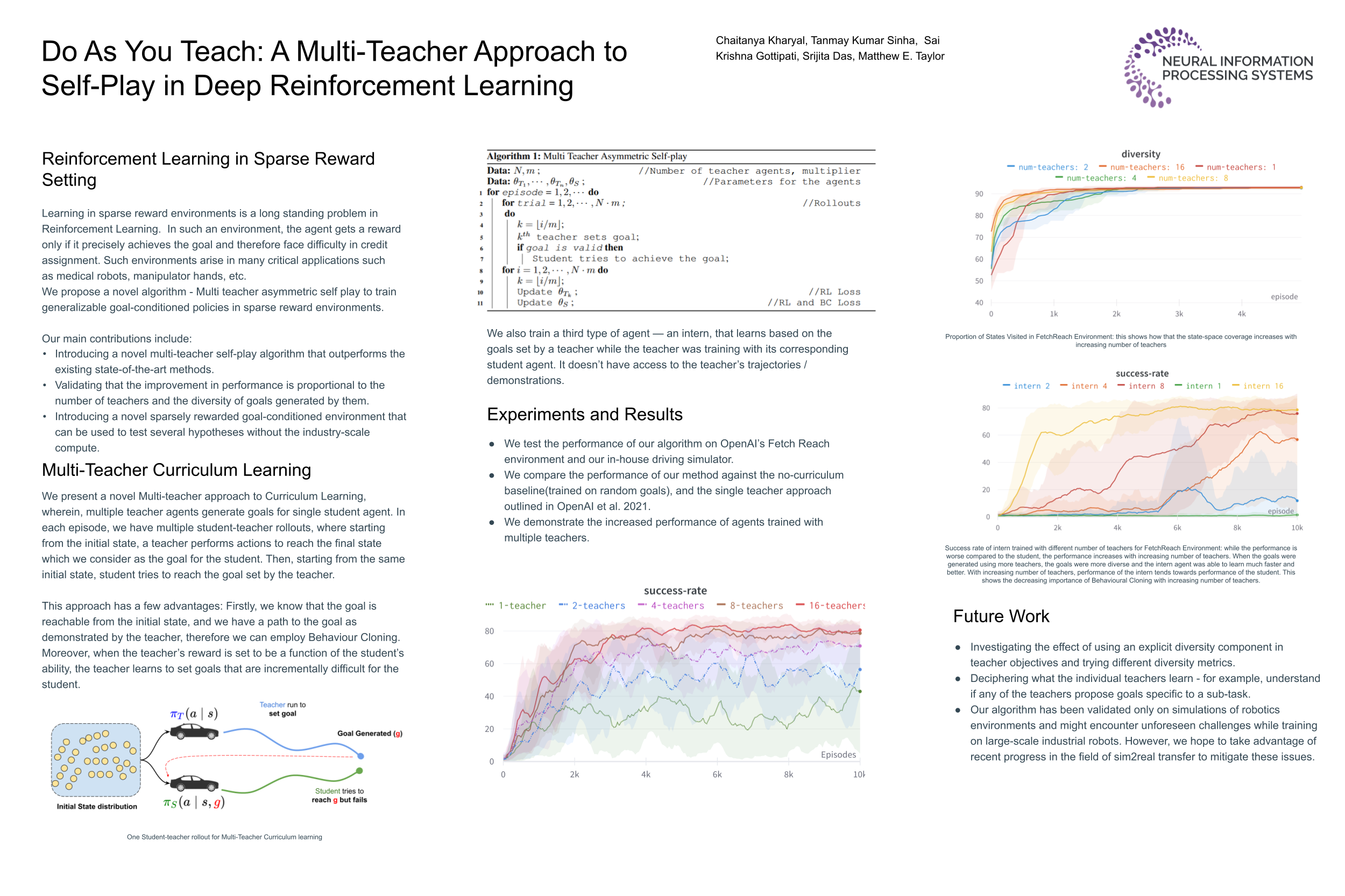
Do As You Teach: A Multi-Teacher Approach to Self-Play in Deep Reinforcement Learning
{kind=link}
None
Visual Reinforcement Learning with Self-Supervised 3D Representations
{kind=link}
None
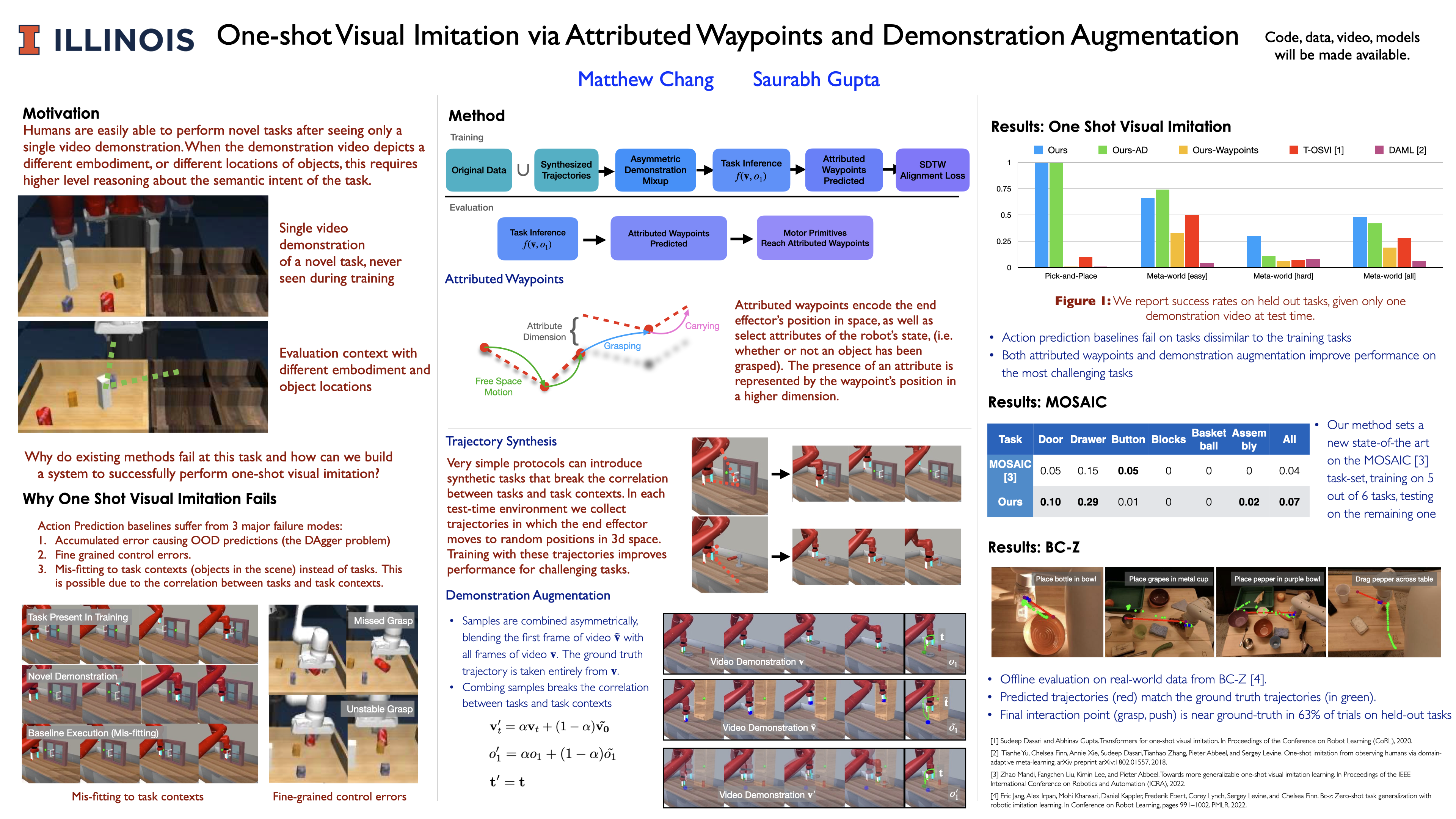
One-shot Visual Imitation via Attributed Waypoints and Demonstration Augmentation
{kind=link}
None
Skill Machines: Temporal Logic Composition in Reinforcement Learning
{kind=link}
None
Deep Learning of Intrinsically Motivated Options in the Arcade Learning Environment
{kind=link}
None
Policy Architectures for Compositional Generalization in Control
{kind=link}
None
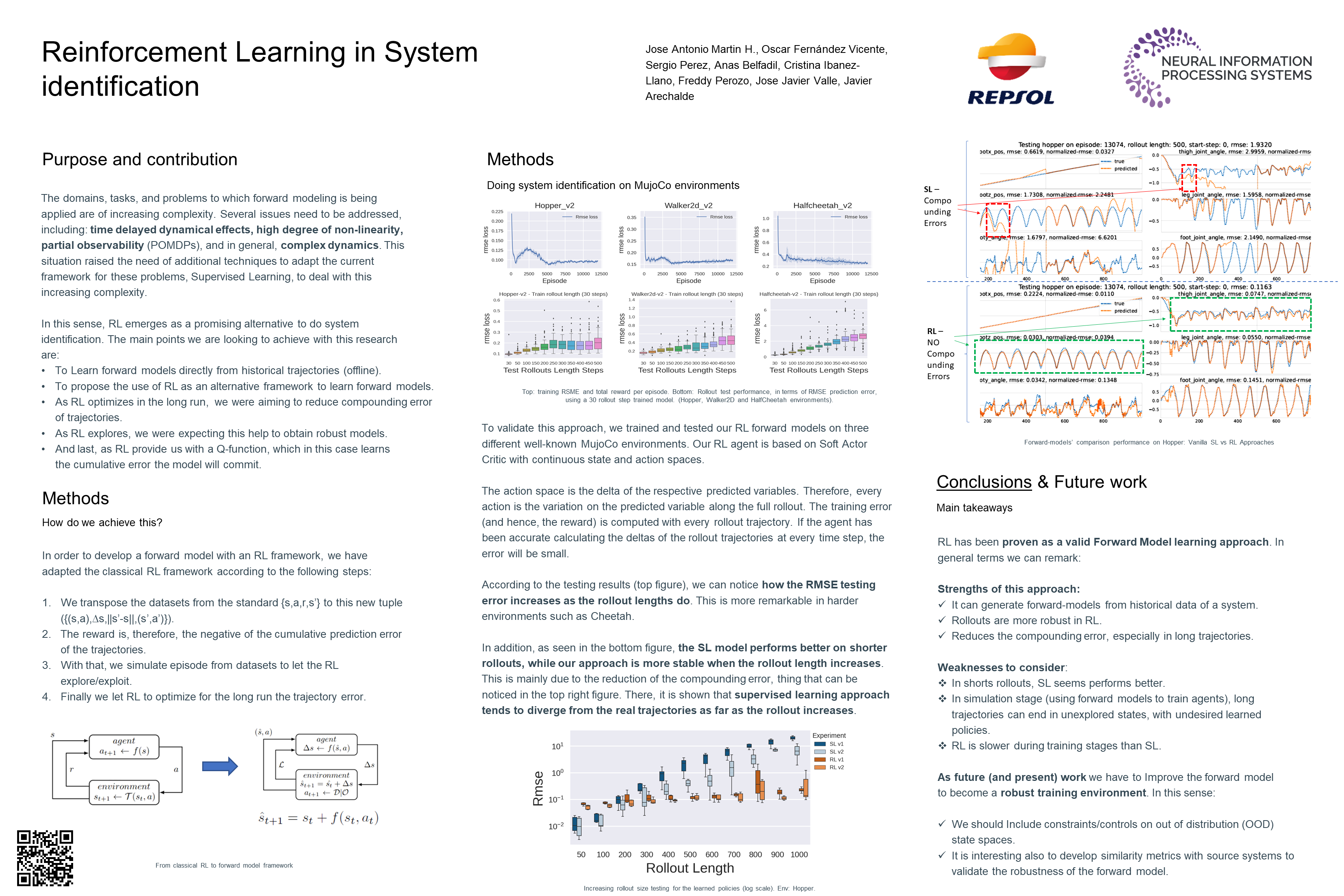
Reinforcement Learning in System Identification
{kind=link}
None
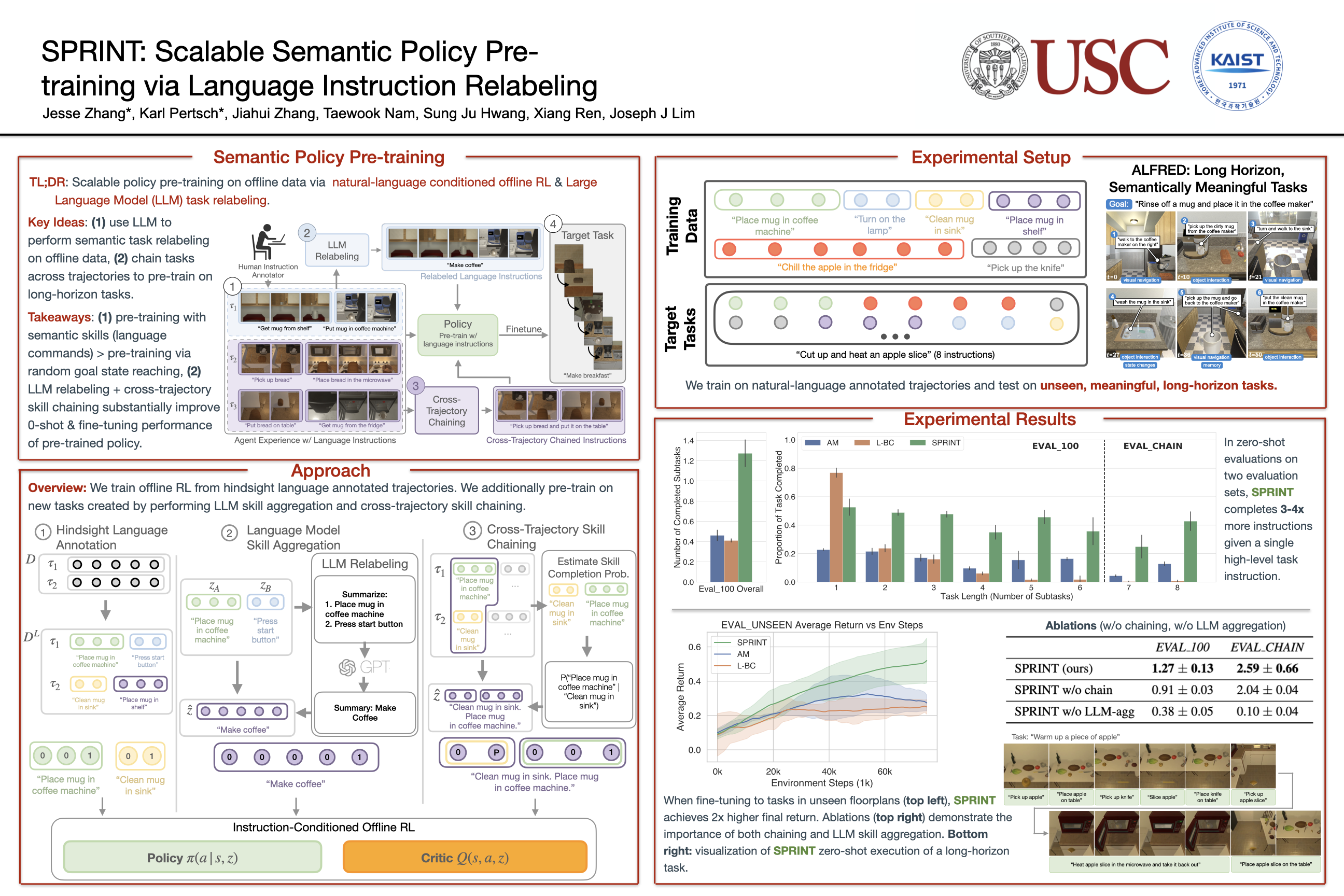
SPRINT: Scalable Semantic Policy Pre-training via Language Instruction Relabeling
{kind=link}
None
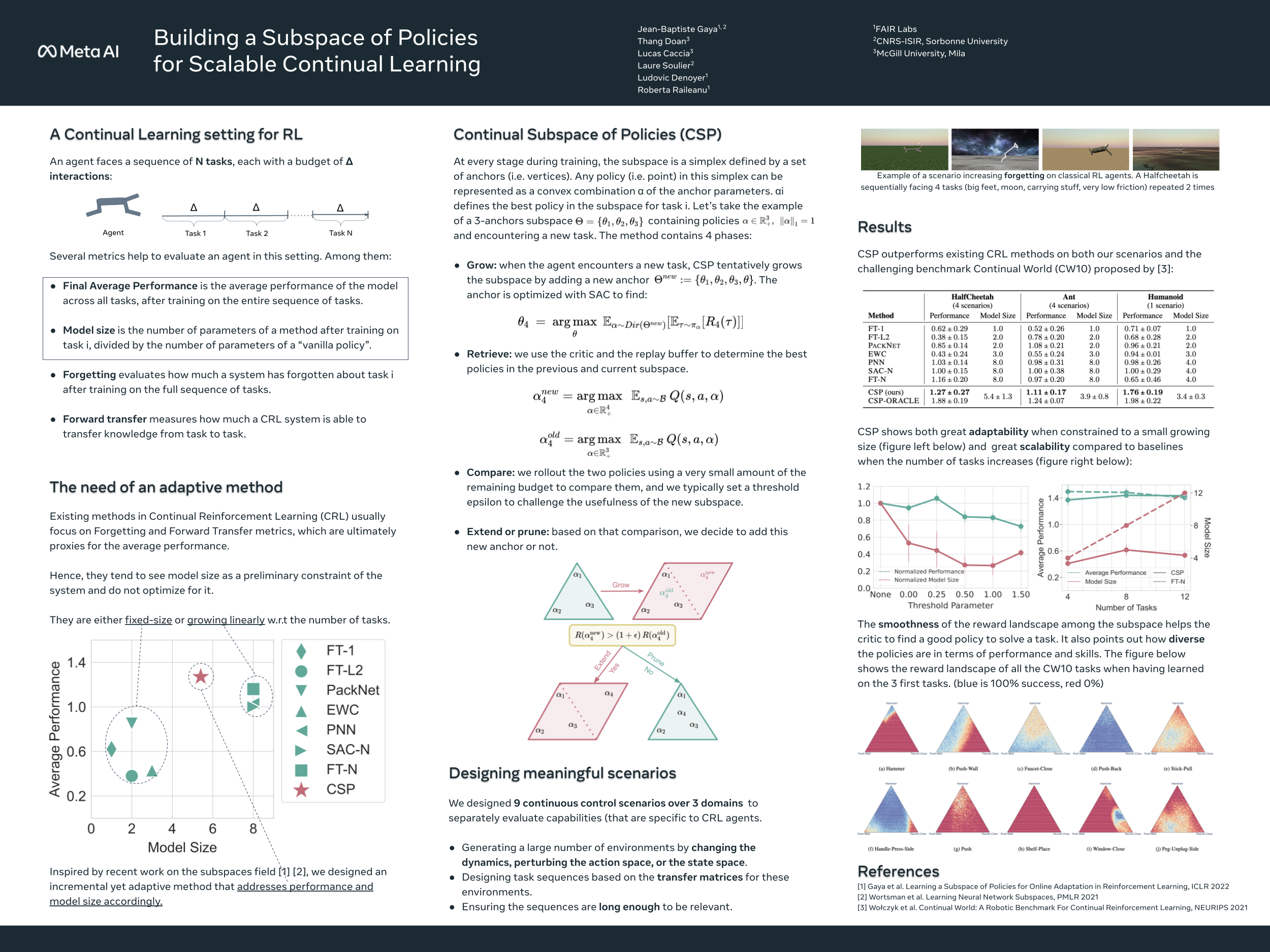
Building a Subspace of Policies for Scalable Continual Learning
{kind=link}
None
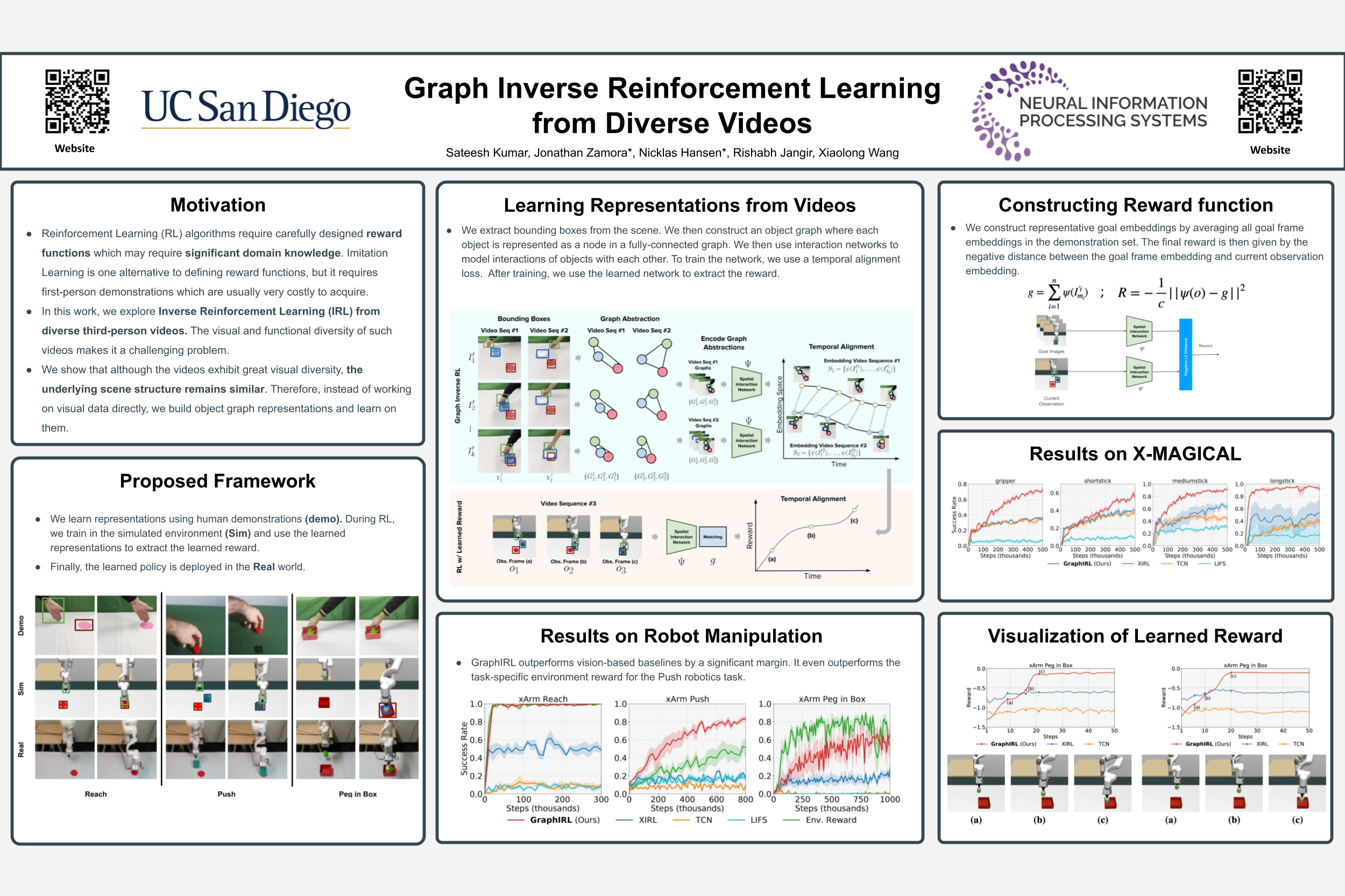
Graph Inverse Reinforcement Learning from Diverse Videos
{kind=link}
None
PnP-Nav: Plug-and-Play Policies for Generalizable Visual Navigation Across Robots
{kind=link}
None
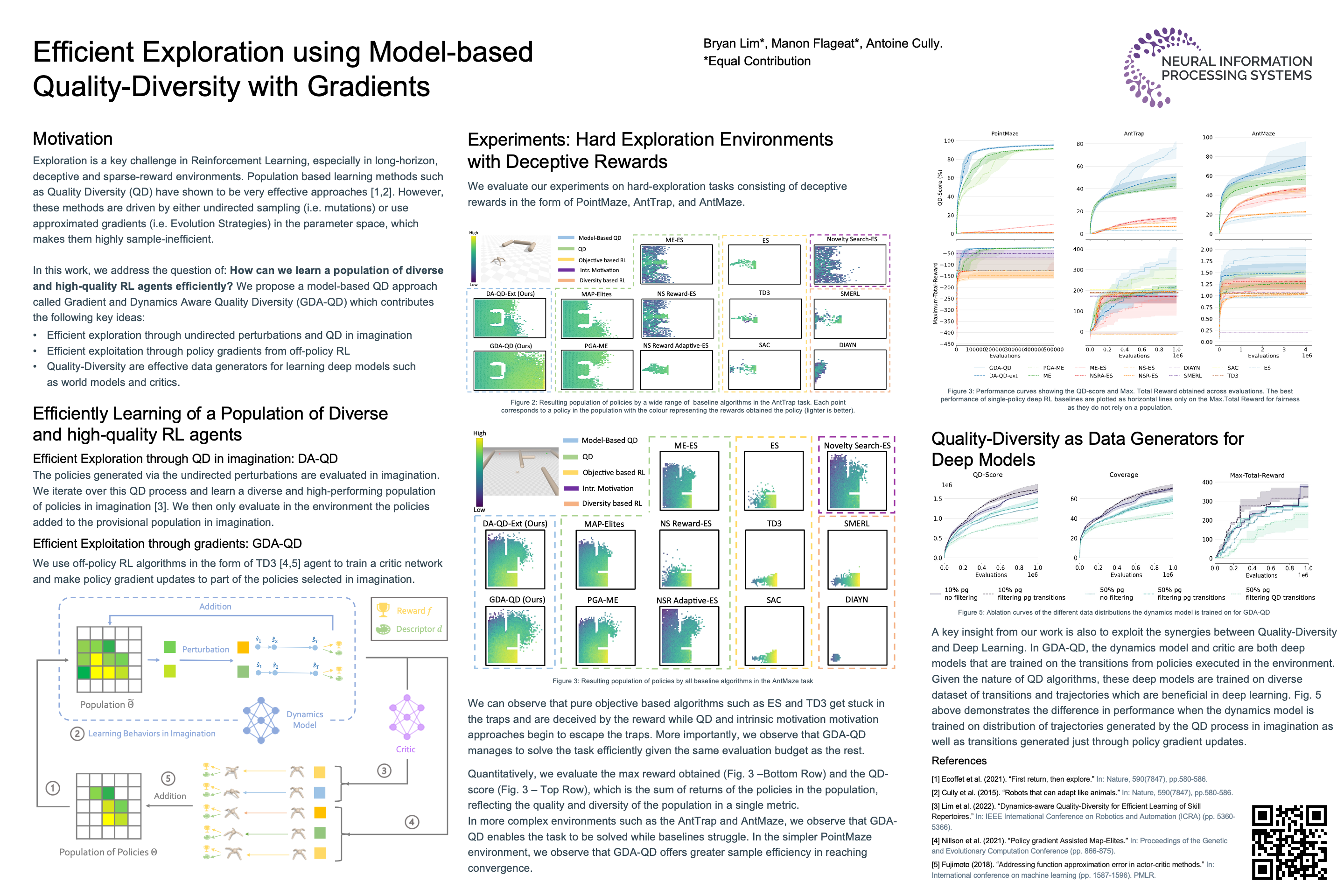
Efficient Exploration using Model-Based Quality-Diversity with Gradients
{kind=link}
None
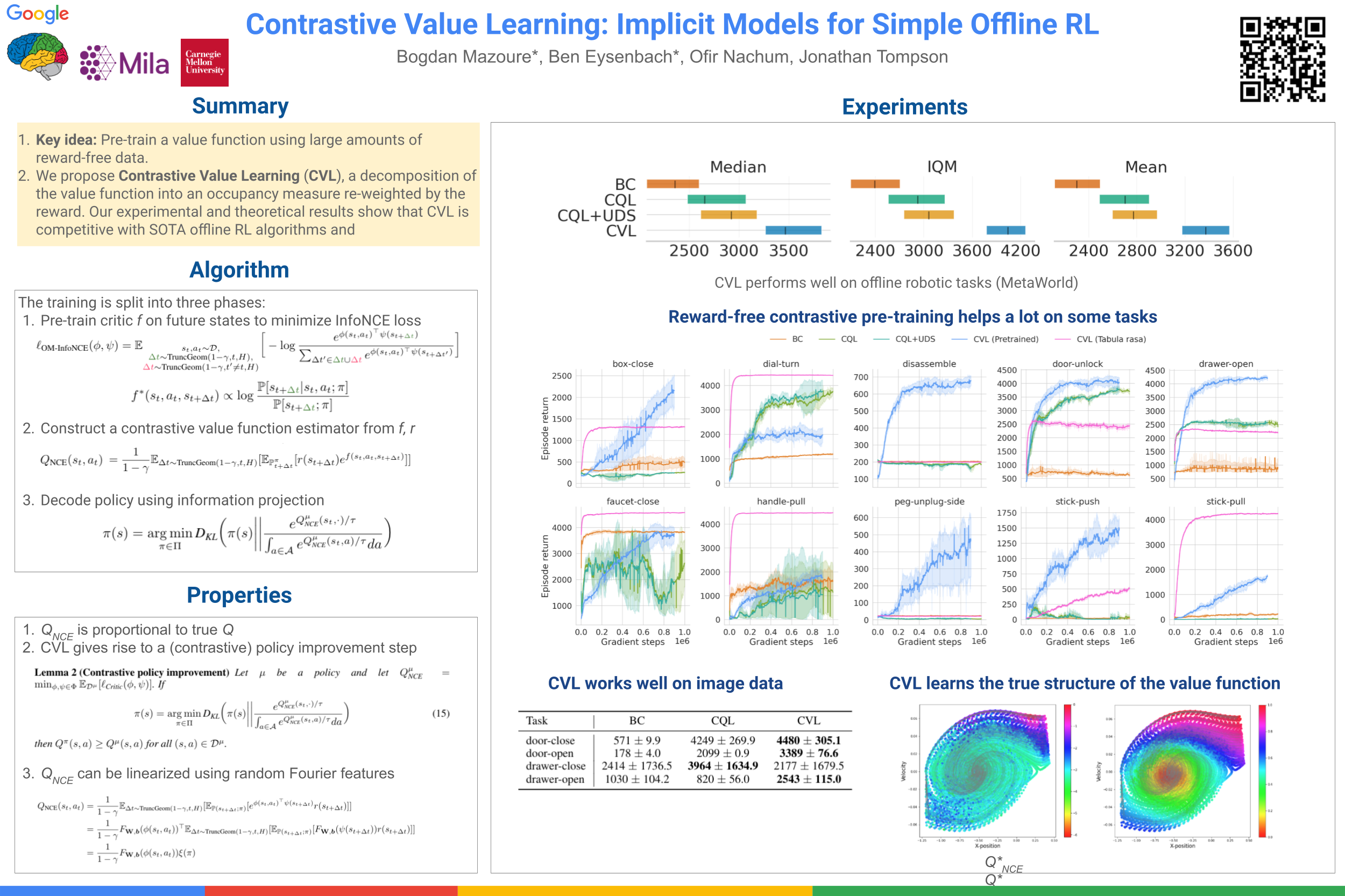
Contrastive Value Learning: Implicit Models for Simple Offline RL
{kind=link}
None
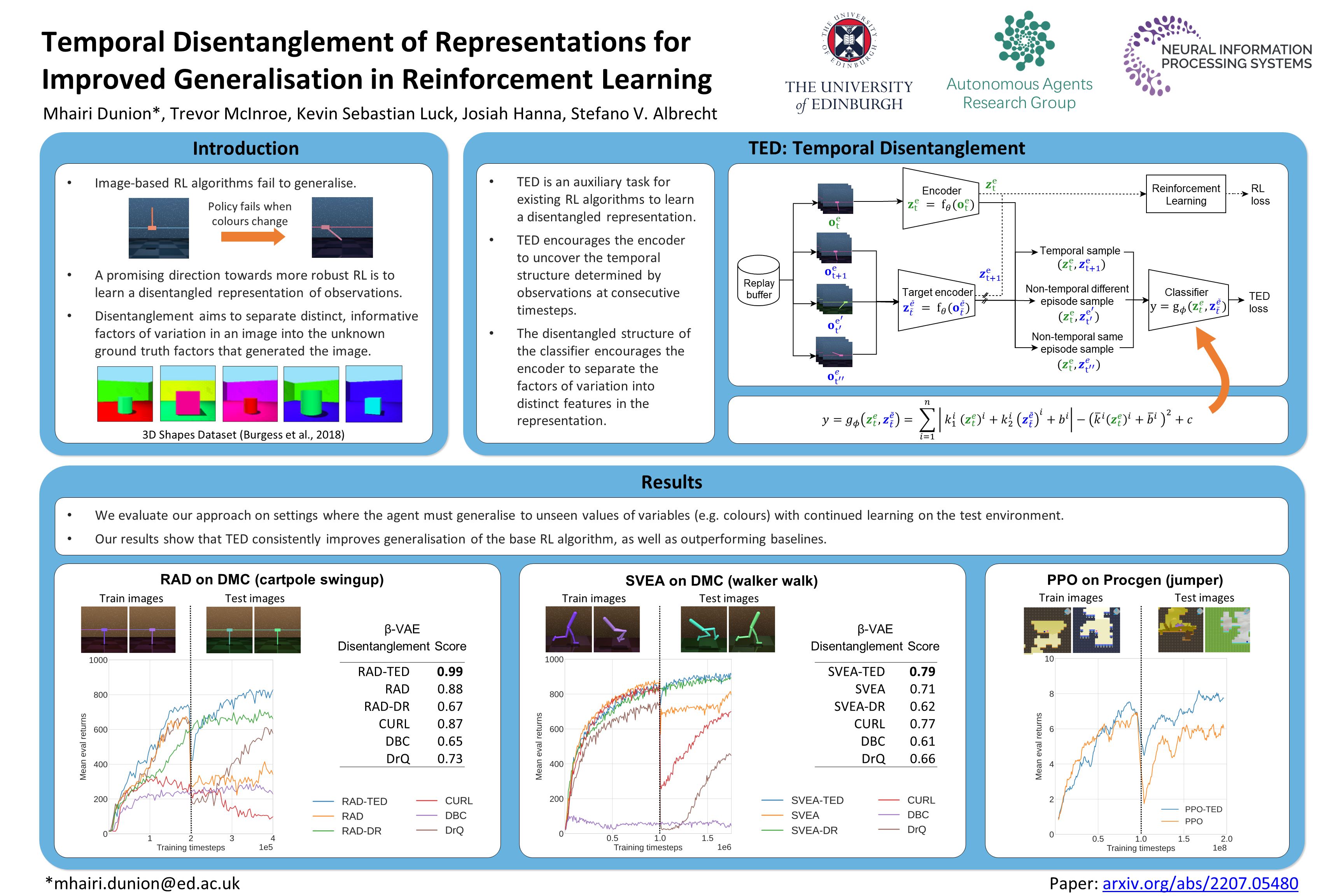
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
{kind=link}
None
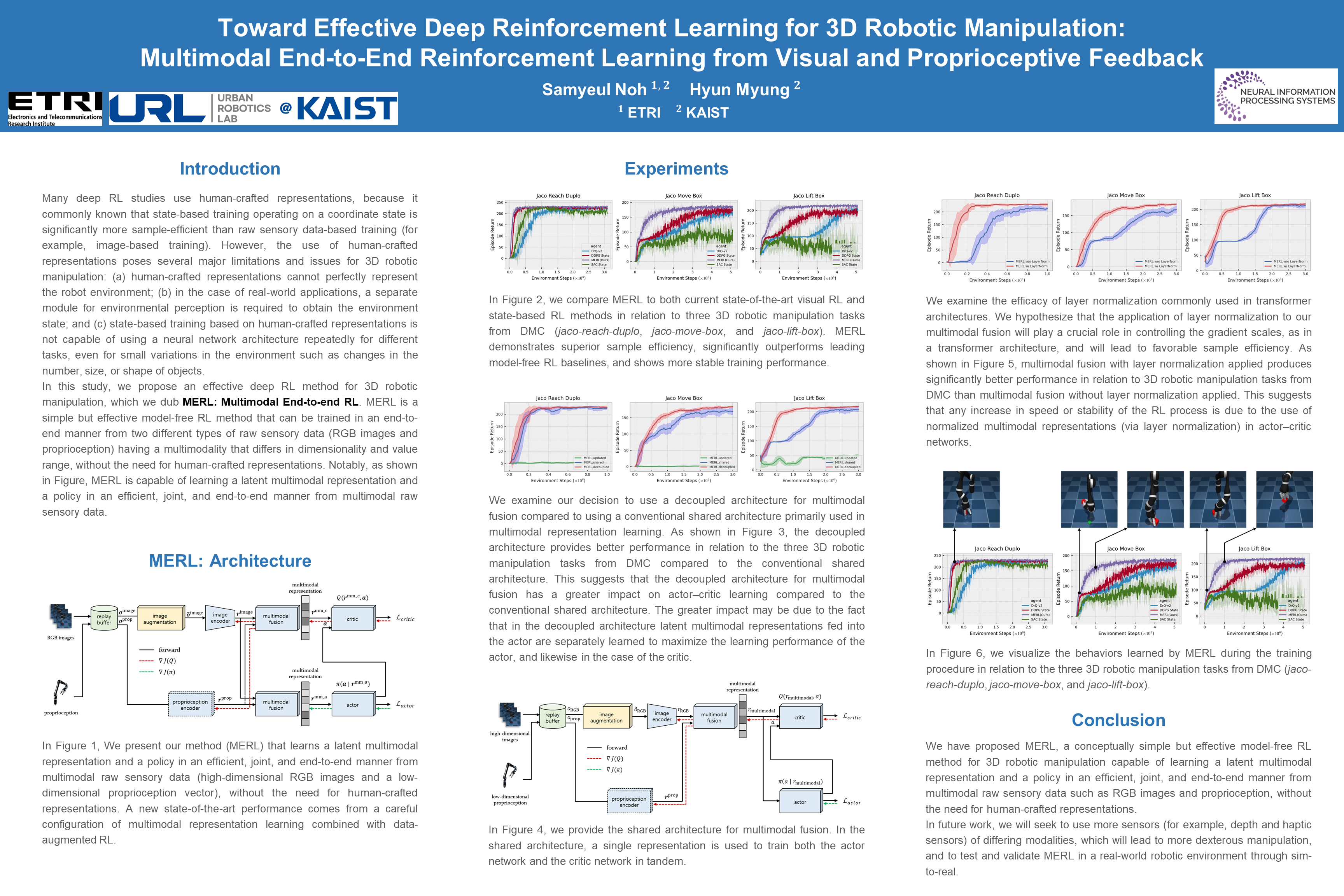
Toward Effective Deep Reinforcement Learning for 3D Robotic Manipulation: End-to-End Learning from Multimodal Raw Sensory Data
{kind=link}
None
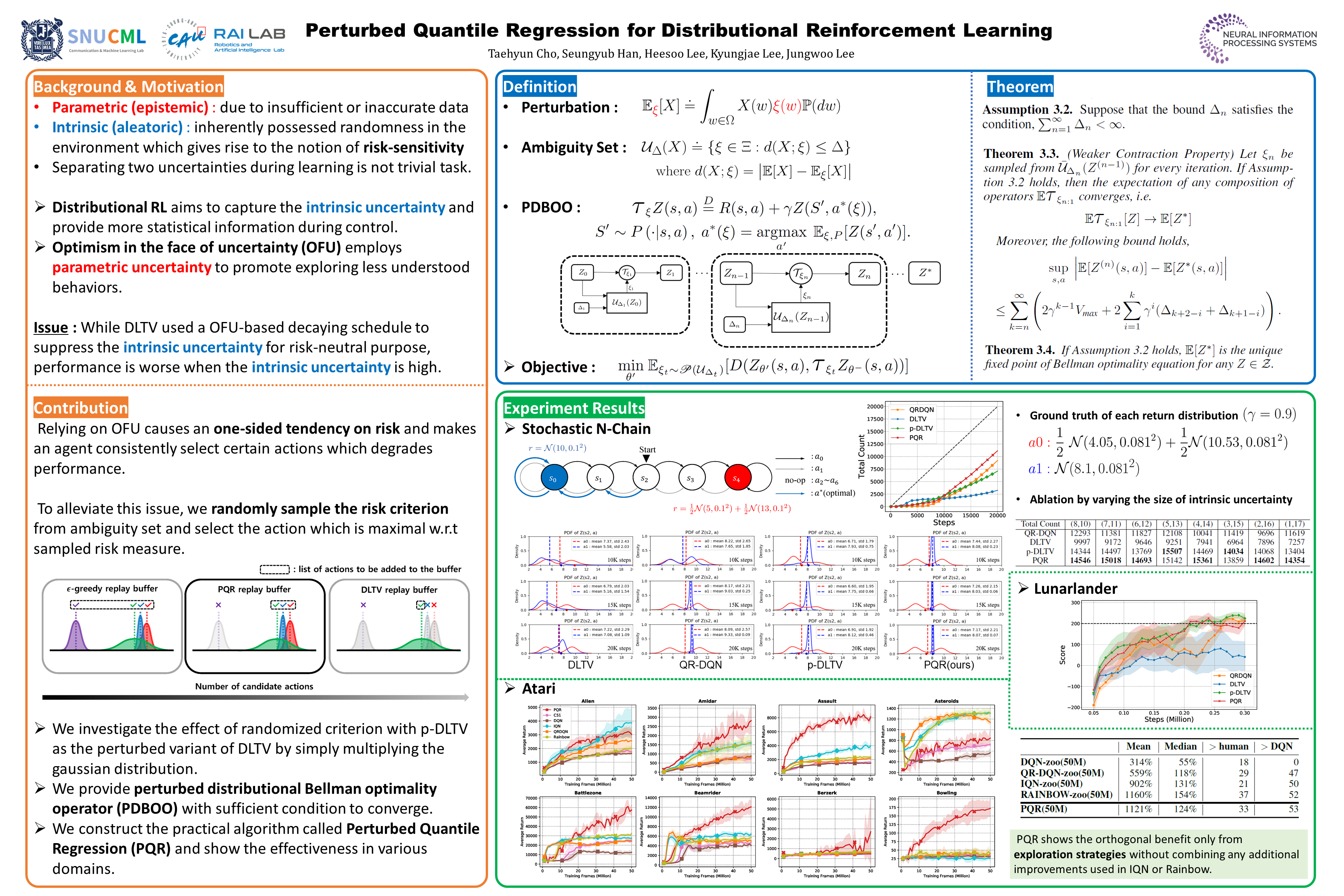
Perturbed Quantile Regression for Distributional Reinforcement Learning
{kind=link}
None
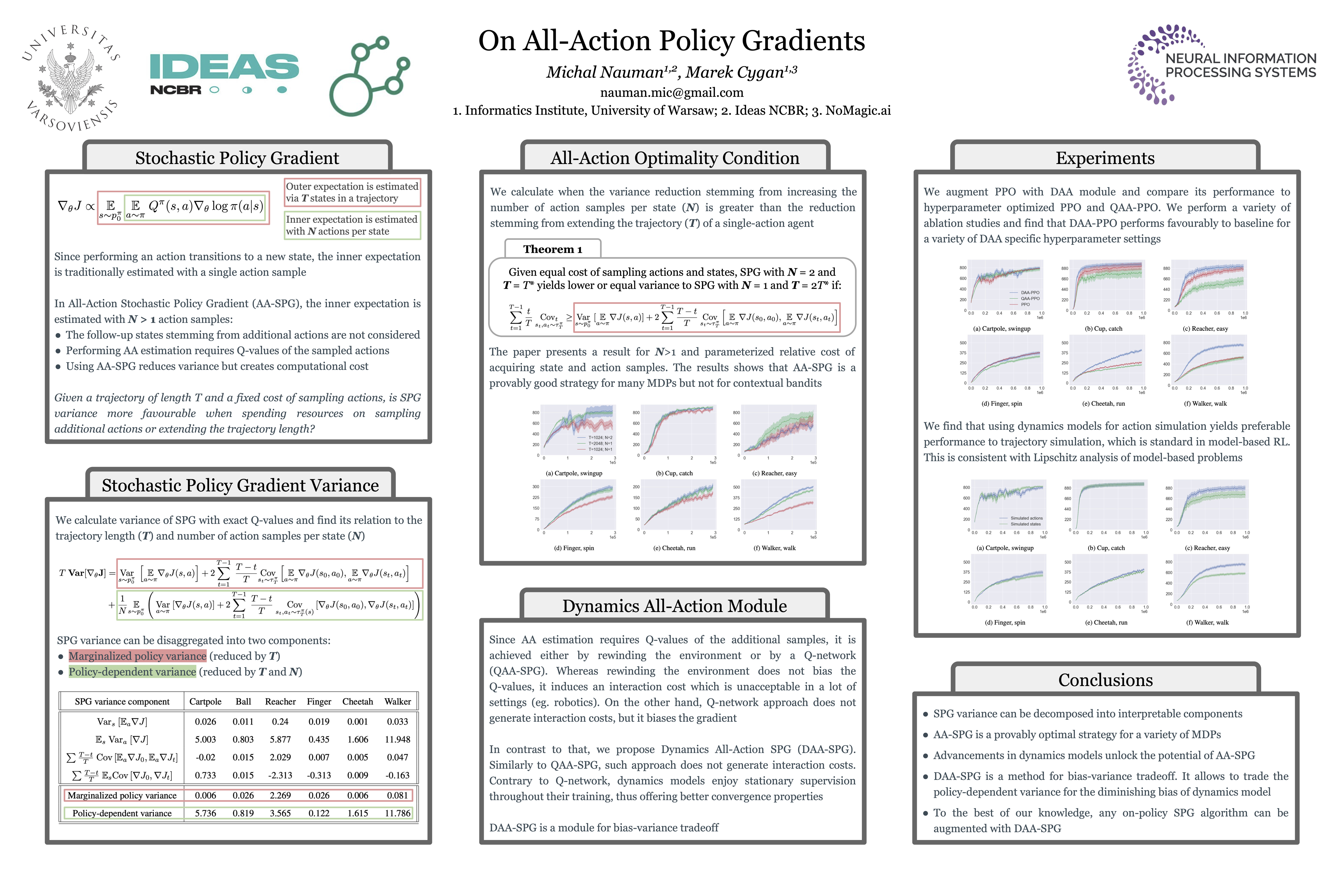
On All-Action Policy Gradients
{kind=link}
None
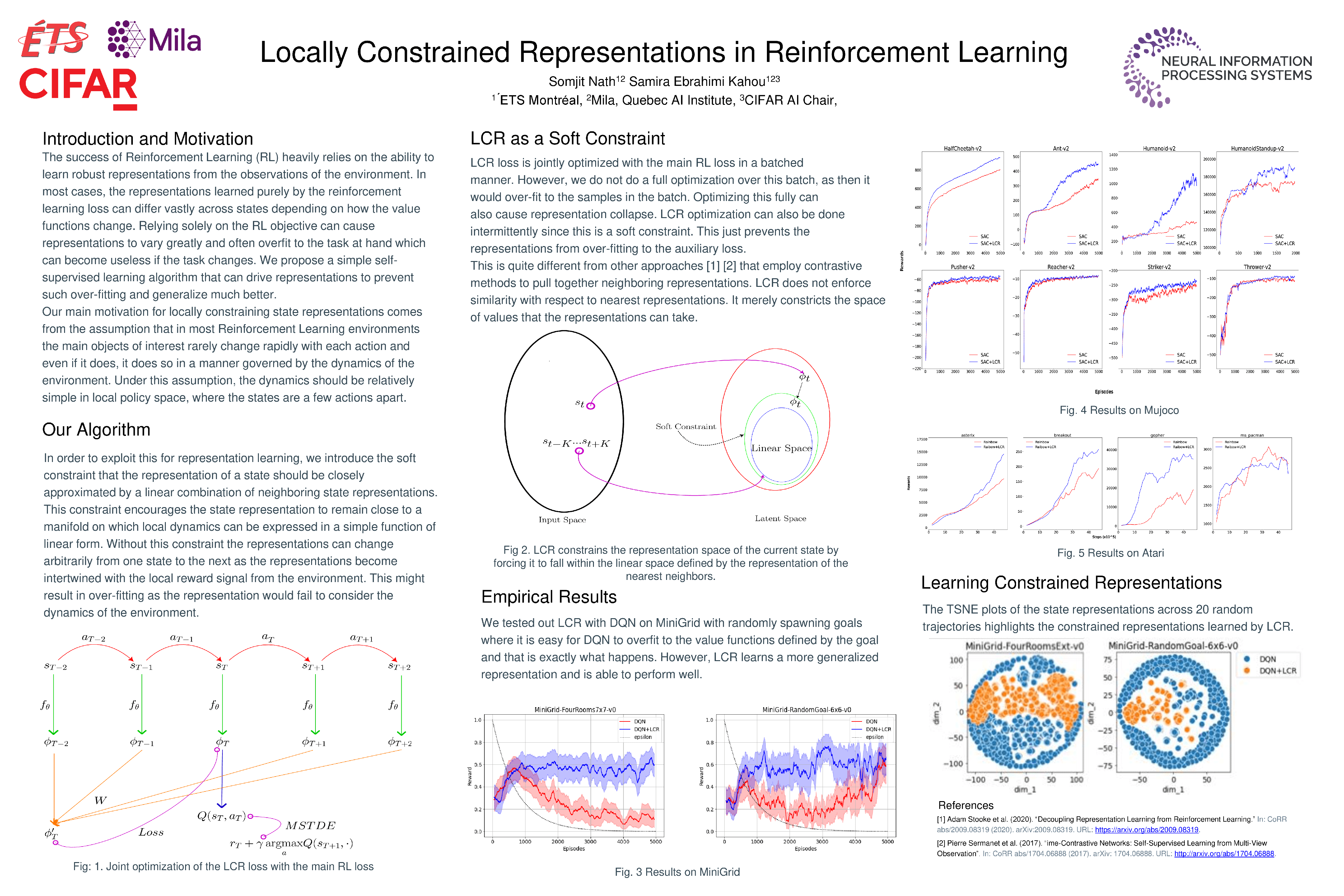
Locally Constrained Representations in Reinforcement Learning
{kind=link}
None
VI2N: A Network for Planning Under Uncertainty based on Value of Information
{kind=link}
None
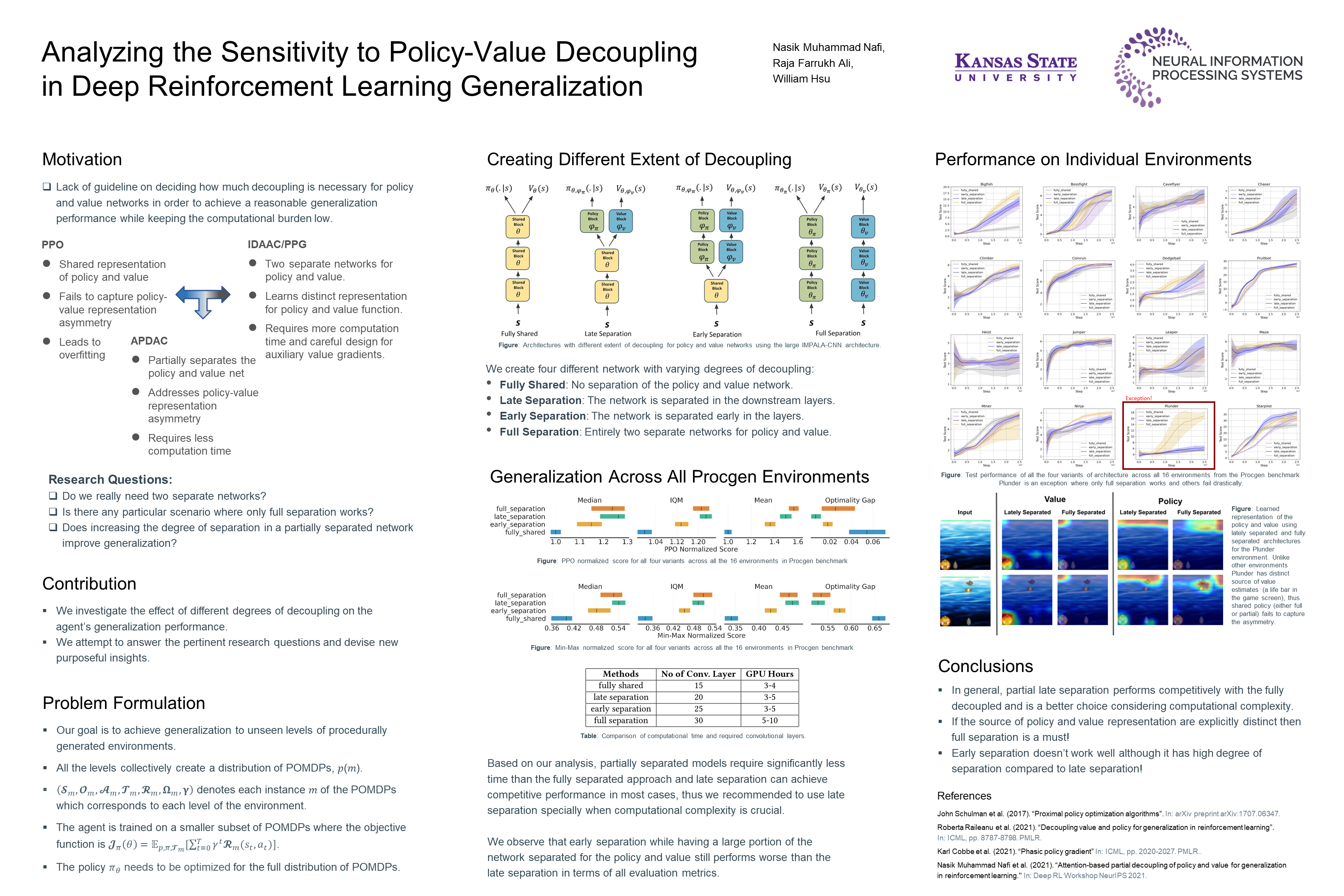
Analyzing the Sensitivity to Policy-Value Decoupling in Deep Reinforcement Learning Generalization
{kind=link}
None
Lagrangian Model Based Reinforcement Learning
{kind=link}
None
Towards A Unified Policy Abstraction Theory and Representation Learning Approach in Markov Decision Processes
{kind=link}
None
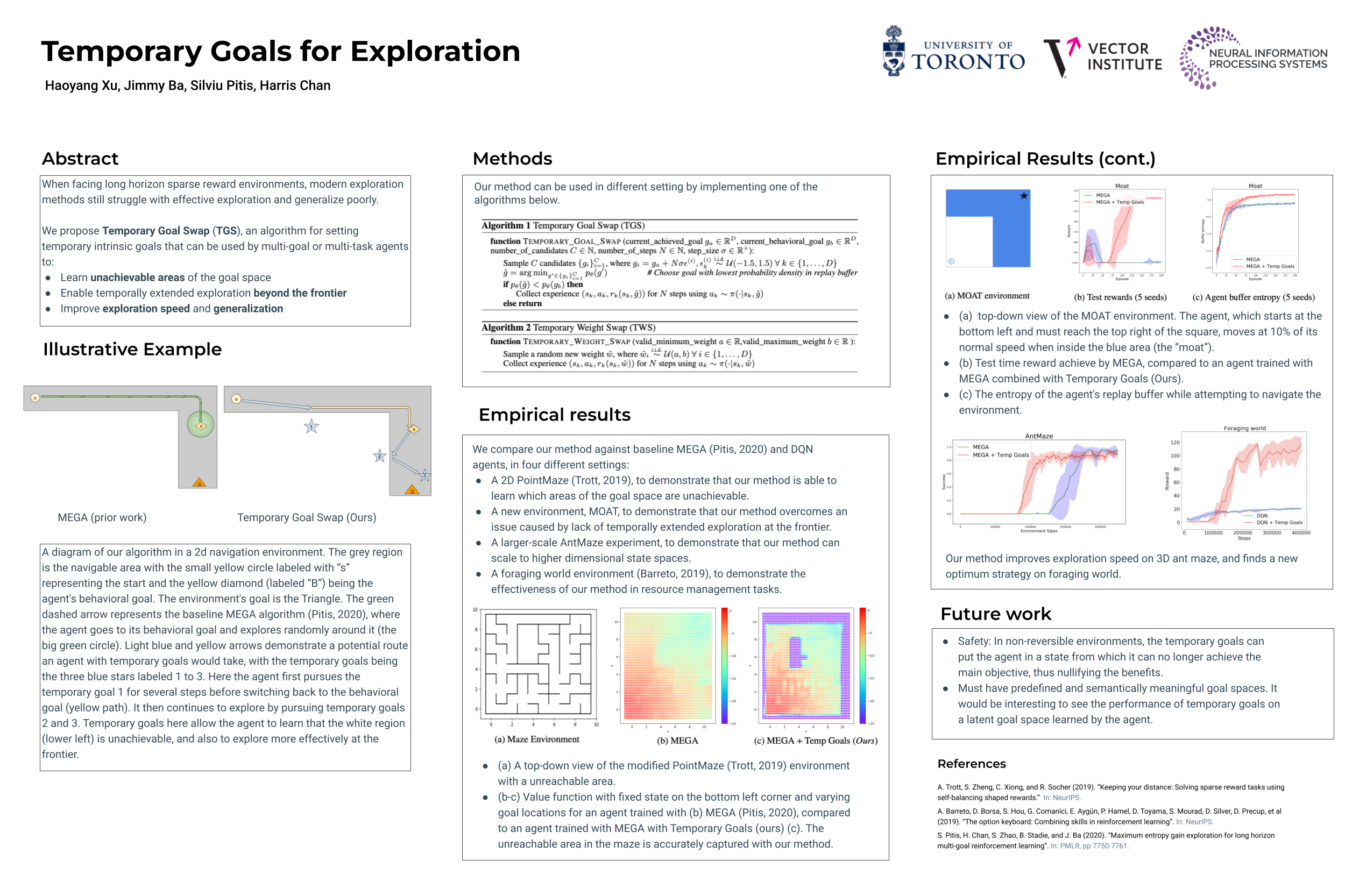
Temporary Goals for Exploration
{kind=link}
None
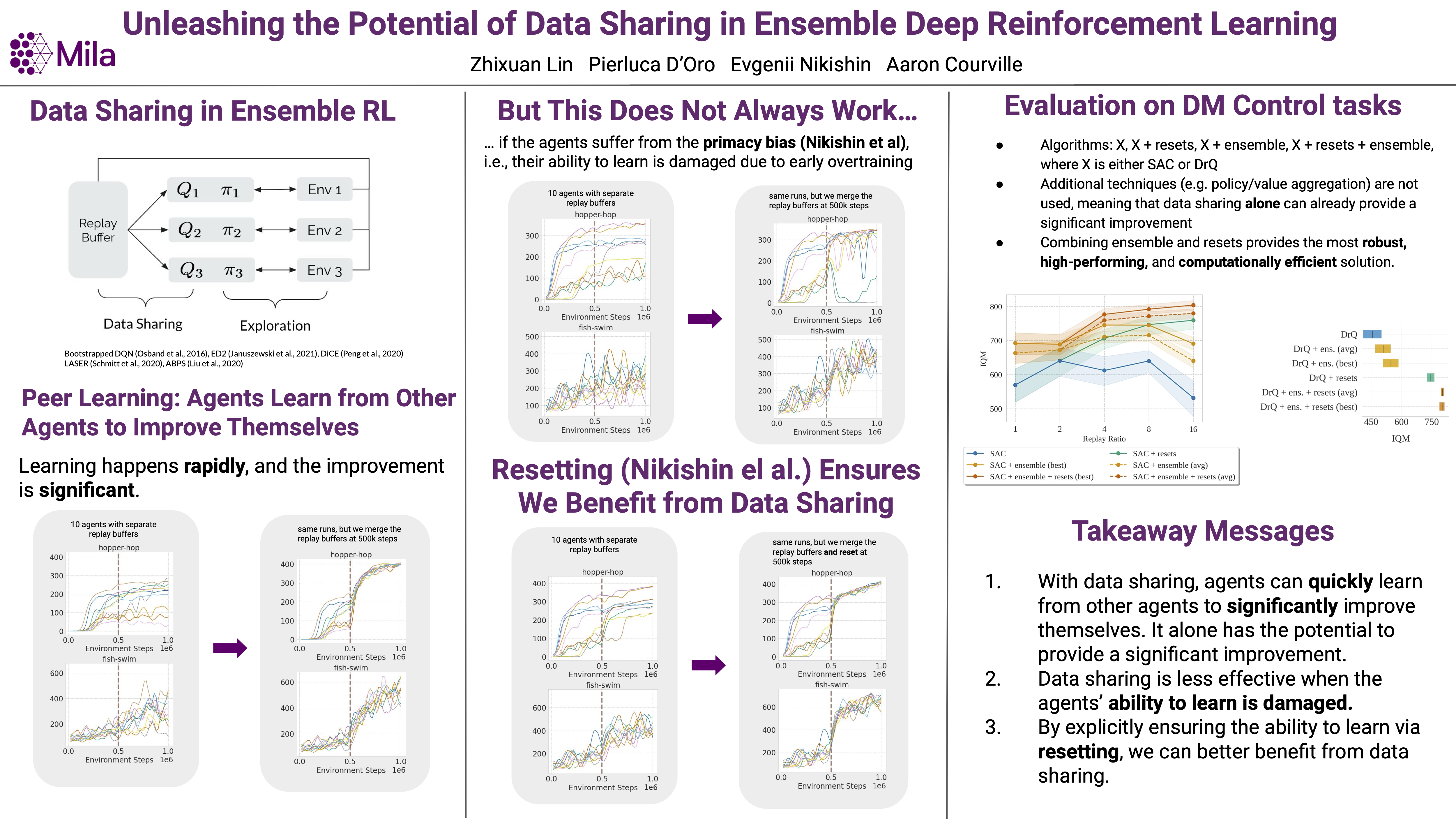
Unleashing The Potential of Data Sharing in Ensemble Deep Reinforcement Learning
{kind=link}
None
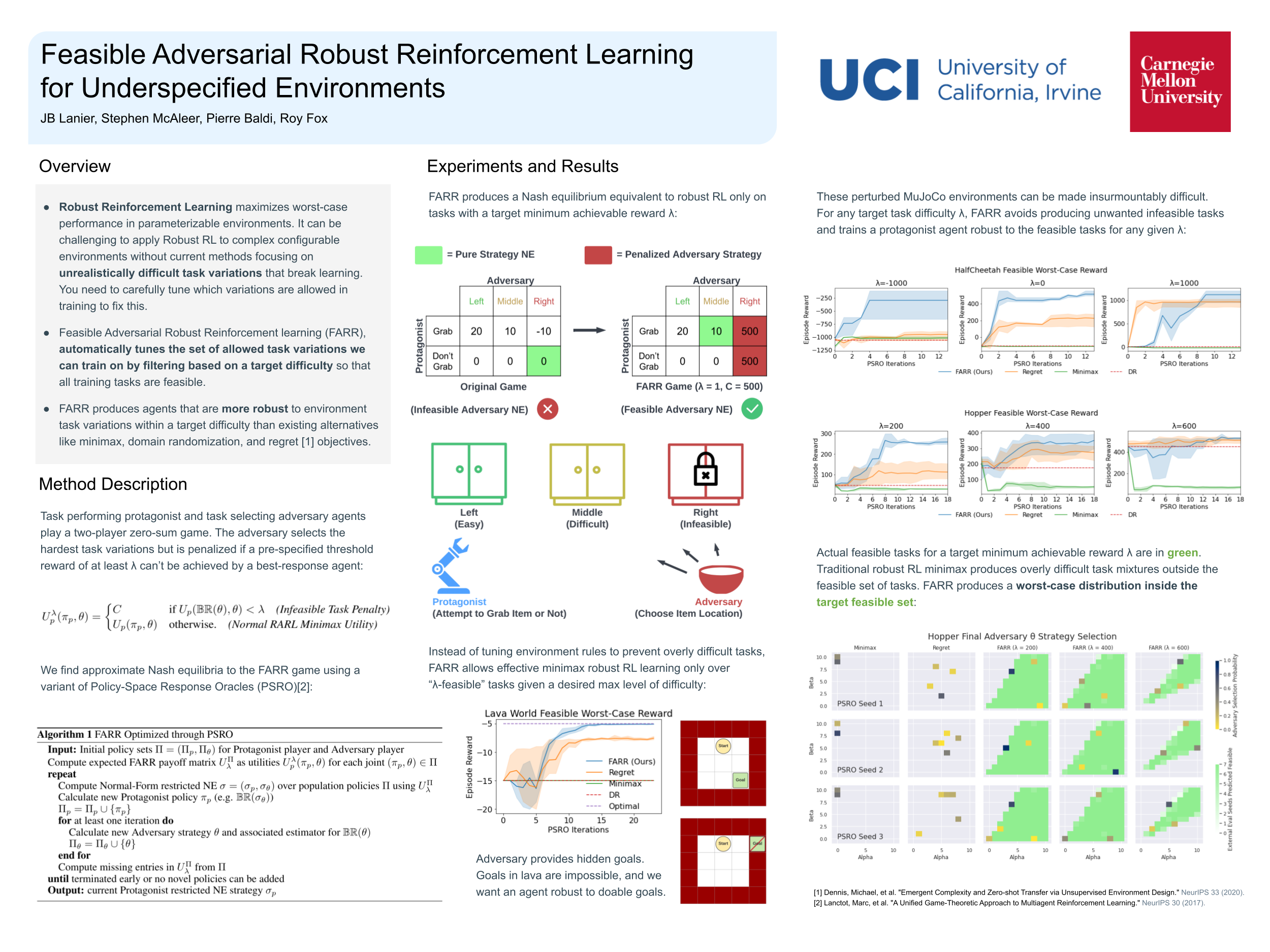
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
{kind=link}
None
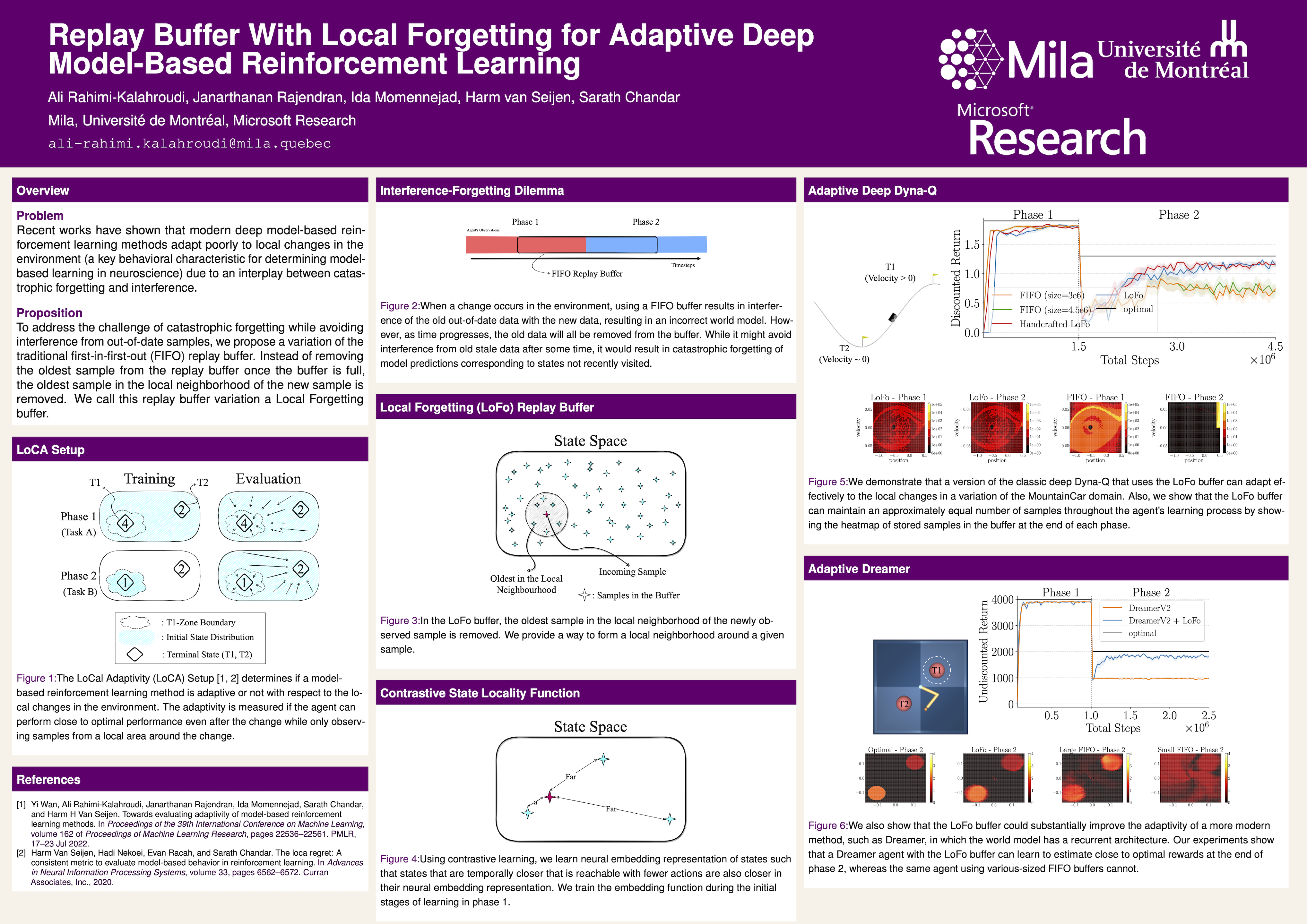
Replay Buffer With Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning
{kind=link}
None
ABC: Adversarial Behavioral Cloning for Offline Mode-Seeking Imitation Learning
{kind=link}
None
In the ZONE: Measuring difficulty and progression in curriculum generation
{kind=link}
None
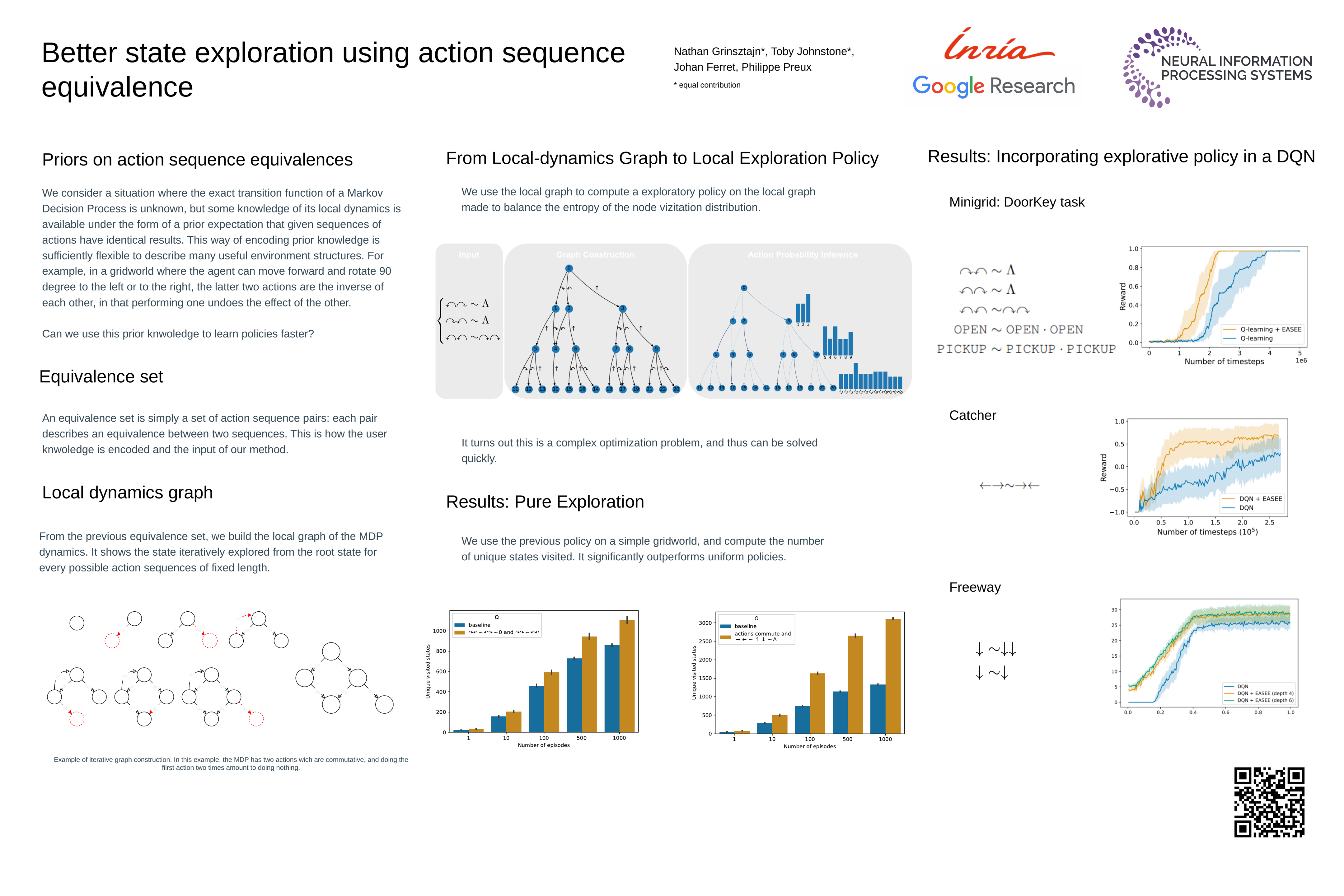
Better state exploration using action sequence equivalence
{kind=link}
None
ERL-Re$^2$: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation
{kind=link}
None
Abstract-to-Executable Trajectory Translation for One-Shot Task Generalization
{kind=link}
None
Fine-tuning Offline Policies with Optimistic Action Selection
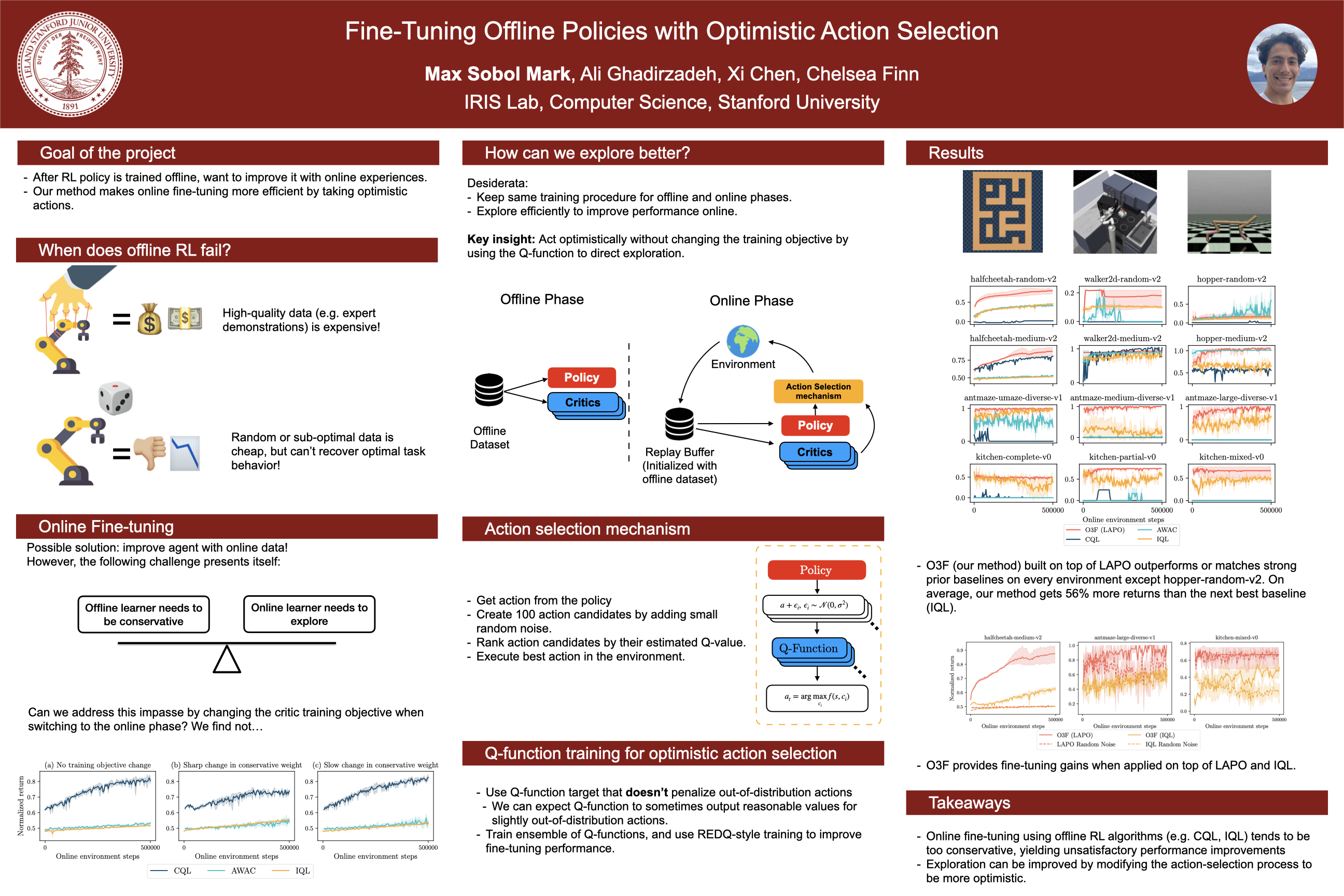{kind=link}
None
Adversarial Policies Beat Professional-Level Go AIs
{kind=link}
None
The Emphatic Approach to Average-Reward Policy Evaluation
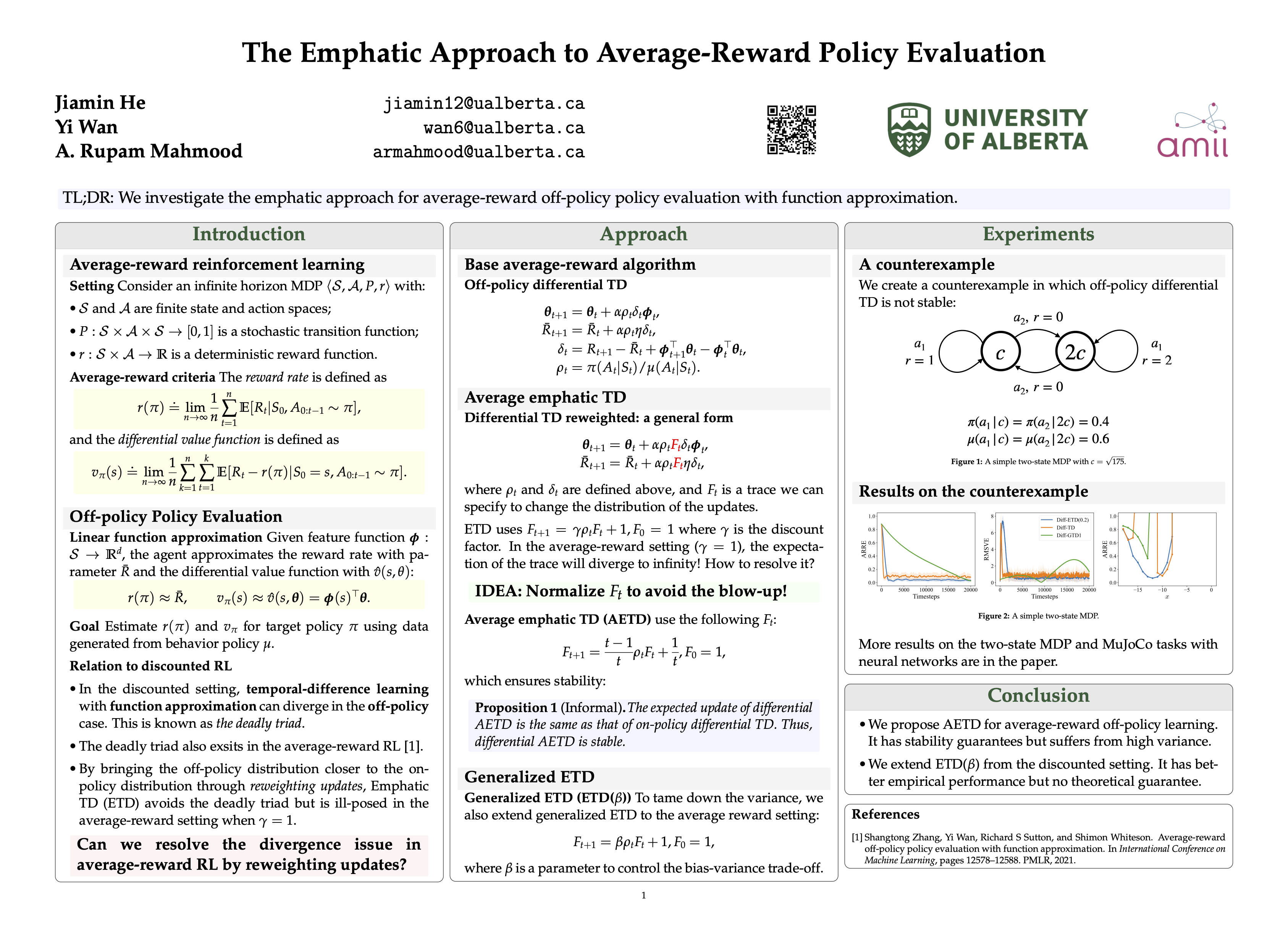{kind=link}
None
Train Offline, Test Online: A Real Robot Learning Benchmark
{kind=link}
None
Multi-Source Transfer Learning for Deep Model-Based Reinforcement Learning
{kind=link}
None
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
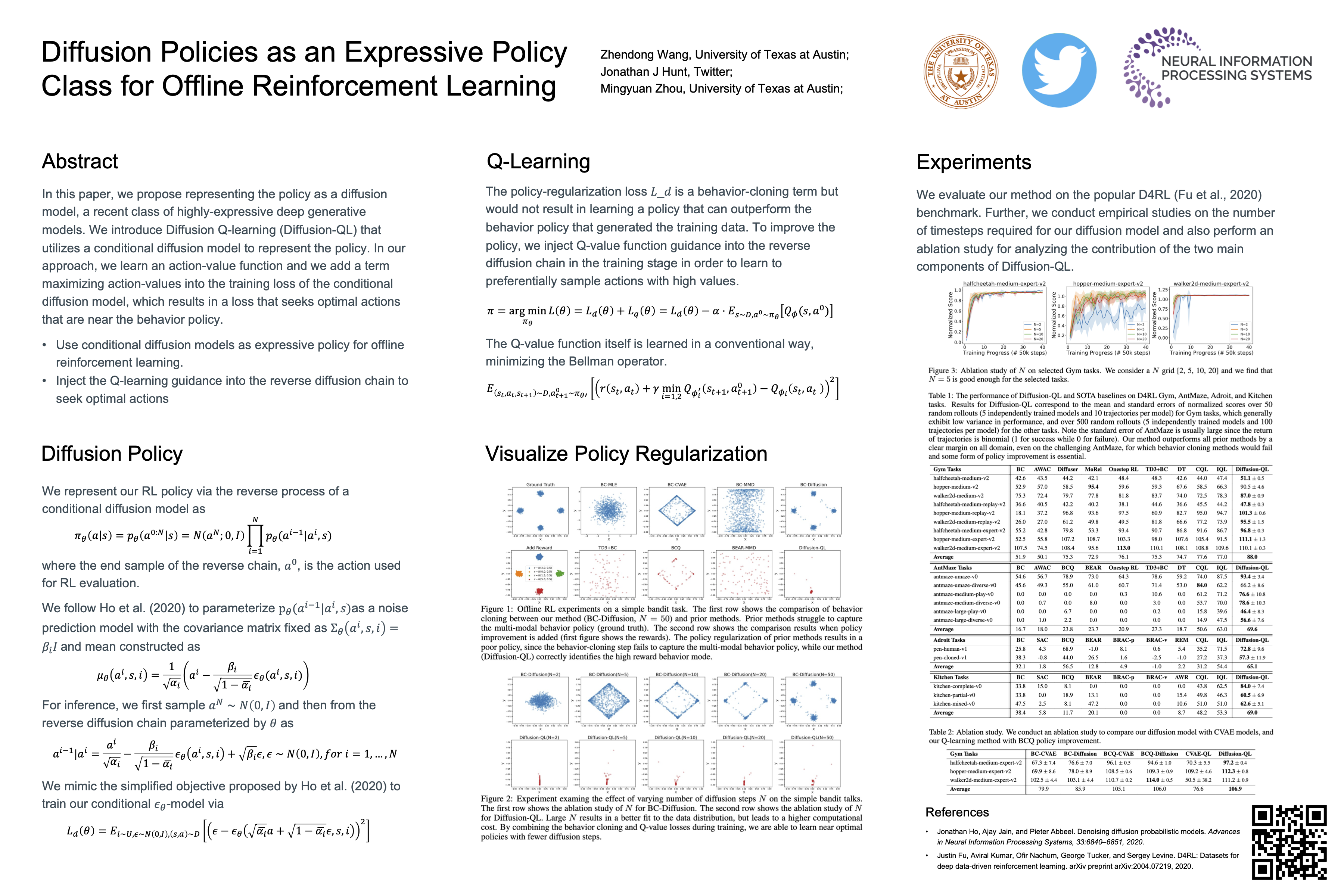{kind=link}
None
Ensemble based uncertainty estimation with overlapping alternative predictions
{kind=link}
None
Investigating Multi-task Pretraining and Generalization in Reinforcement Learning
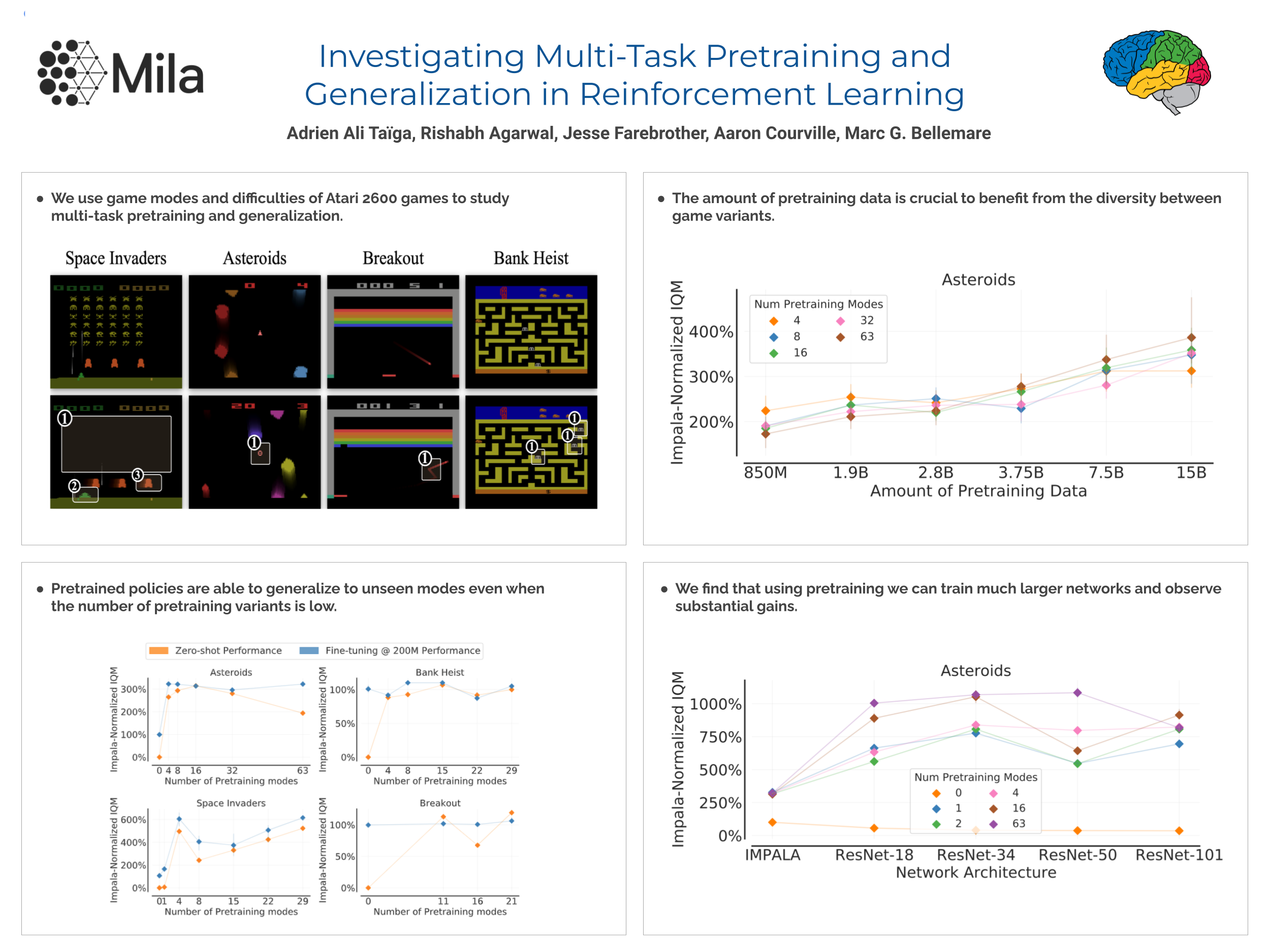{kind=link}
None
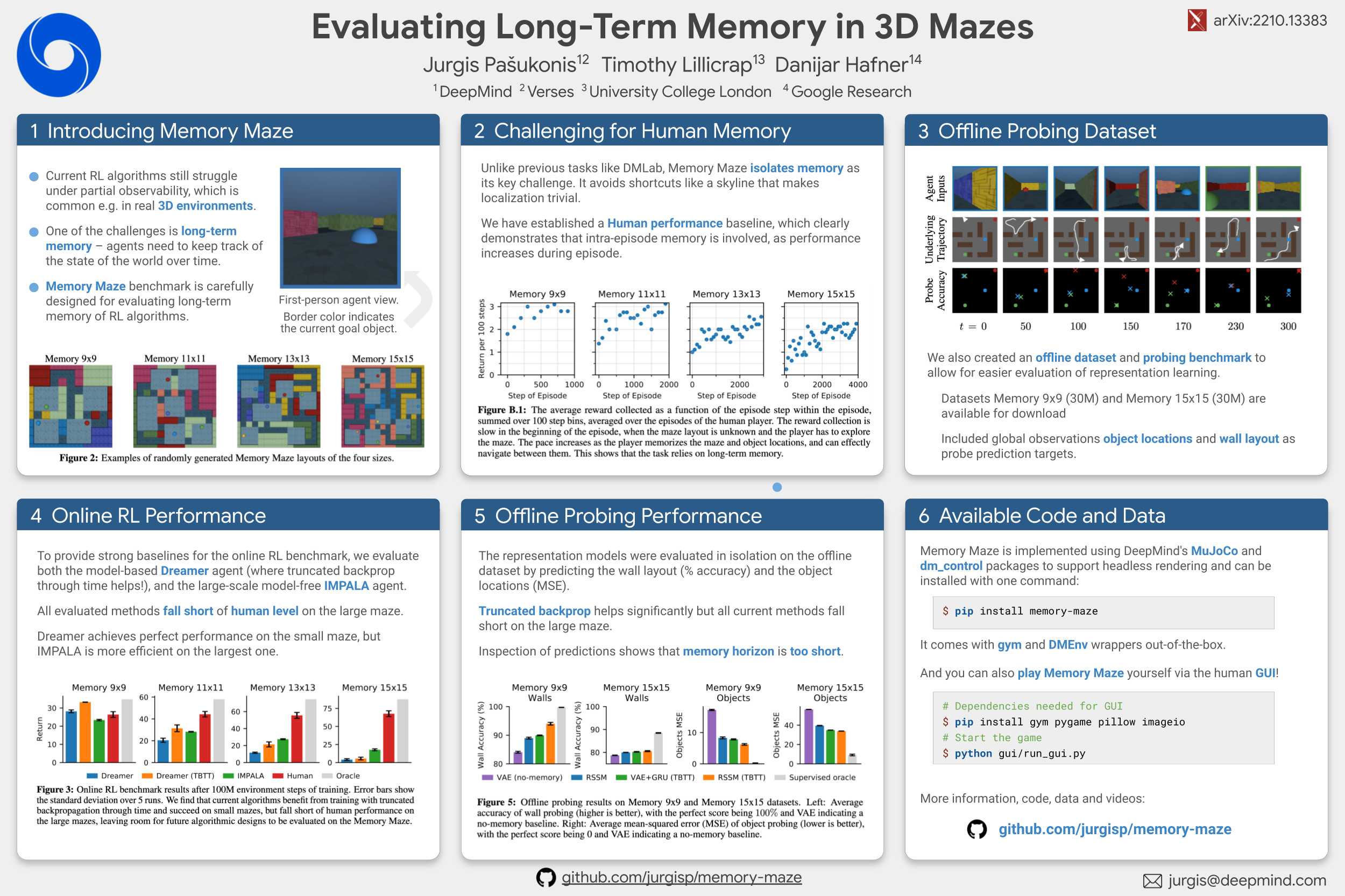
Evaluating Long-Term Memory in 3D Mazes
{kind=link}
None
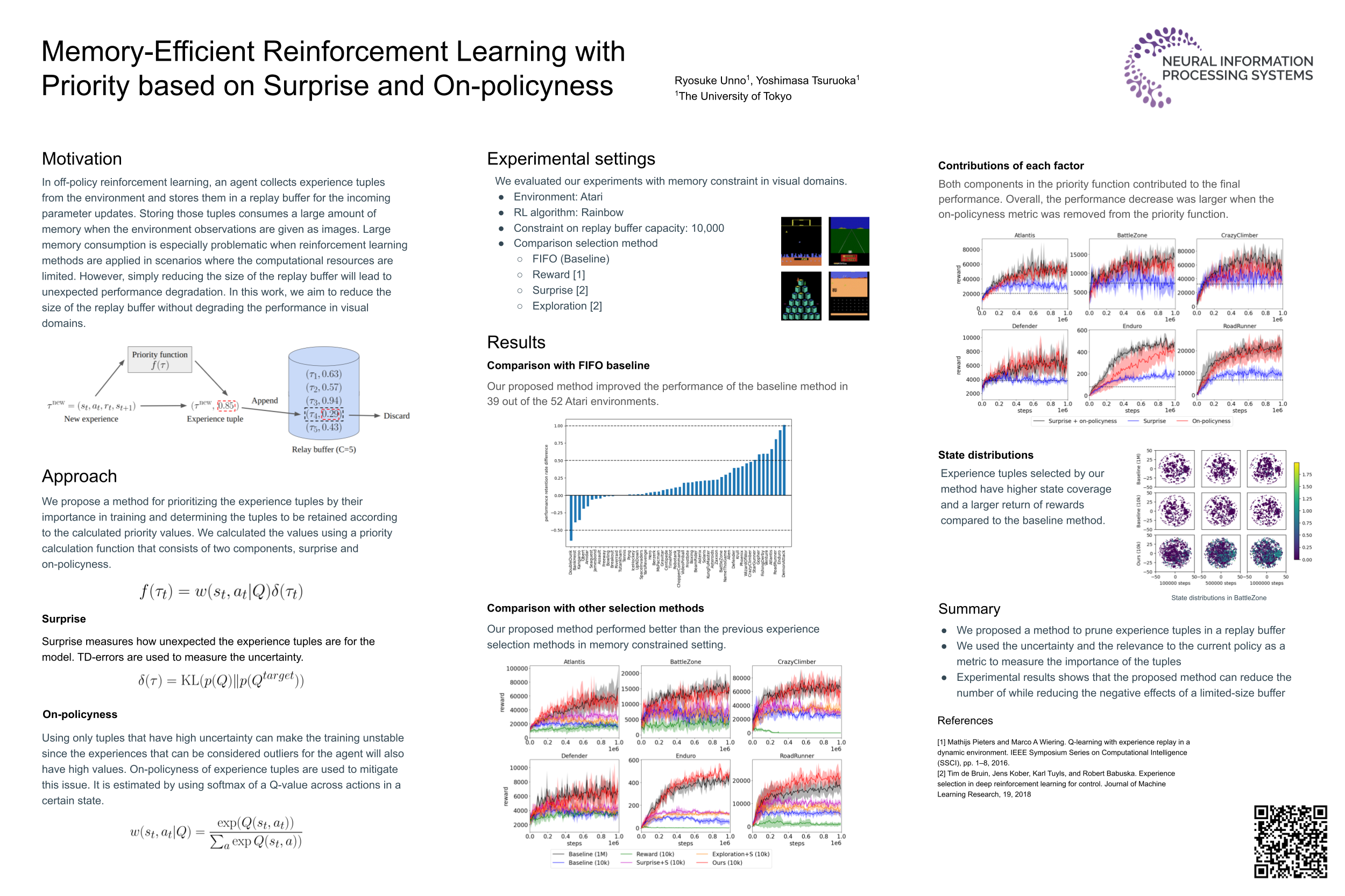
Memory-Efficient Reinforcement Learning with Priority based on Surprise and On-policyness
{kind=link}
None
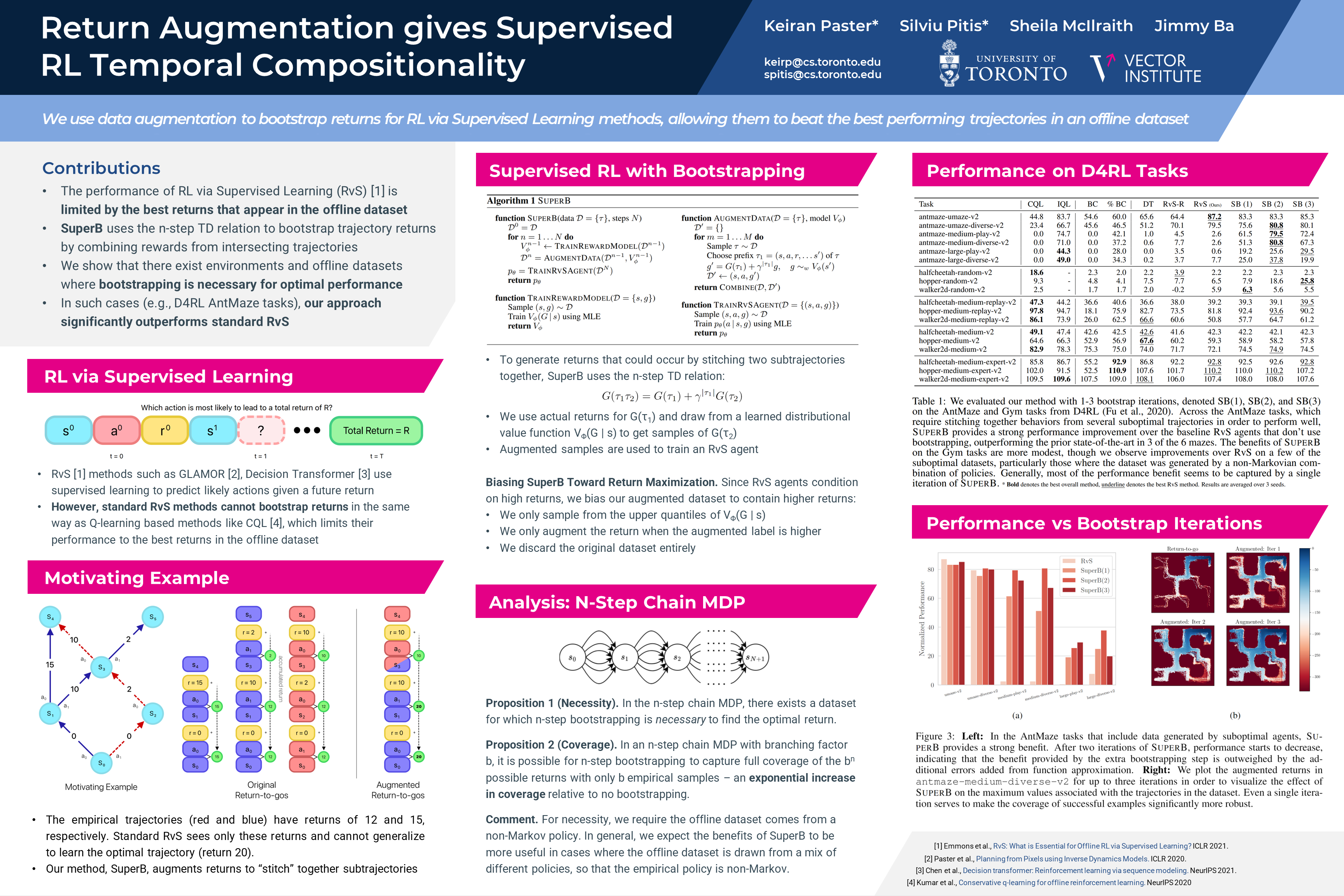
Return Augmentation gives Supervised RL Temporal Compositionality
{kind=link}
None
BLaDE: Robust Exploration via Diffusion Models
{kind=link}
None
Guiding Exploration Towards Impactful Actions
{kind=link}
None
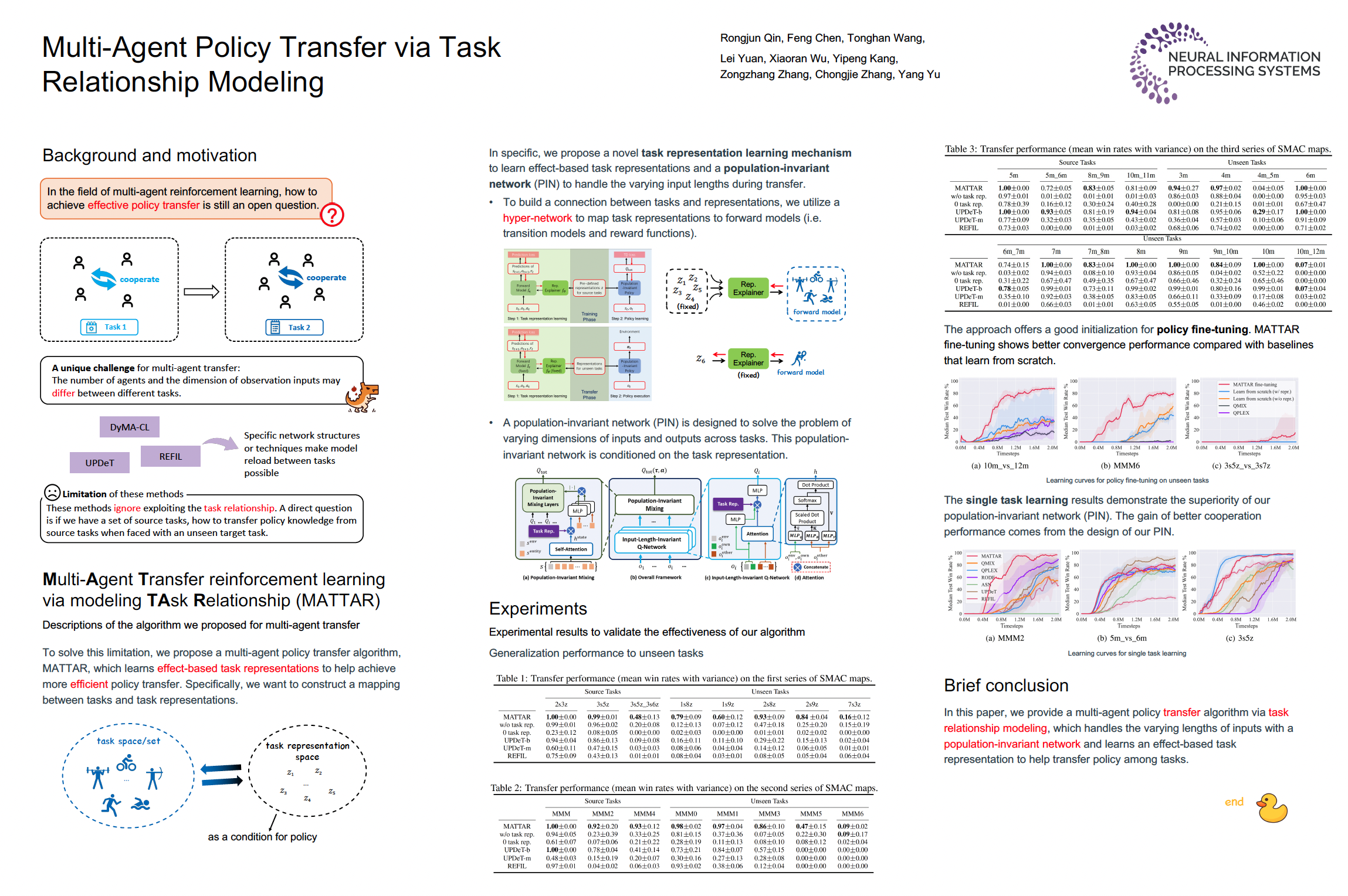
Multi-Agent Policy Transfer via Task Relationship Modeling
{kind=link}
None
Offline Reinforcement Learning on Real Robot with Realistic Data Sources
{kind=link}
None
MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning
{kind=link}
None
Training Equilibria in Reinforcement Learning
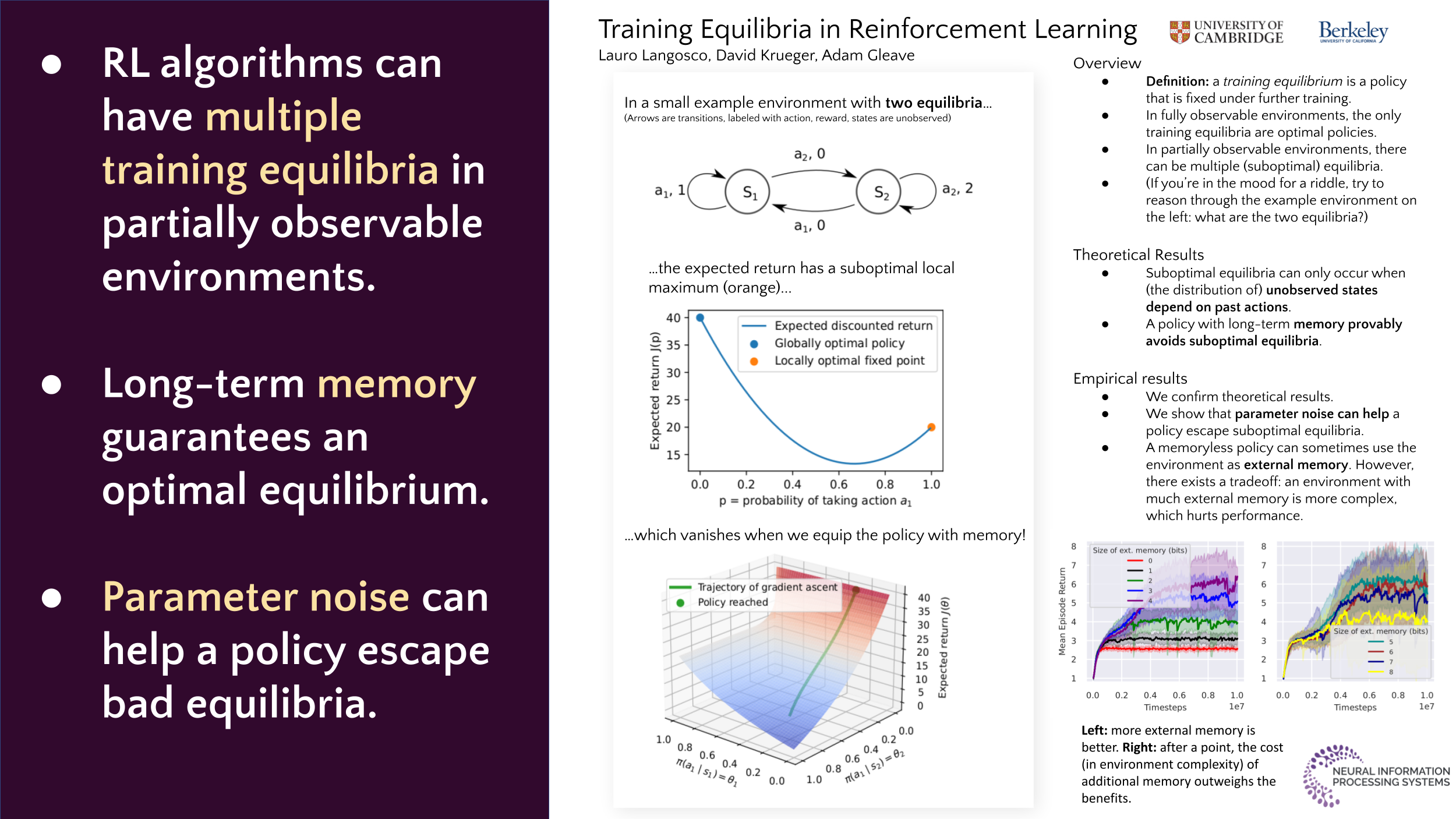{kind=link}
None
Hyperbolic Deep Reinforcement Learning
{kind=link}
None
Transformer-based World Models Are Happy With 100k Interactions
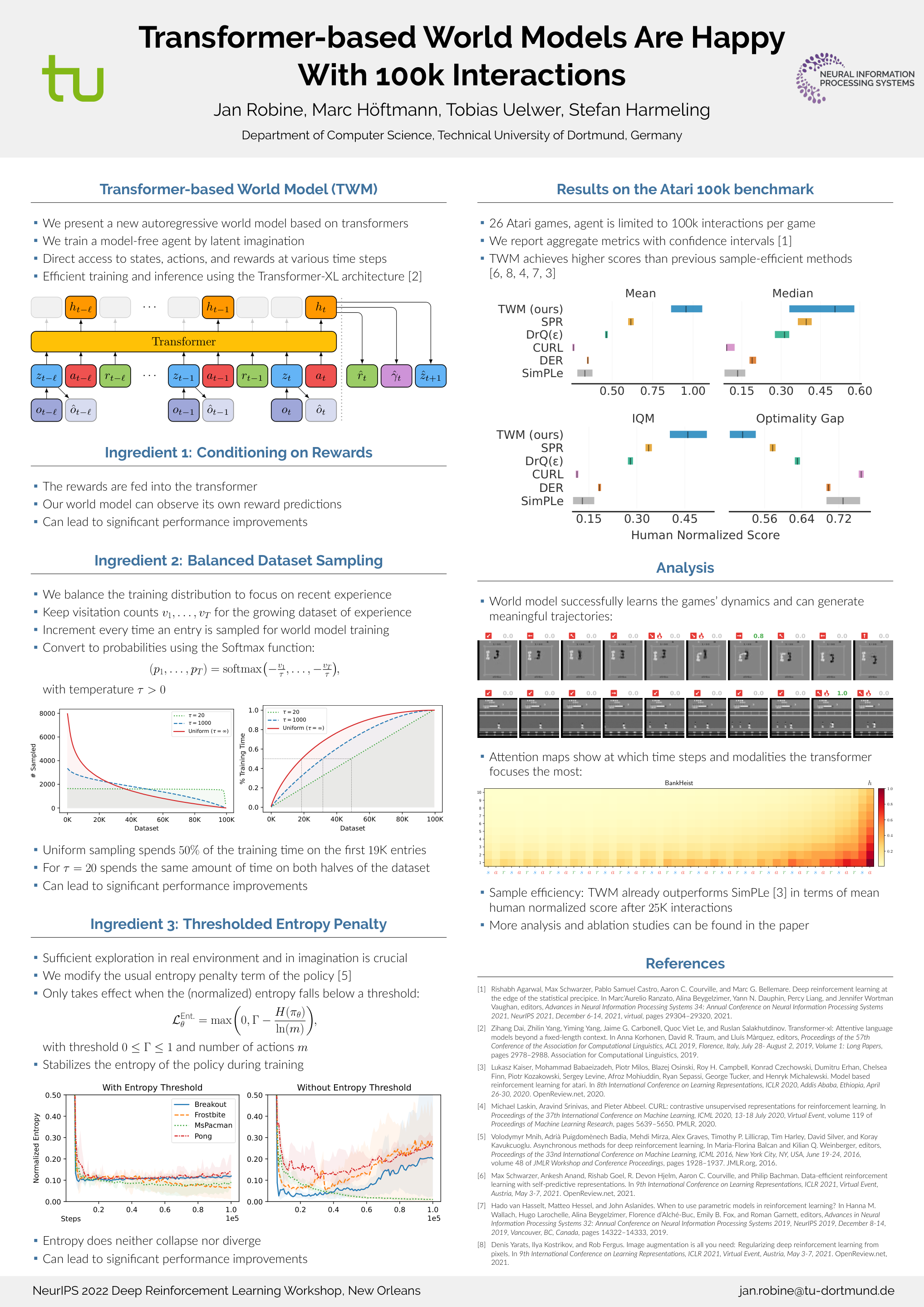{kind=link}
None
The Benefits of Model-Based Generalization in Reinforcement Learning
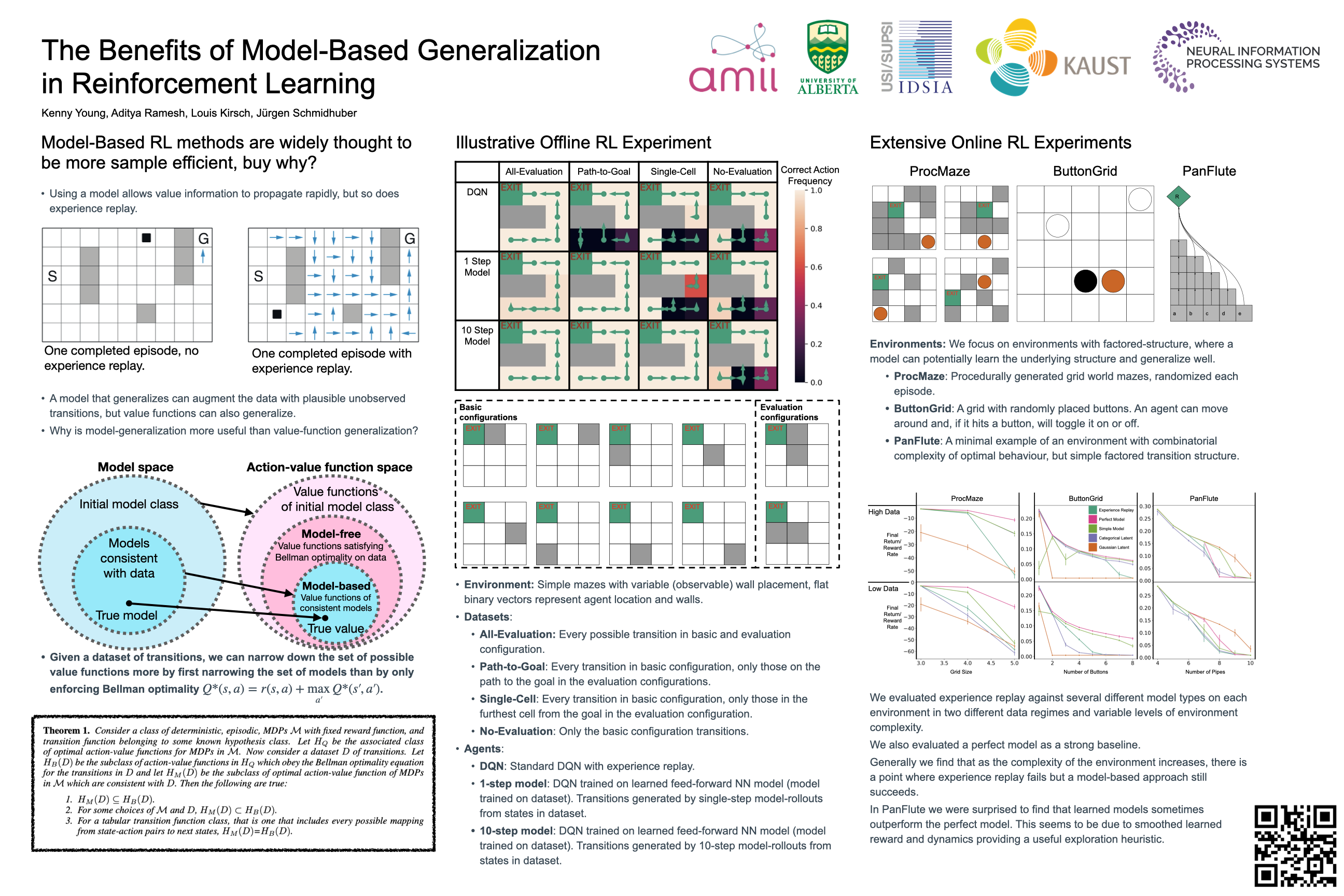{kind=link}
None
Variance Reduction in Off-Policy Deep Reinforcement Learning using Spectral Normalization
[
OpenReview]
[
Topia]
None
Prioritizing Samples in Reinforcement Learning with Reducible Loss
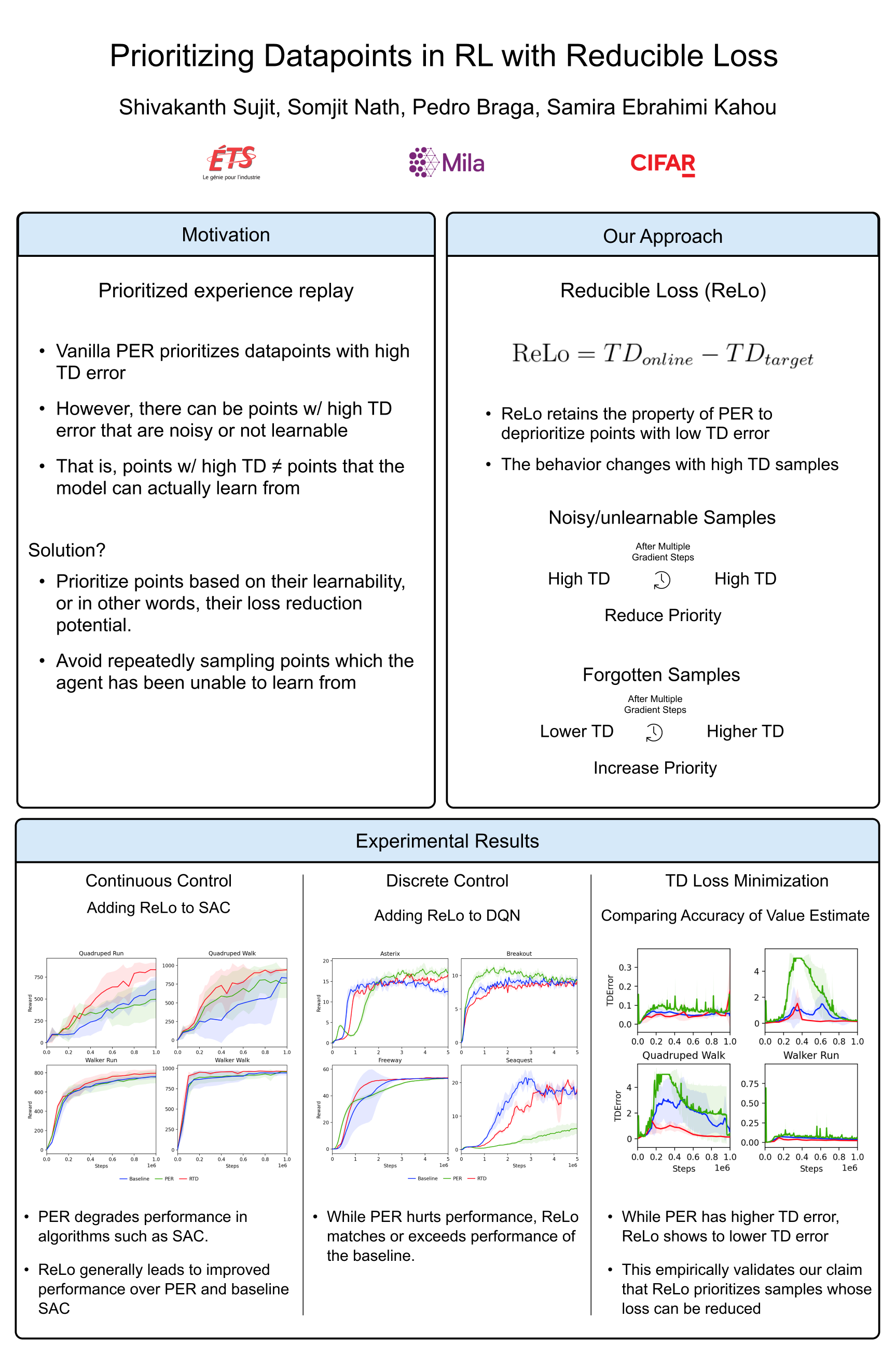{kind=link}
None
Value-based CTDE Methods in Symmetric Two-team Markov Game: from Cooperation to Team Competition
{kind=link}
None
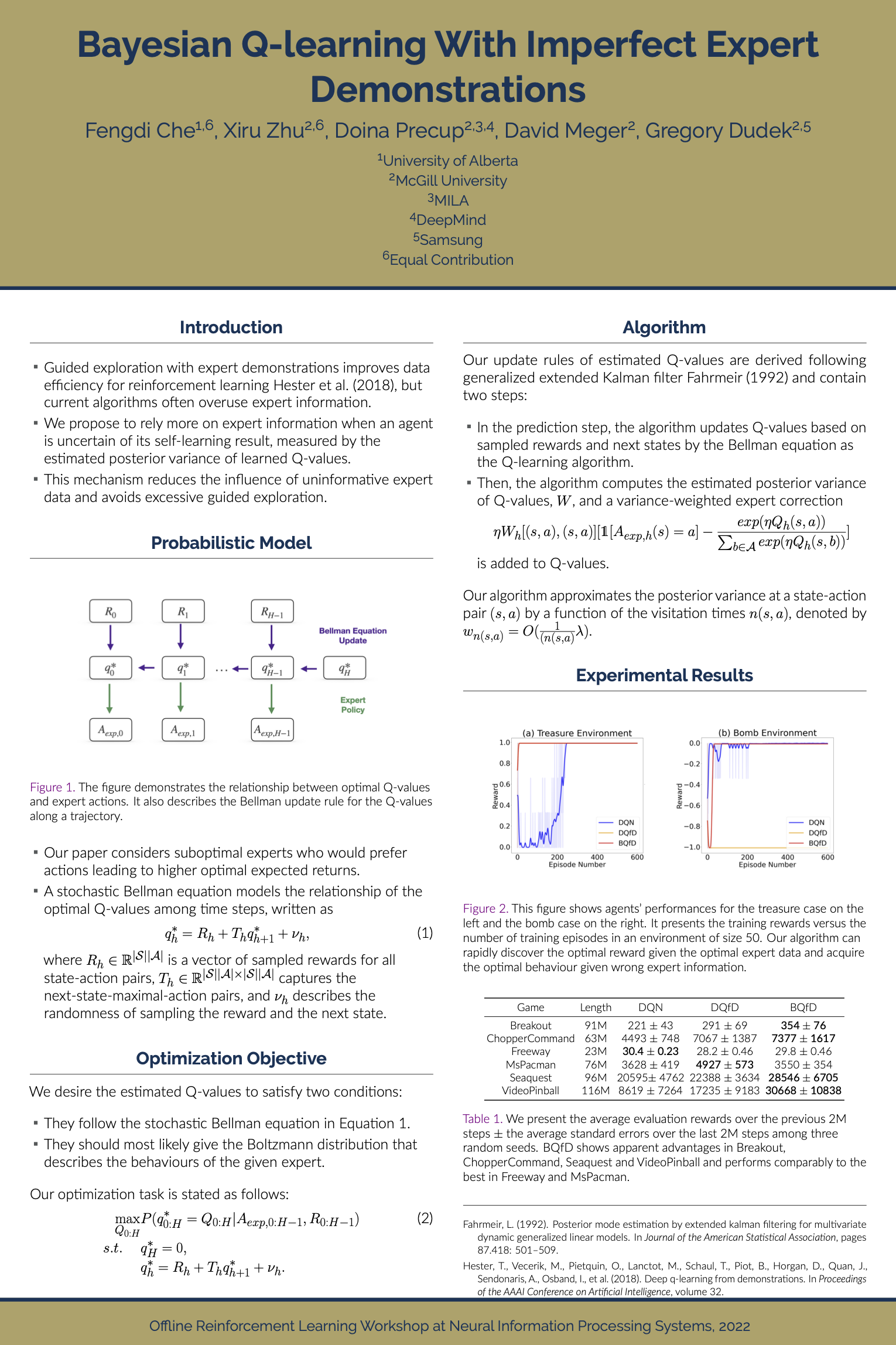
Bayesian Q-learning With Imperfect Expert Demonstrations
{kind=link}
None
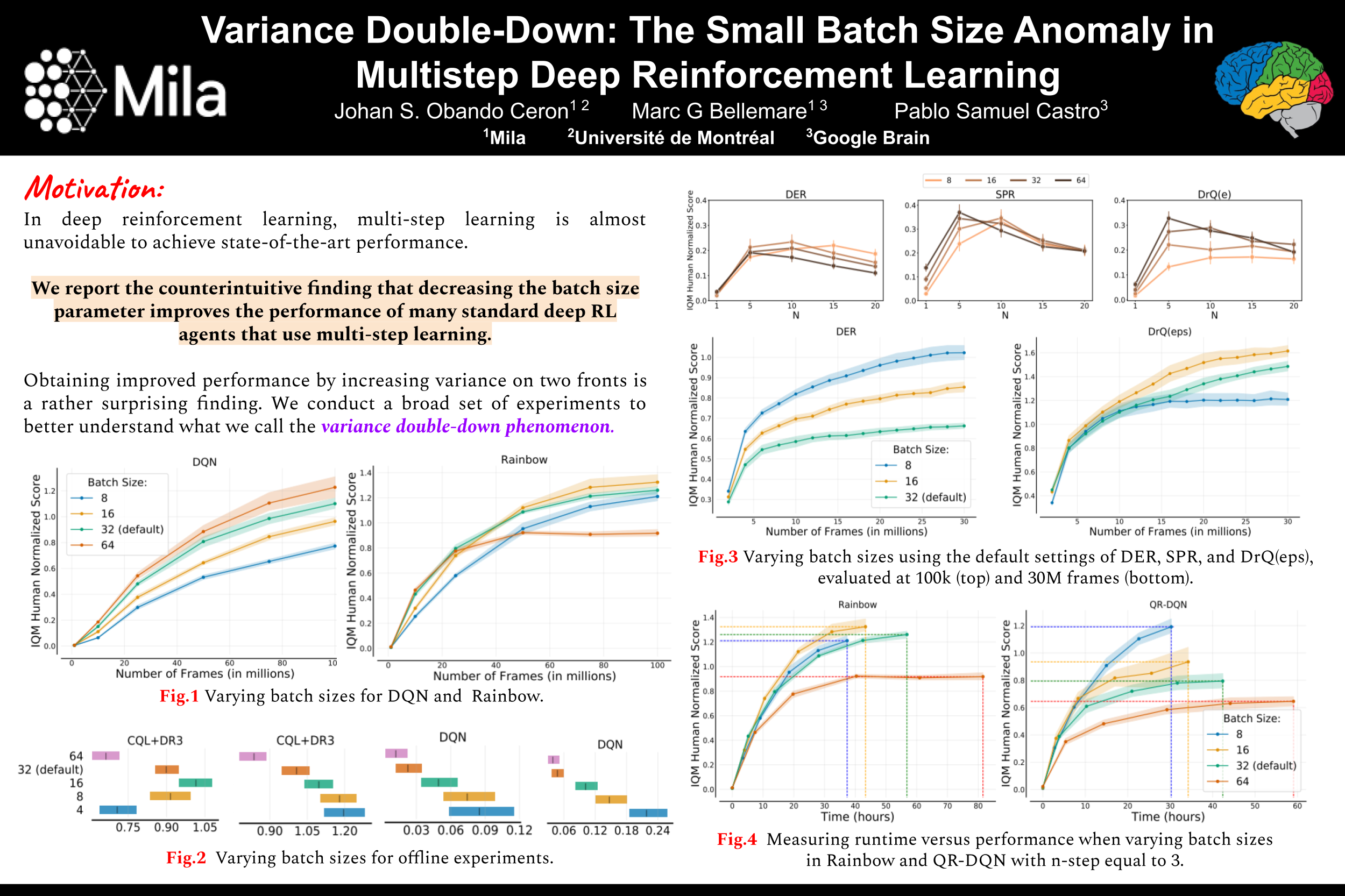
Variance Double-Down: The Small Batch Size Anomaly in Multistep Deep Reinforcement Learning
{kind=link}
None
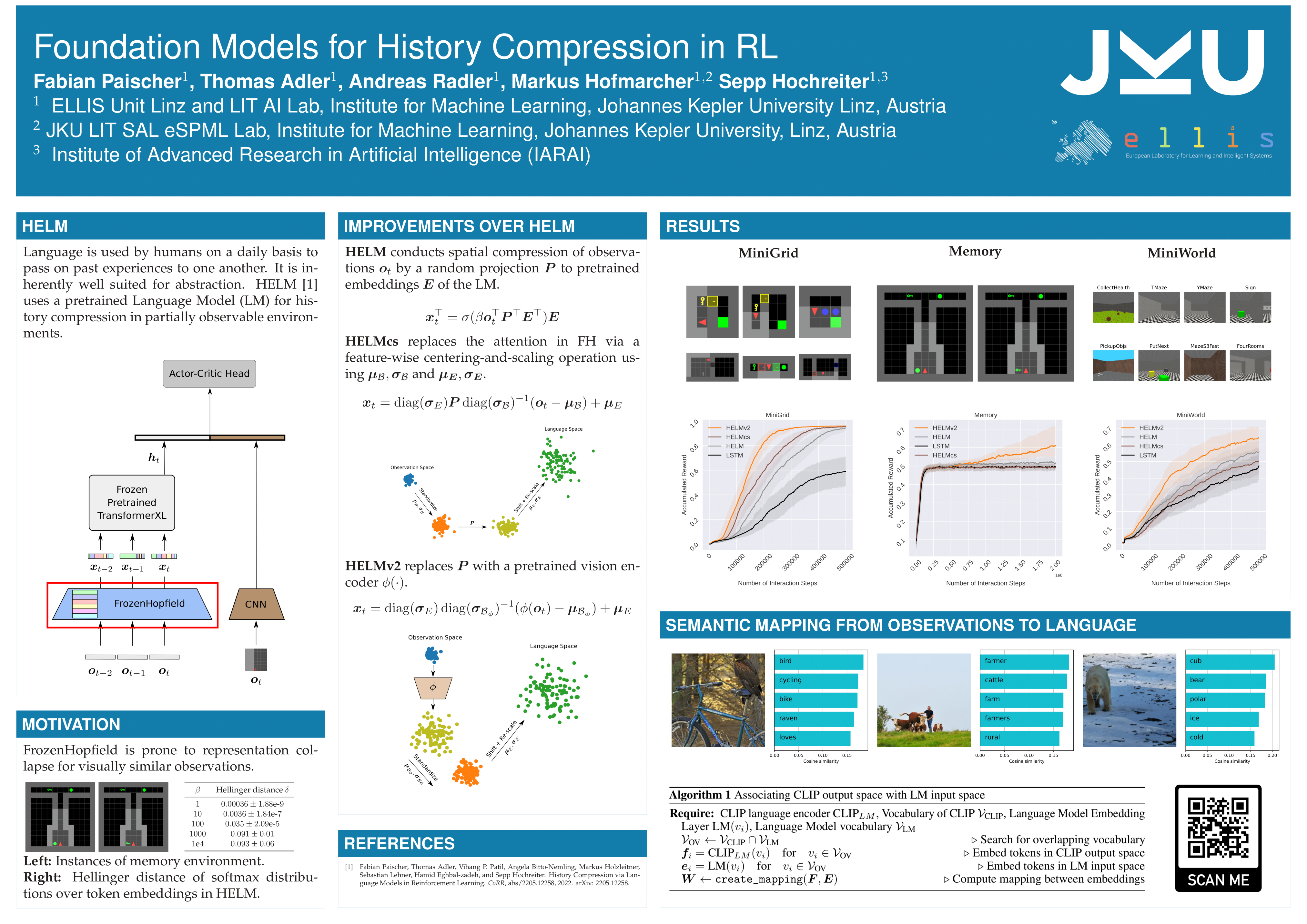
Foundation Models for History Compression in Reinforcement Learning
{kind=link}
None
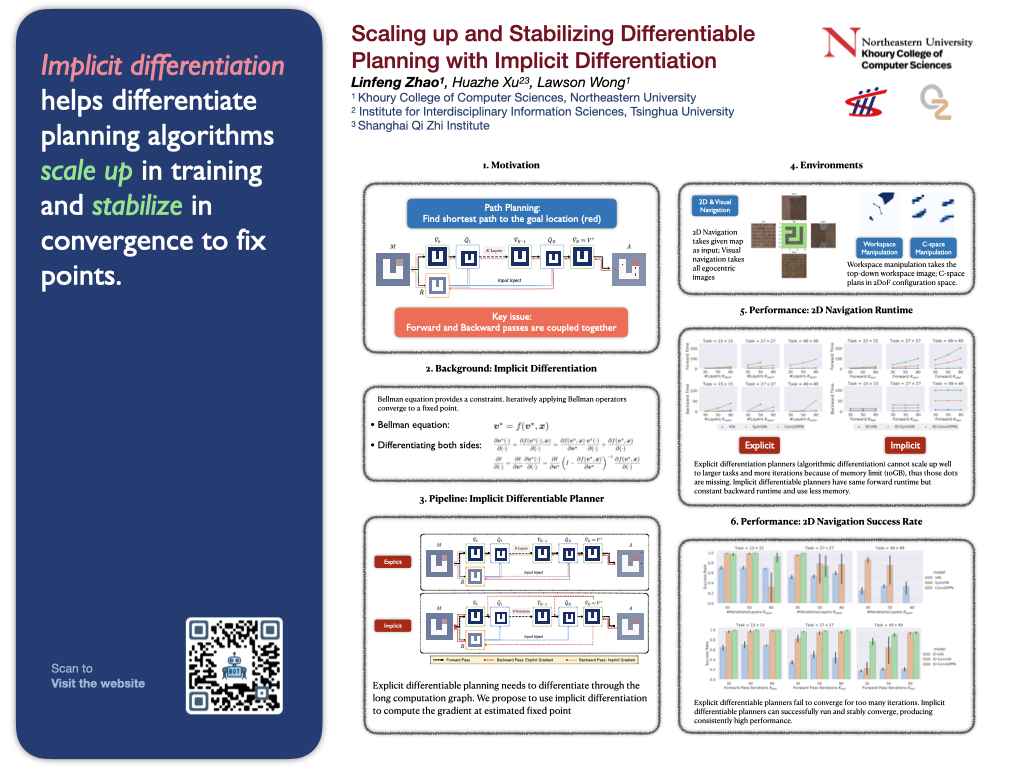
Scaling up and Stabilizing Differentiable Planning with Implicit Differentiation
{kind=link}
None
AsymQ: Asymmetric Q-loss to mitigate overestimation bias in off-policy reinforcement learning
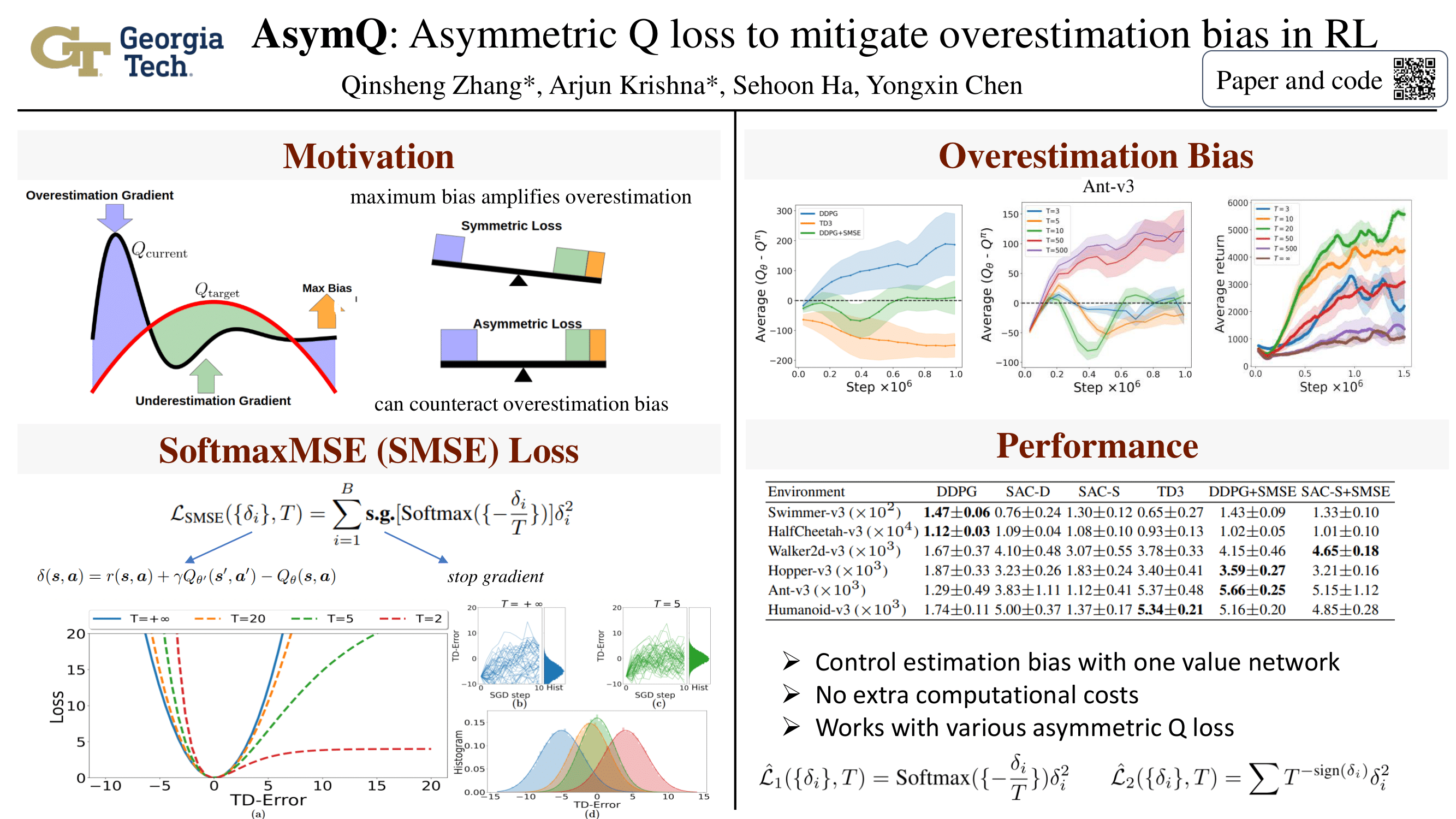{kind=link}
None
Aggressive Q-Learning with Ensembles: Achieving Both High Sample Efficiency and High Asymptotic Performance
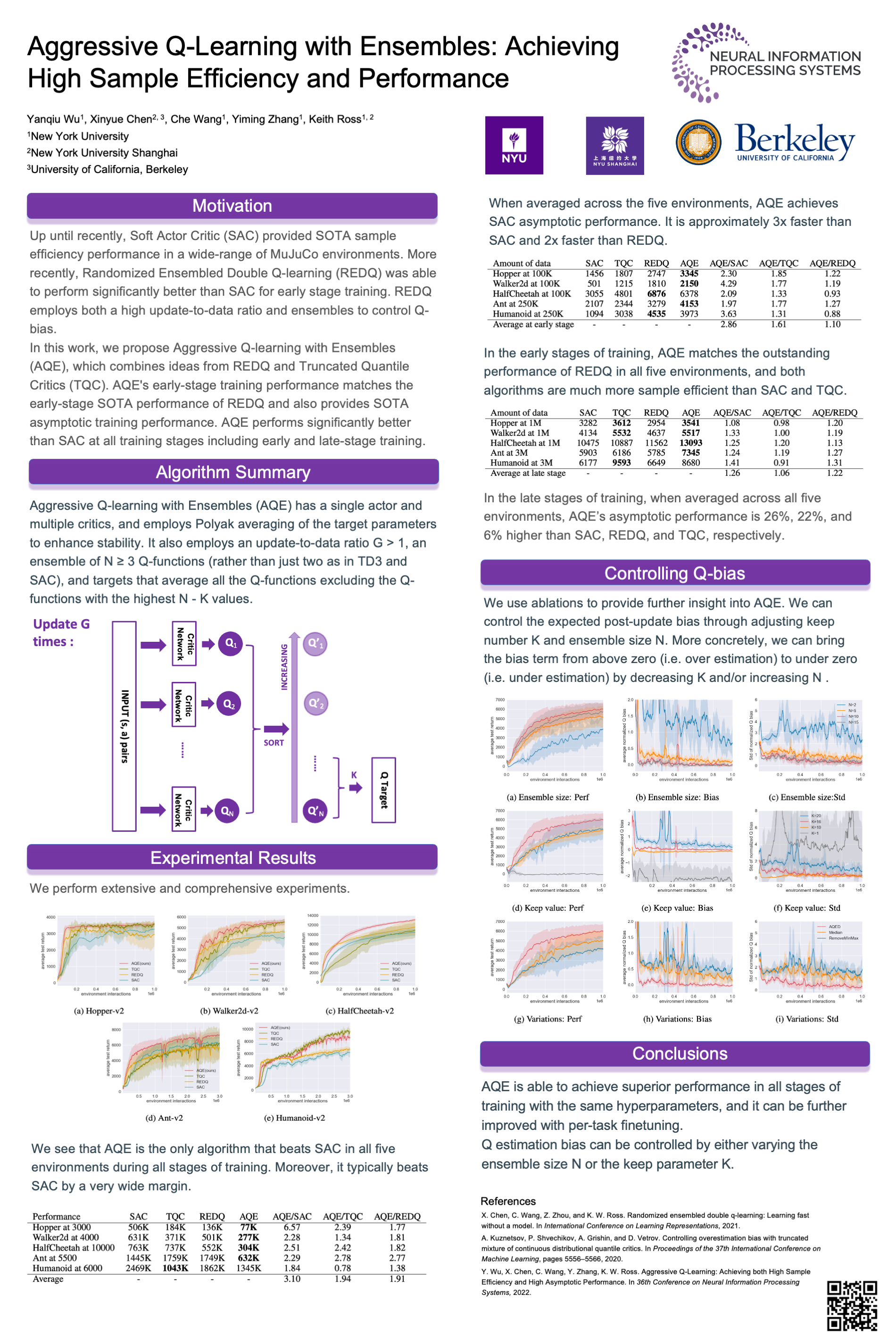{kind=link}
None
Integrating Episodic and Global Bonuses for Efficient Exploration
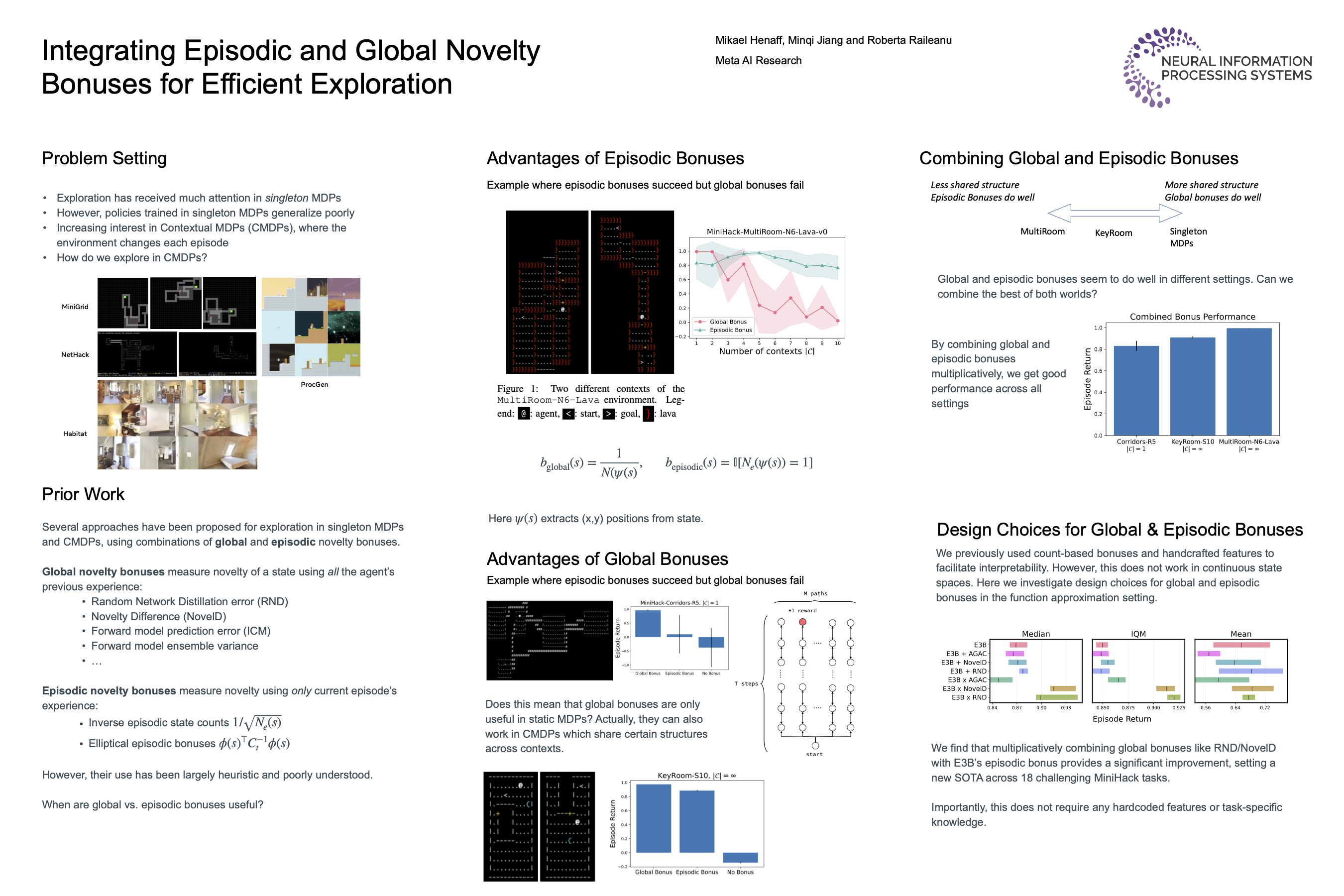{kind=link}
None
Design Process is a Reinforcement Learning Problem
{kind=link}
None
Efficient Deep Reinforcement Learning Requires Regulating Statistical Overfitting
{kind=link}
None
Uncertainty-Driven Exploration for Generalization in Reinforcement Learning
{kind=link}
None
The Surprising Effectiveness of Latent World Models for Continual Reinforcement Learning
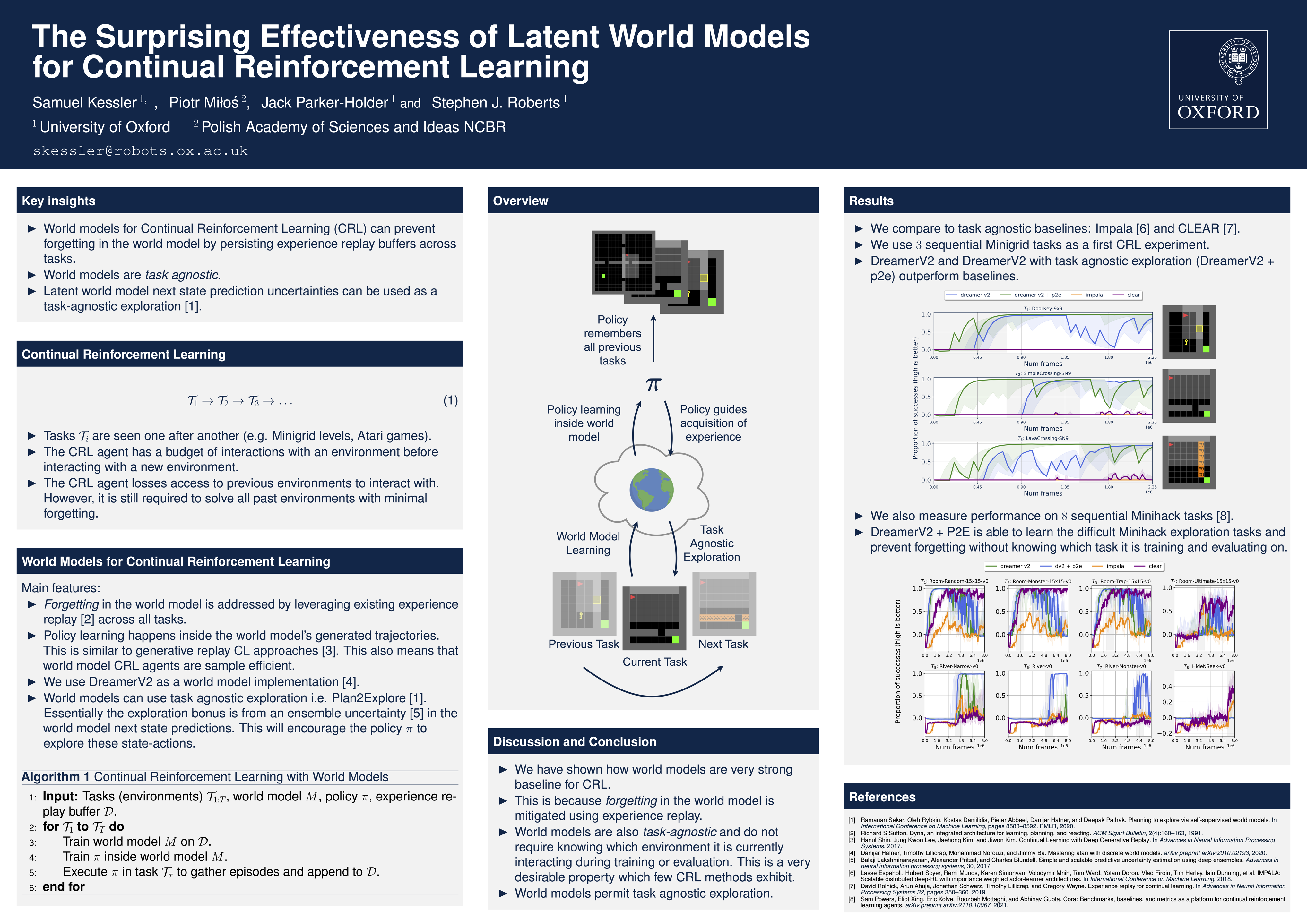{kind=link}
None
Understanding Hindsight Goal Relabeling Requires Rethinking Divergence Minimization
[
OpenReview]
[
Topia]
None
Domain Invariant Q-Learning for model-free robust continuous control under visual distractions
{kind=link}
None
Pre-Training for Robots: Leveraging Diverse Multitask Data via Offline Reinforcement Learning
[
OpenReview]
[
Topia]
None
Offline Reinforcement Learning from Heteroskedastic Data Via Support Constraints
[
OpenReview]
[
Topia]
None
Imitation from Observation With Bootstrapped Contrastive Learning
{kind=link}
None
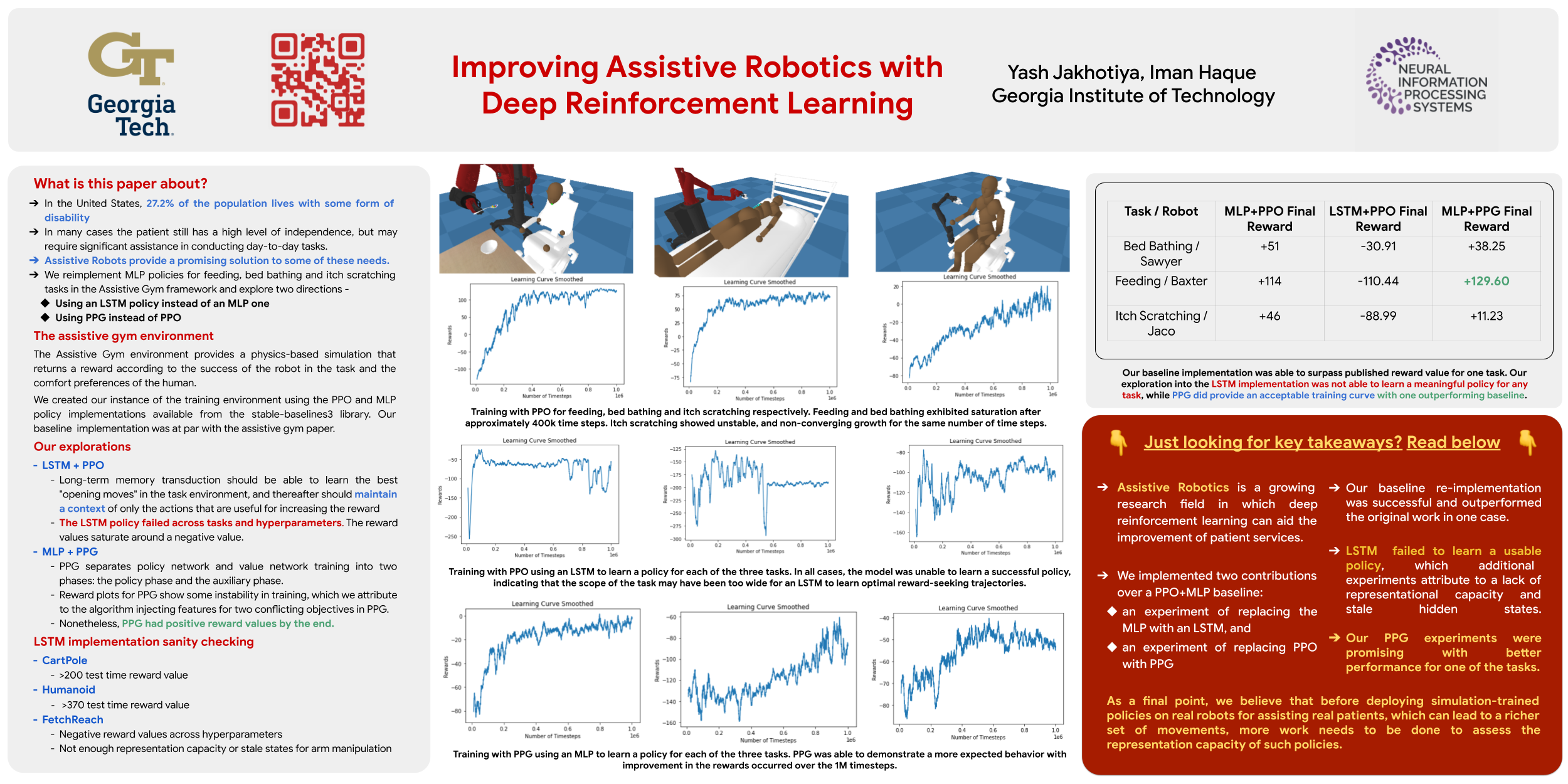
Improving Assistive Robotics with Deep Reinforcement Learning
{kind=link}
None
Fantastic Rewards and How to Tame Them: A Case Study on Reward Learning for Task-Oriented Dialogue Systems
[
OpenReview]
[
Topia]
None
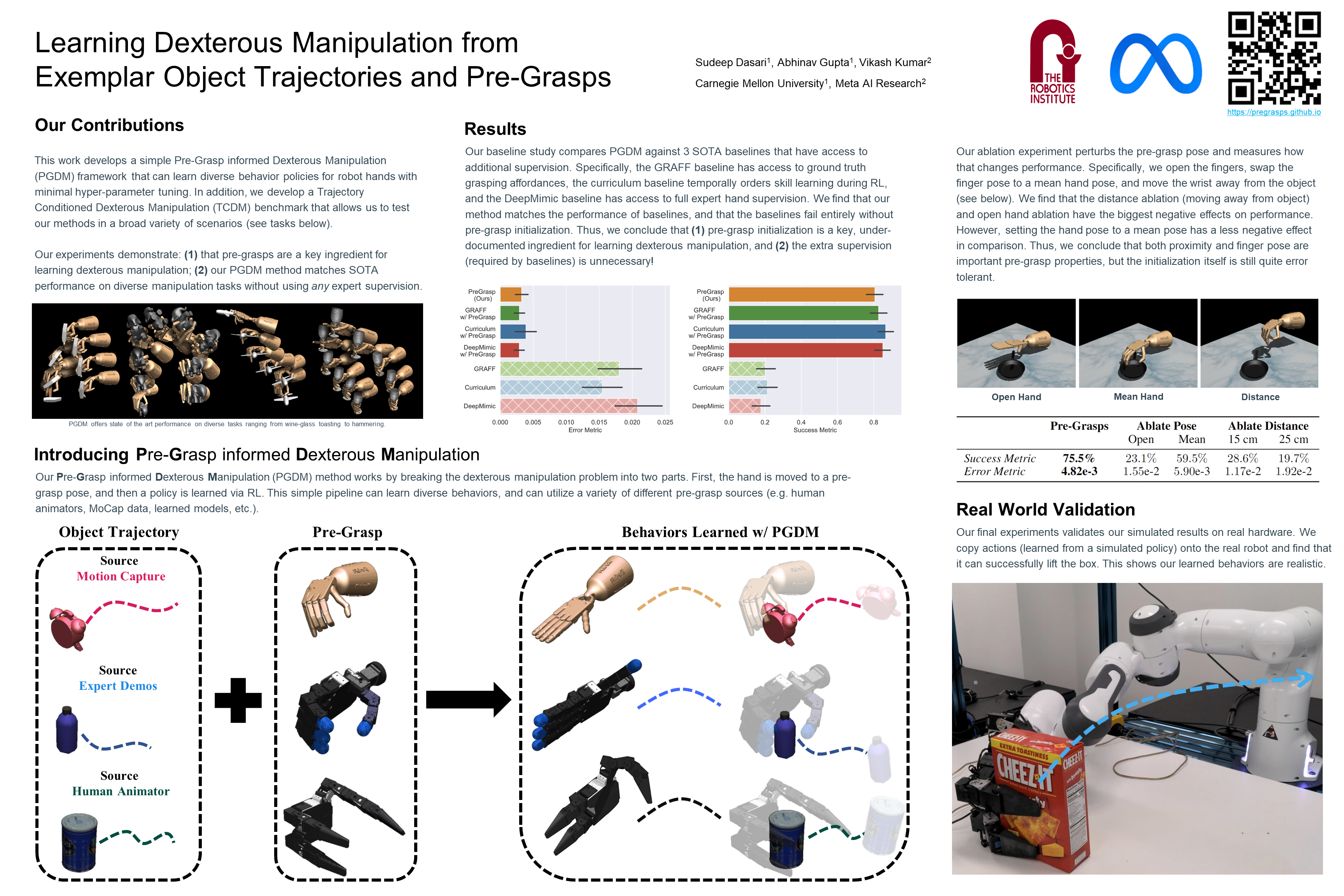
Learning Dexterous Manipulation from Exemplar Object Trajectories and Pre-Grasps
{kind=link}
None
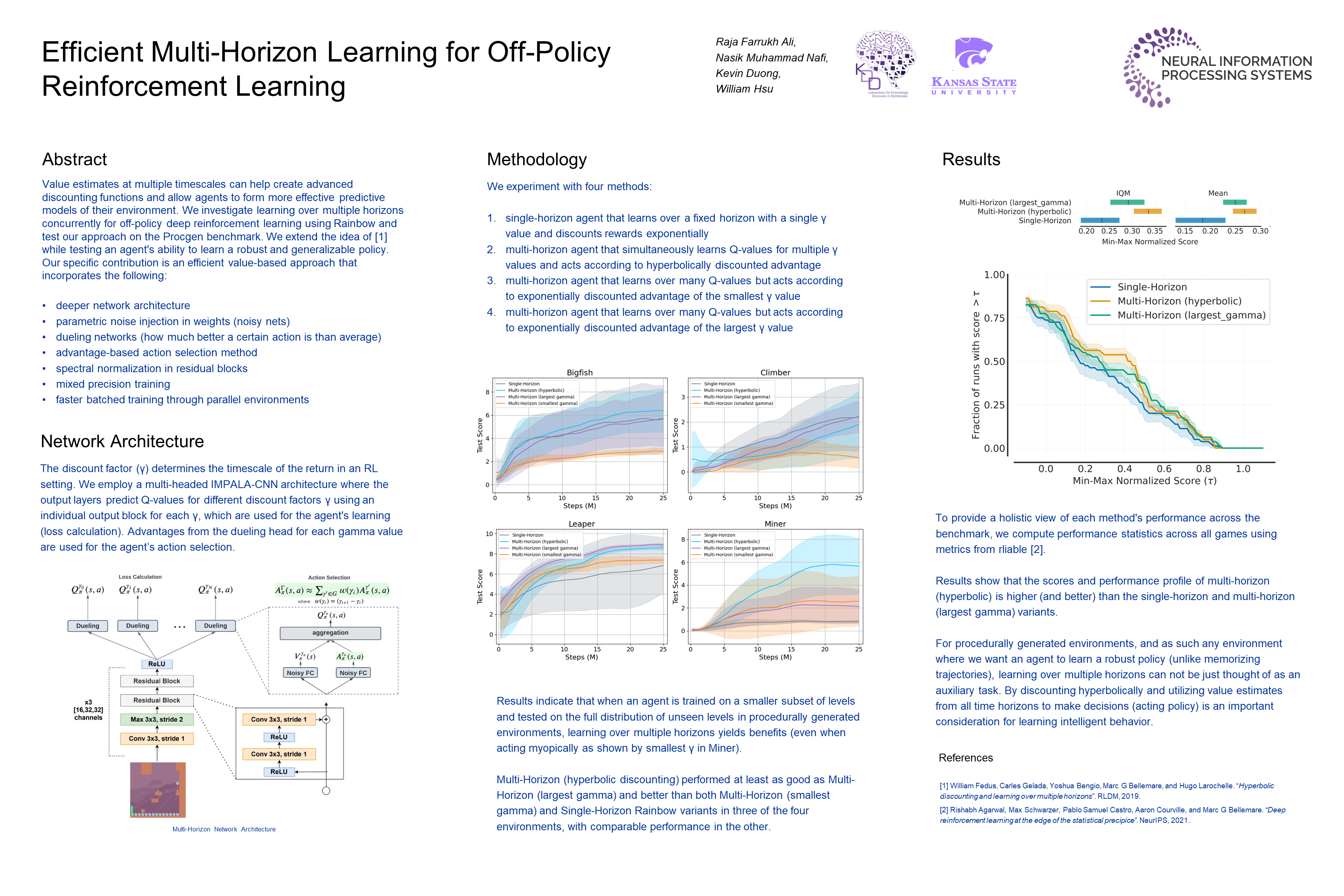
Efficient Multi-Horizon Learning for Off-Policy Reinforcement Learning
{kind=link}
None
Generalizable Point Cloud Reinforcement Learning for Sim-to-Real Dexterous Manipulation
[
OpenReview]
[
Topia]
None
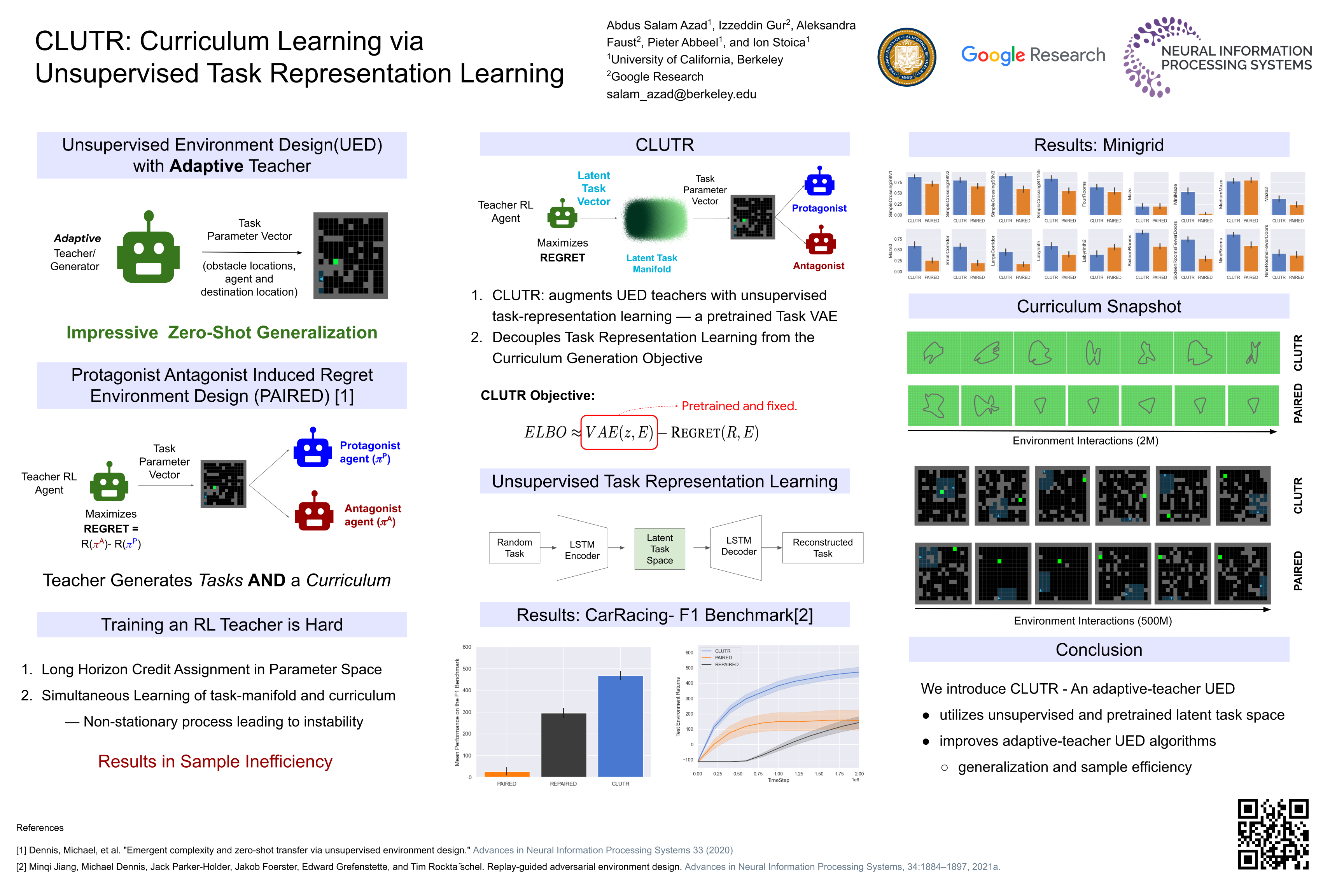
CLUTR: Curriculum Learning via Unsupervised Task Representation Learning
{kind=link}
None
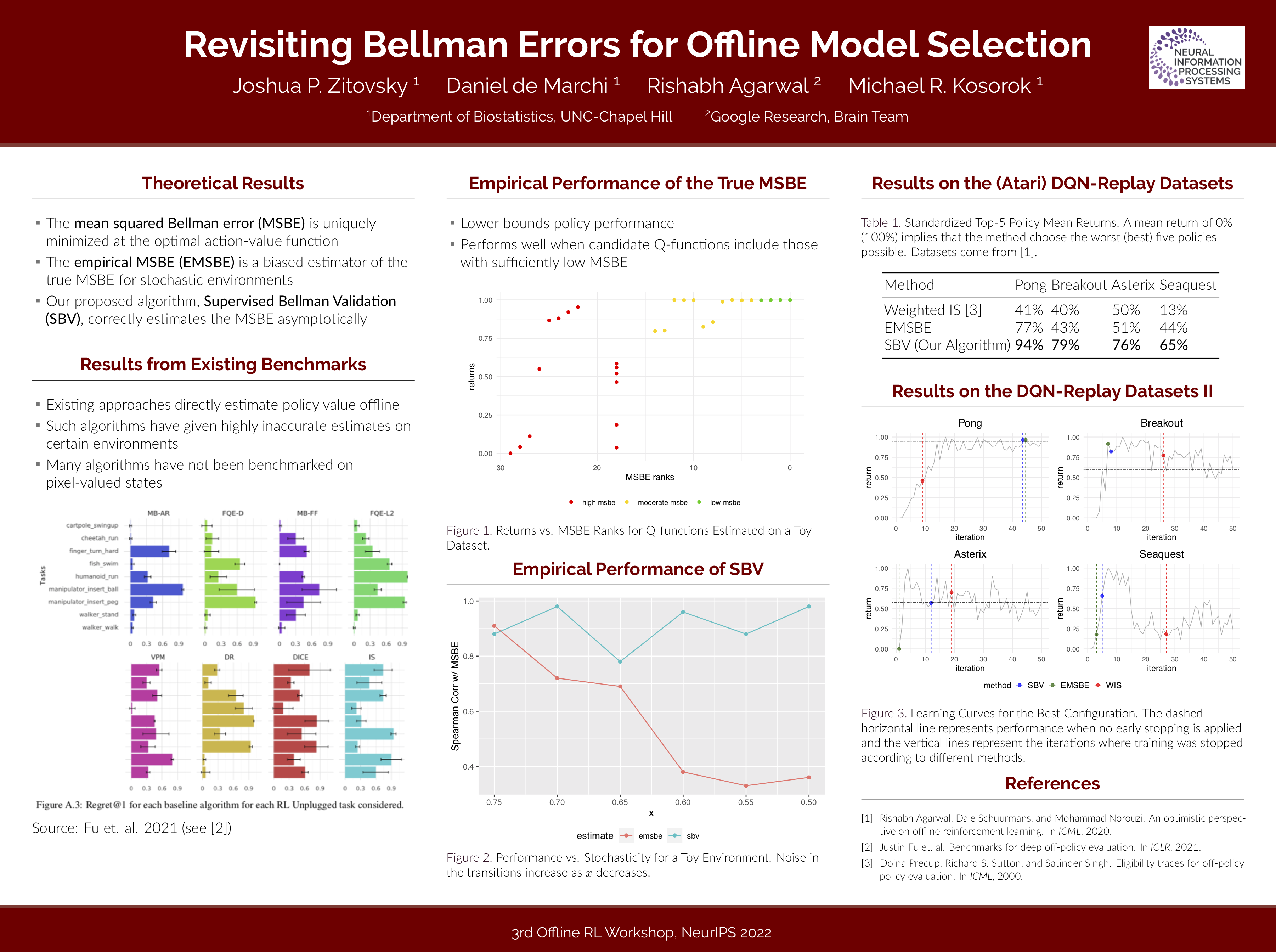
Revisiting Bellman Errors for Offline Model Selection
{kind=link}
None
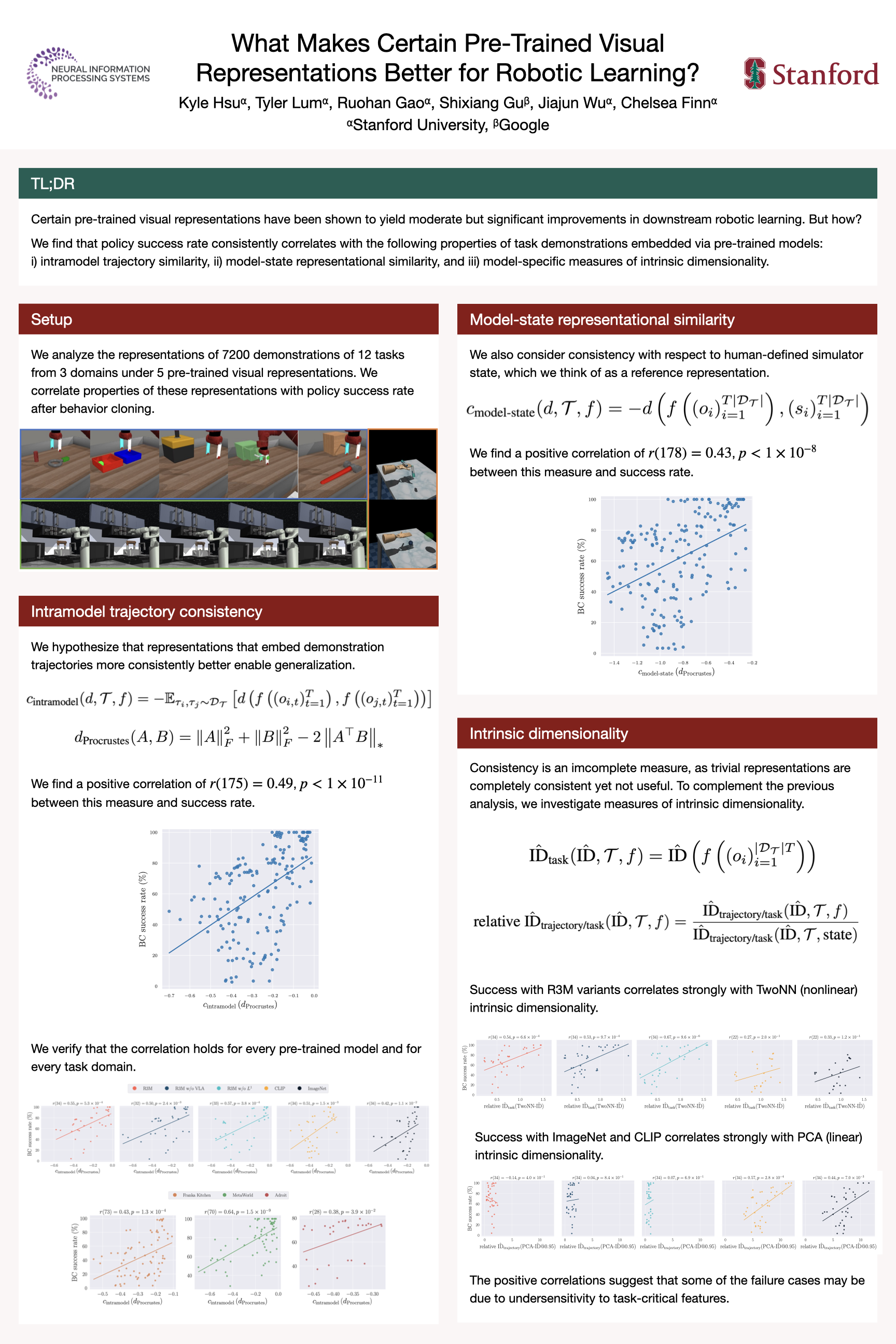
What Makes Certain Pre-Trained Visual Representations Better for Robotic Learning?
{kind=link}
None
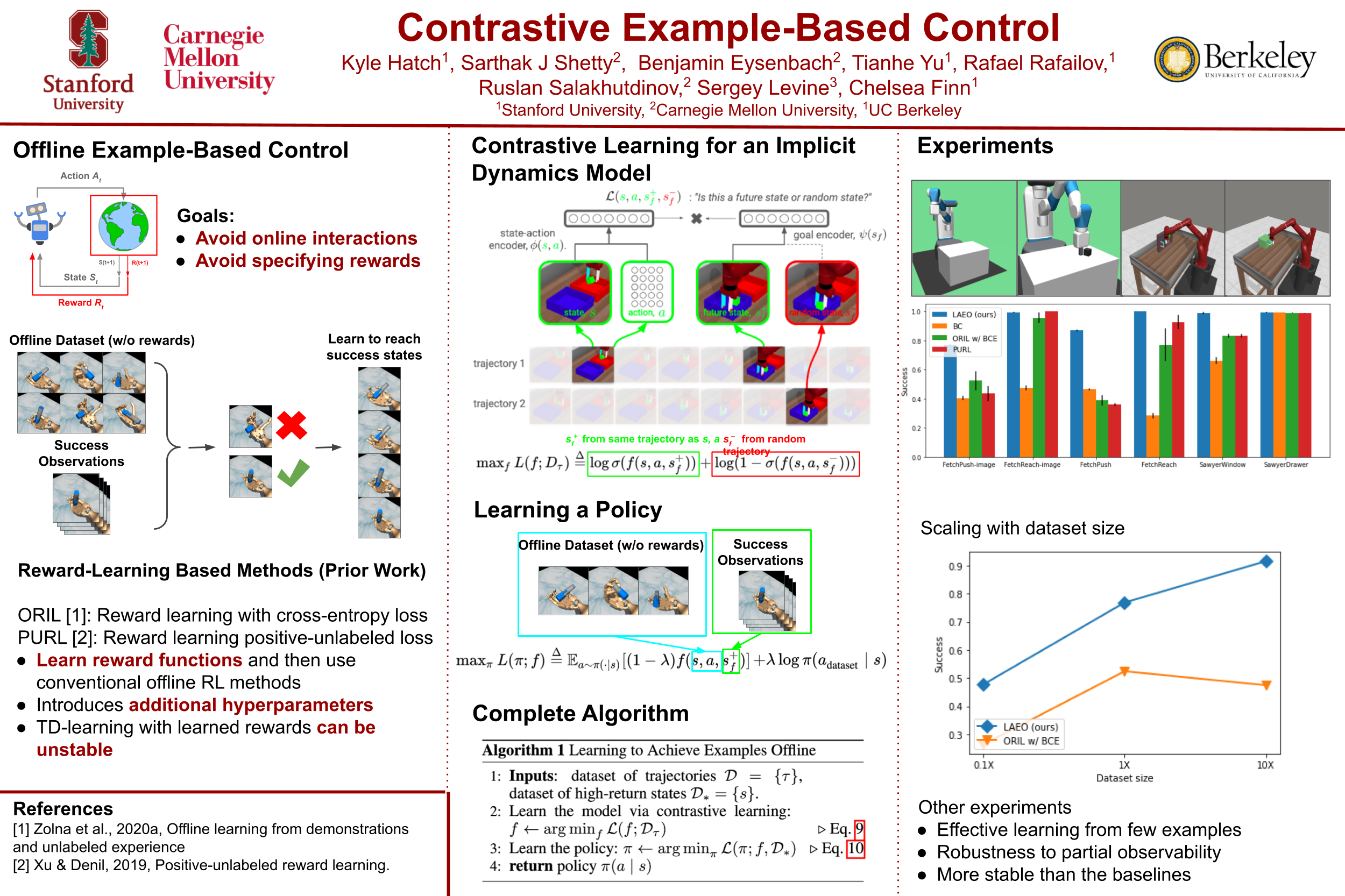
Contrastive Example-Based Control
{kind=link}
None
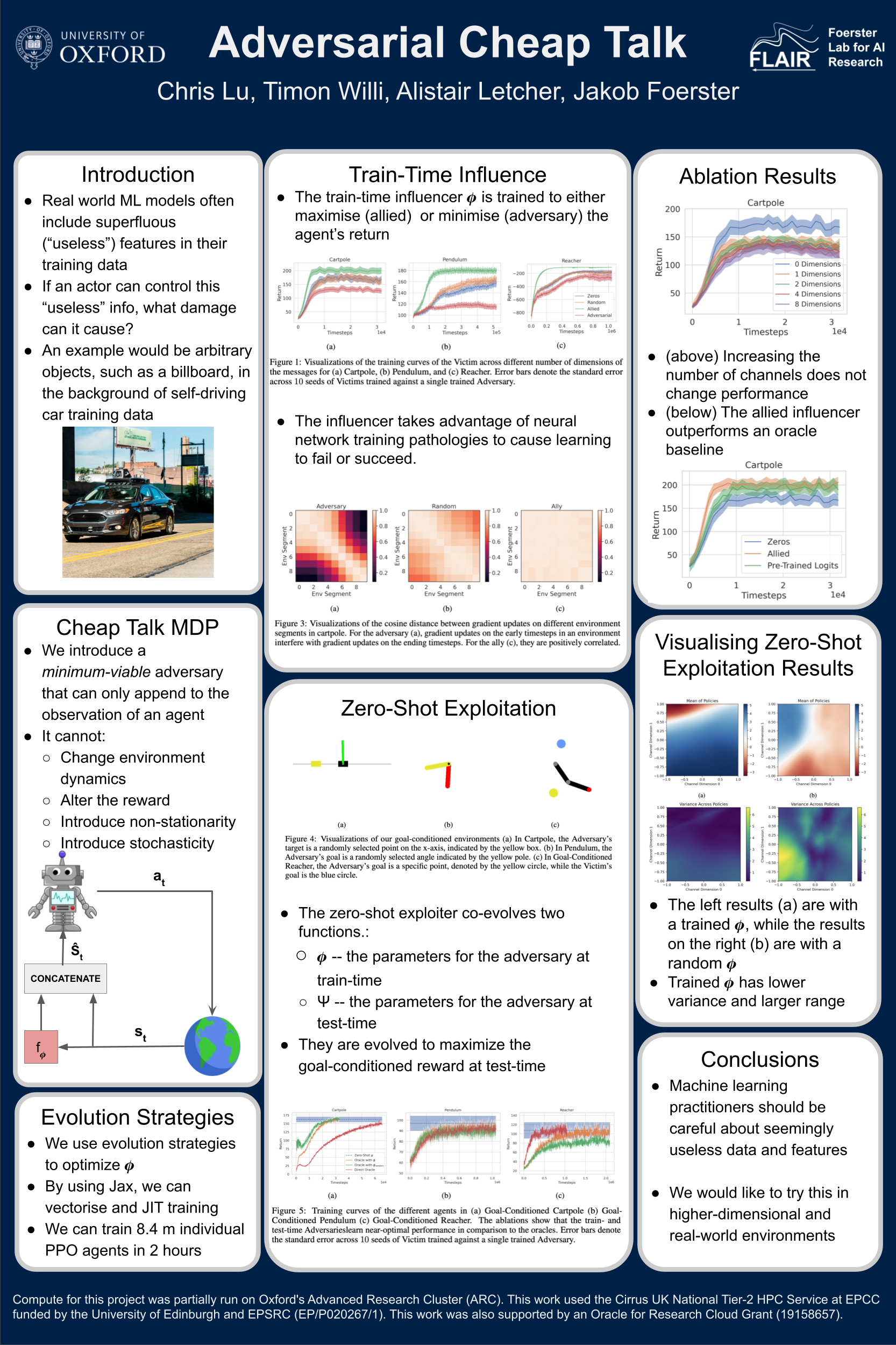
Adversarial Cheap Talk
{kind=link}
None
Giving Robots a Hand: Broadening Generalization via Hand-Centric Human Video Demonstrations
{kind=link}
None
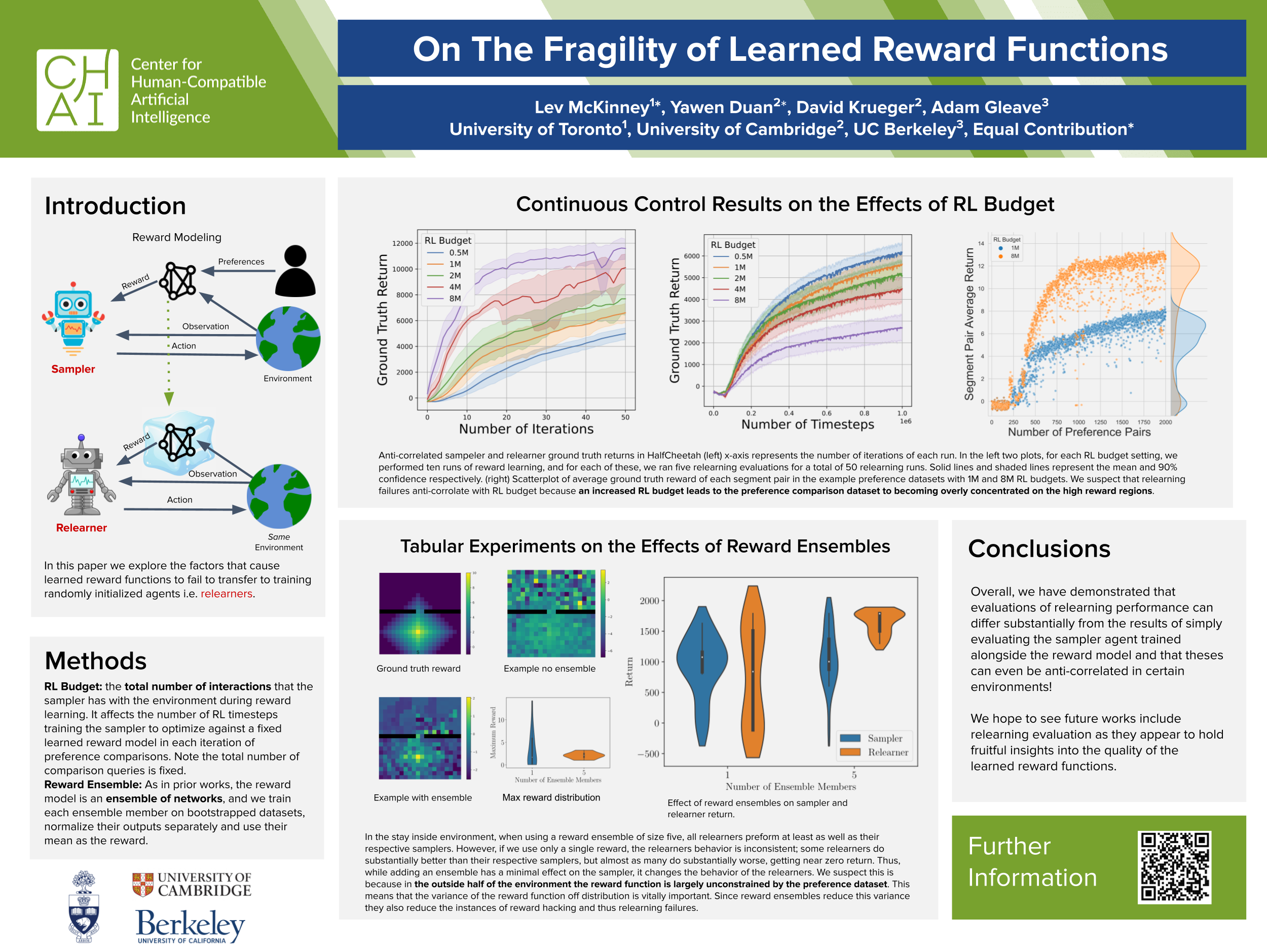
On The Fragility of Learned Reward Functions
{kind=link}
None
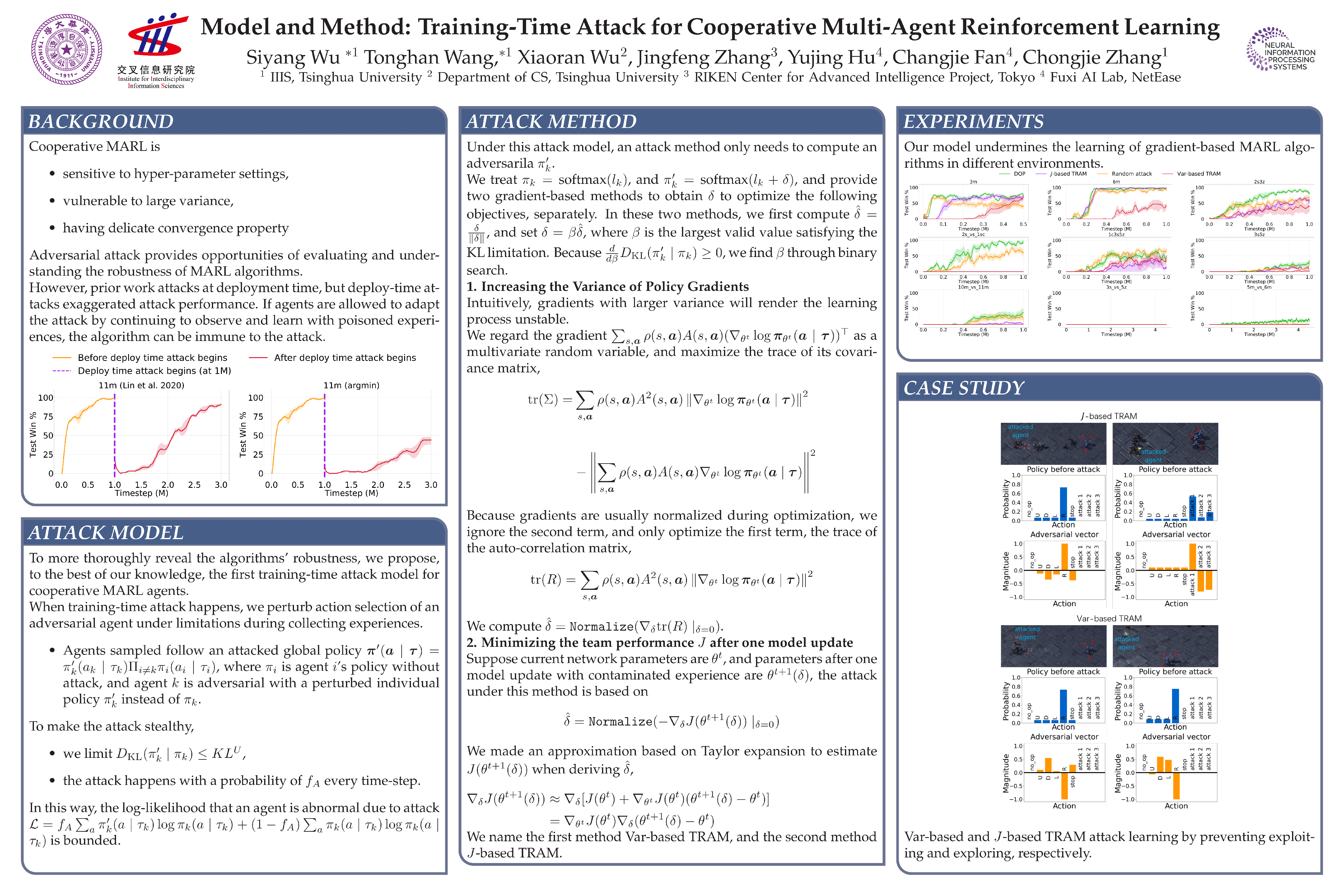
Model and Method: Training-Time Attack for Cooperative Multi-Agent Reinforcement Learning
{kind=link}
None
Planning Immediate Landmarks of Targets for Model-Free Skill Transfer across Agents
[
OpenReview]
[
Topia]
None
Confidence-Conditioned Value Functions for Offline Reinforcement Learning
[
OpenReview]
[
Topia]
None
A General Framework for Sample-Efficient Function Approximation in Reinforcement Learning
{kind=link}
None
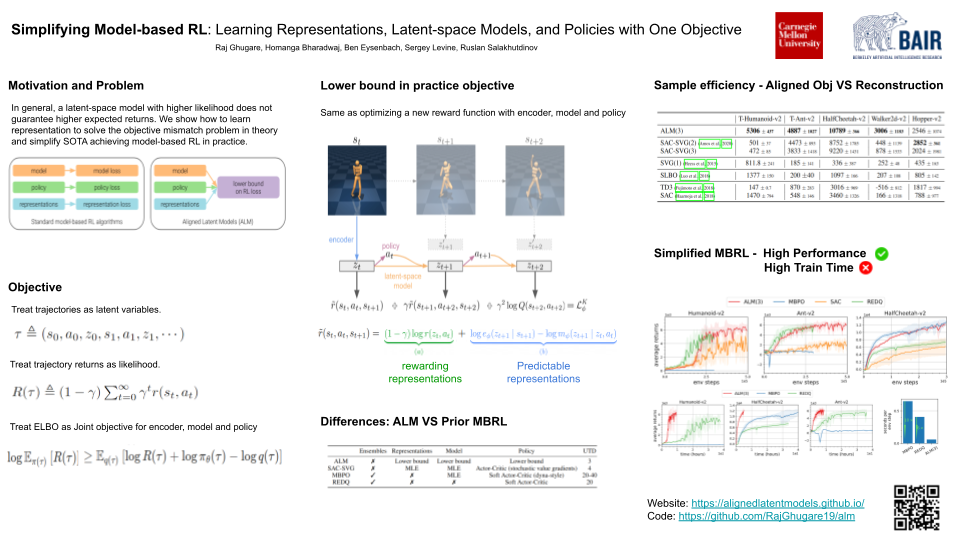
Simplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective
{kind=link}
None
Learning Successor Feature Representations to Train Robust Policies for Multi-task Learning
{kind=link}
None
Compositional Task Generalization with Modular Successor Feature Approximators
[
OpenReview]
[
Topia]
None
Deconfounded Imitation Learning
{kind=link}
None
DRL-EPANET: Deep reinforcement learning for optimal control at scale in Water Distribution Systems
[
OpenReview]
[
Topia]
None
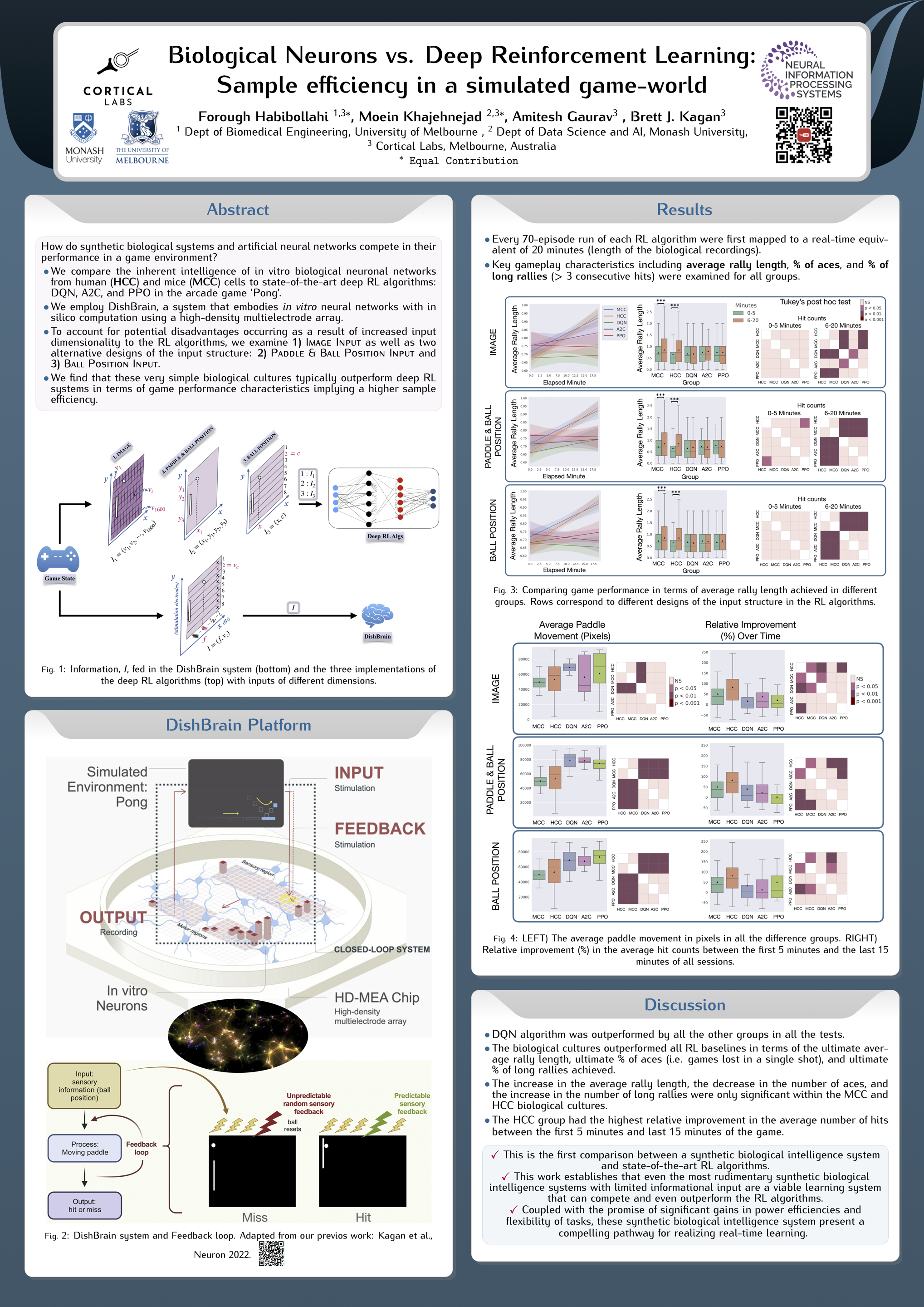
Biological Neurons vs Deep Reinforcement Learning: Sample efficiency in a simulated game-world
{kind=link}
None
Dynamic Collaborative Multi-Agent Reinforcement Learning Communication for Autonomous Drone Reforestation
{kind=link}
None
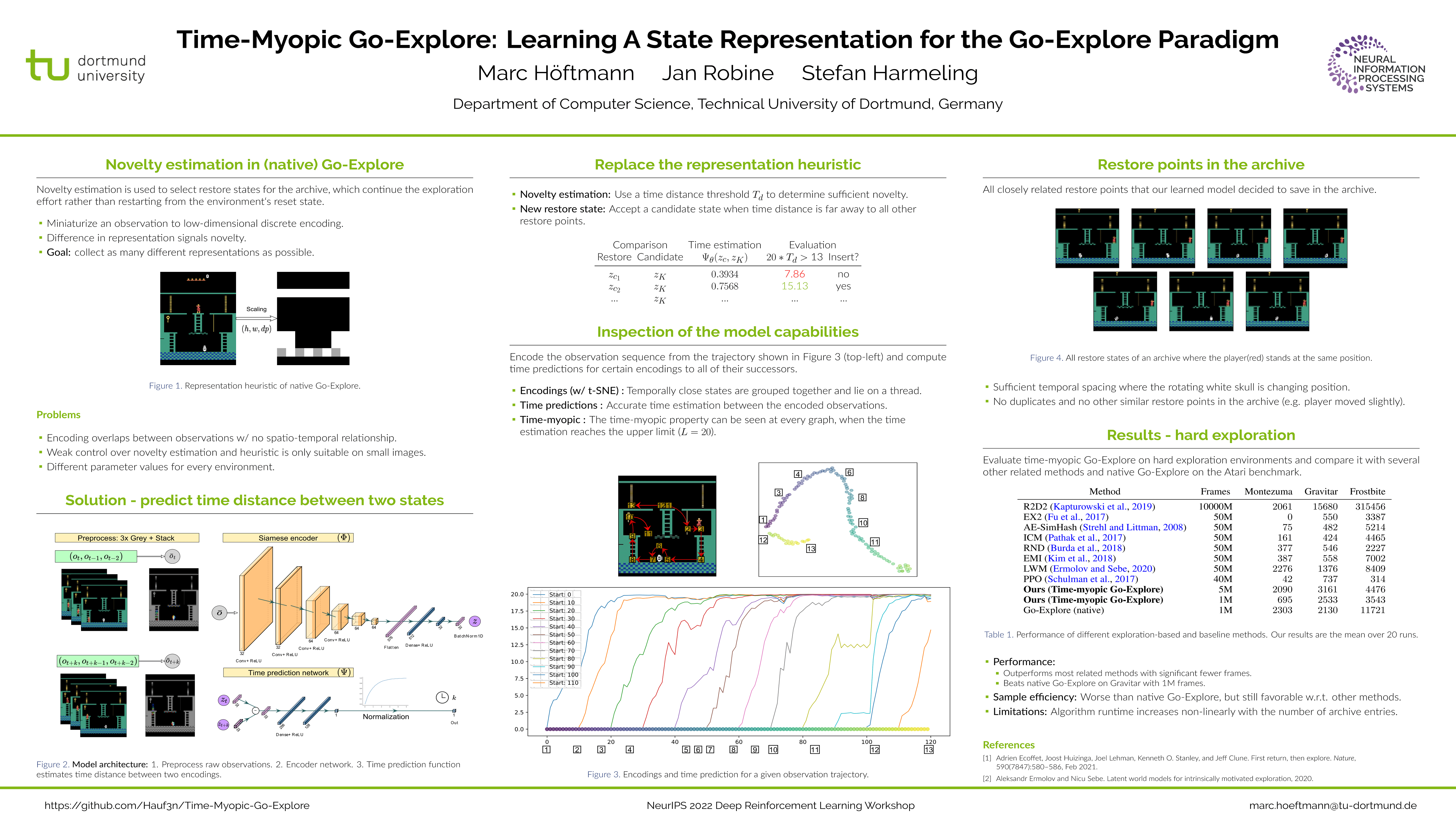
Time-Myopic Go-Explore: Learning A State Representation for the Go-Explore Paradigm
{kind=link}
None
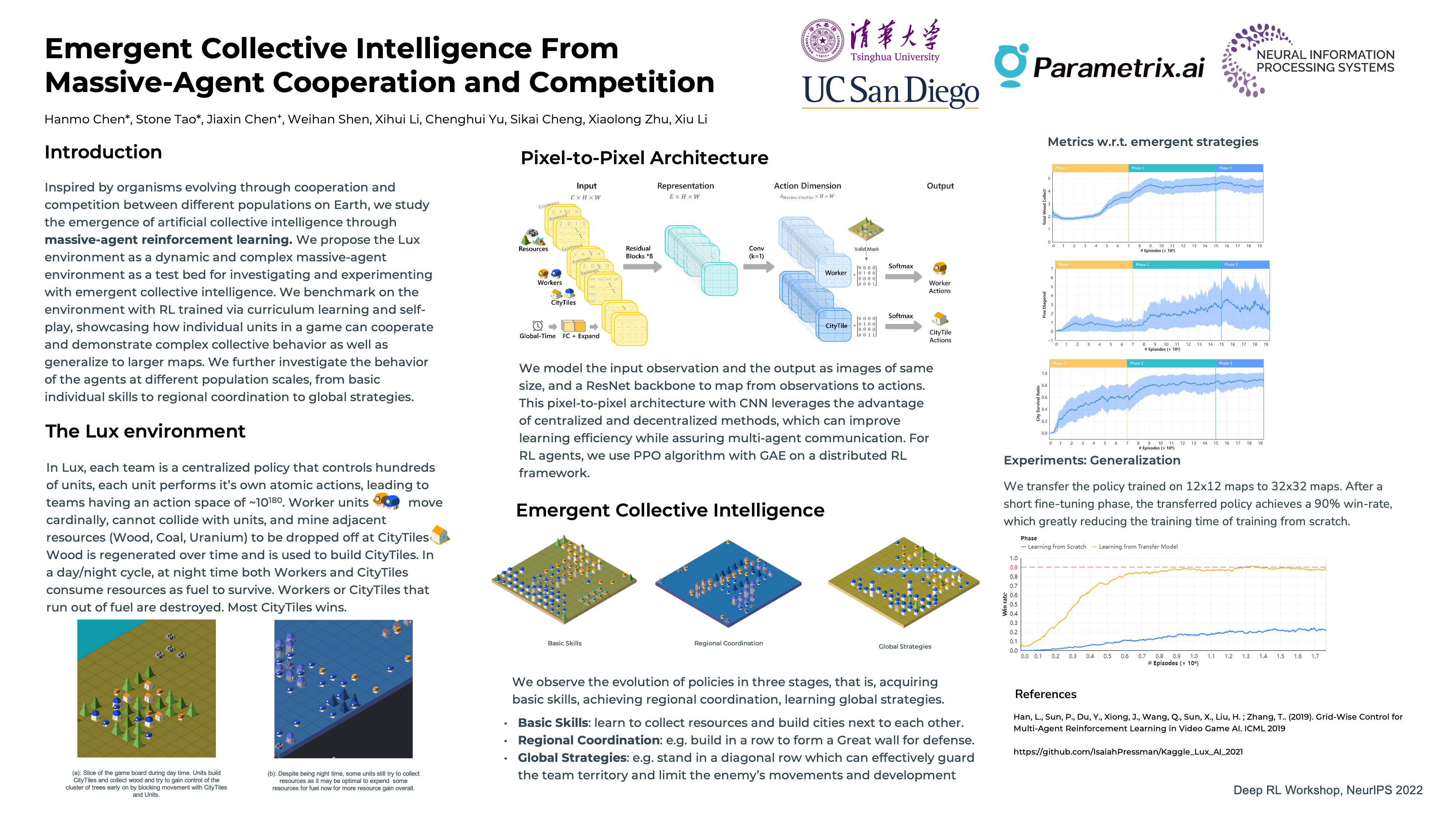
Emergent collective intelligence from massive-agent cooperation and competition
{kind=link}
None
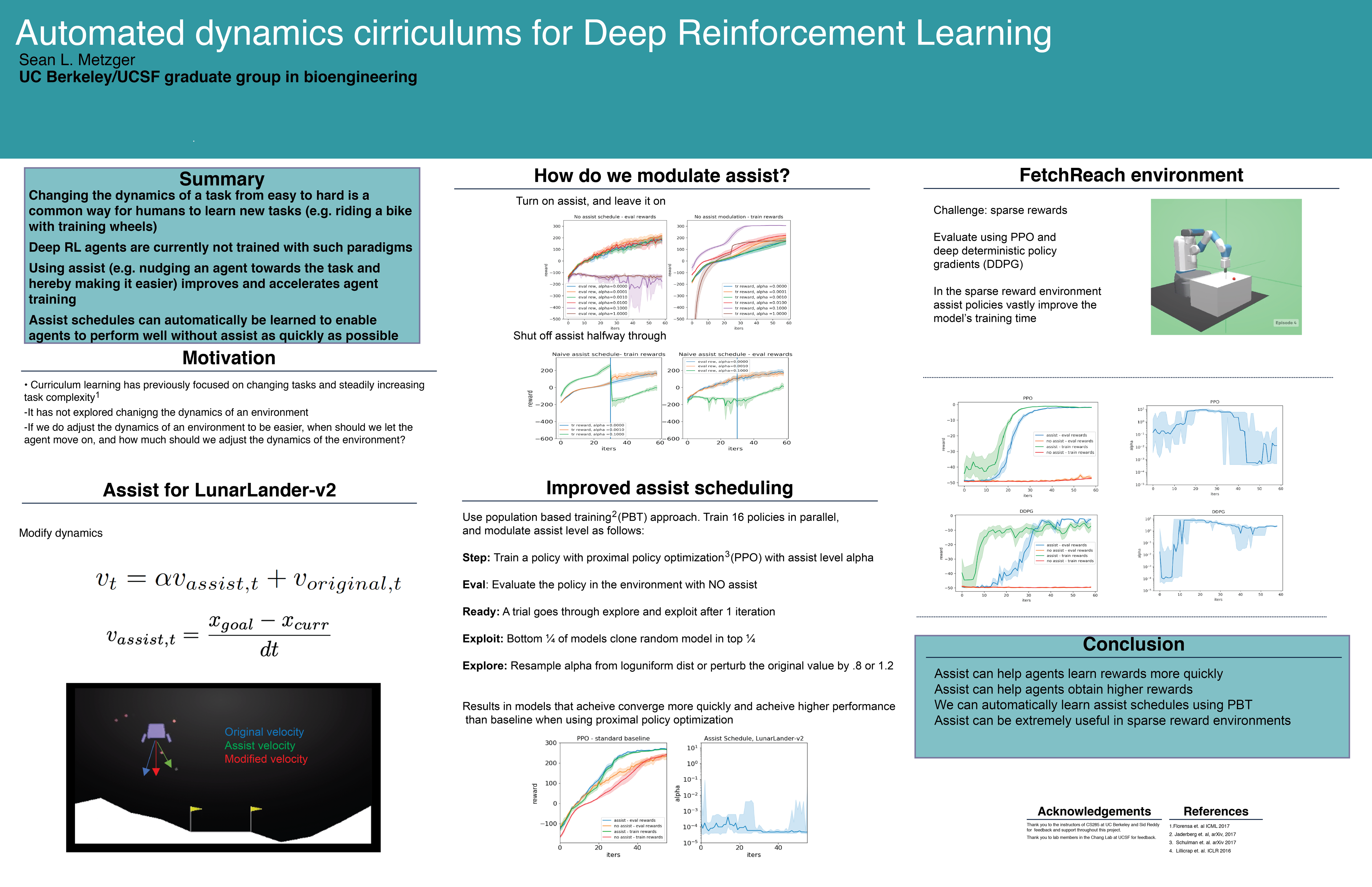
Automated Dynamics Curriculums for Deep Reinforcement Learning
{kind=link}
None
Momentum Boosted Episodic Memory for Improving Learning in Long-Tailed RL Environments
{kind=link}
None
Implicit Offline Reinforcement Learning via Supervised Learning
{kind=link}
None
Neural All-Pairs Shortest Path for Reinforcement Learning
{kind=link}
None
On the Feasibility of Cross-Task Transfer with Model-Based Reinforcement Learning
{kind=link}
None
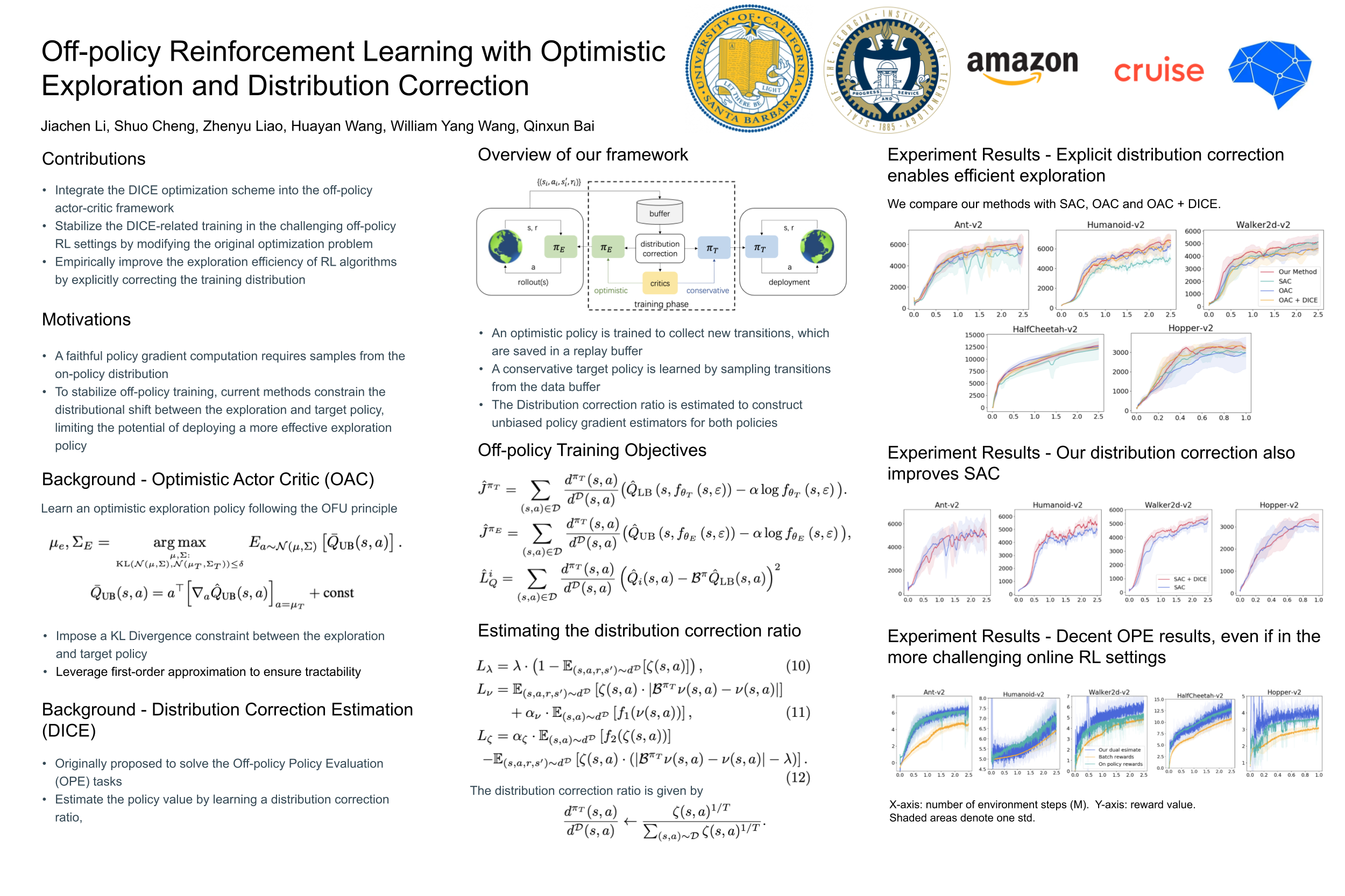
Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction
{kind=link}
None
Scaling Covariance Matrix Adaptation MAP-Annealing to High-Dimensional Controllers
{kind=link}
None
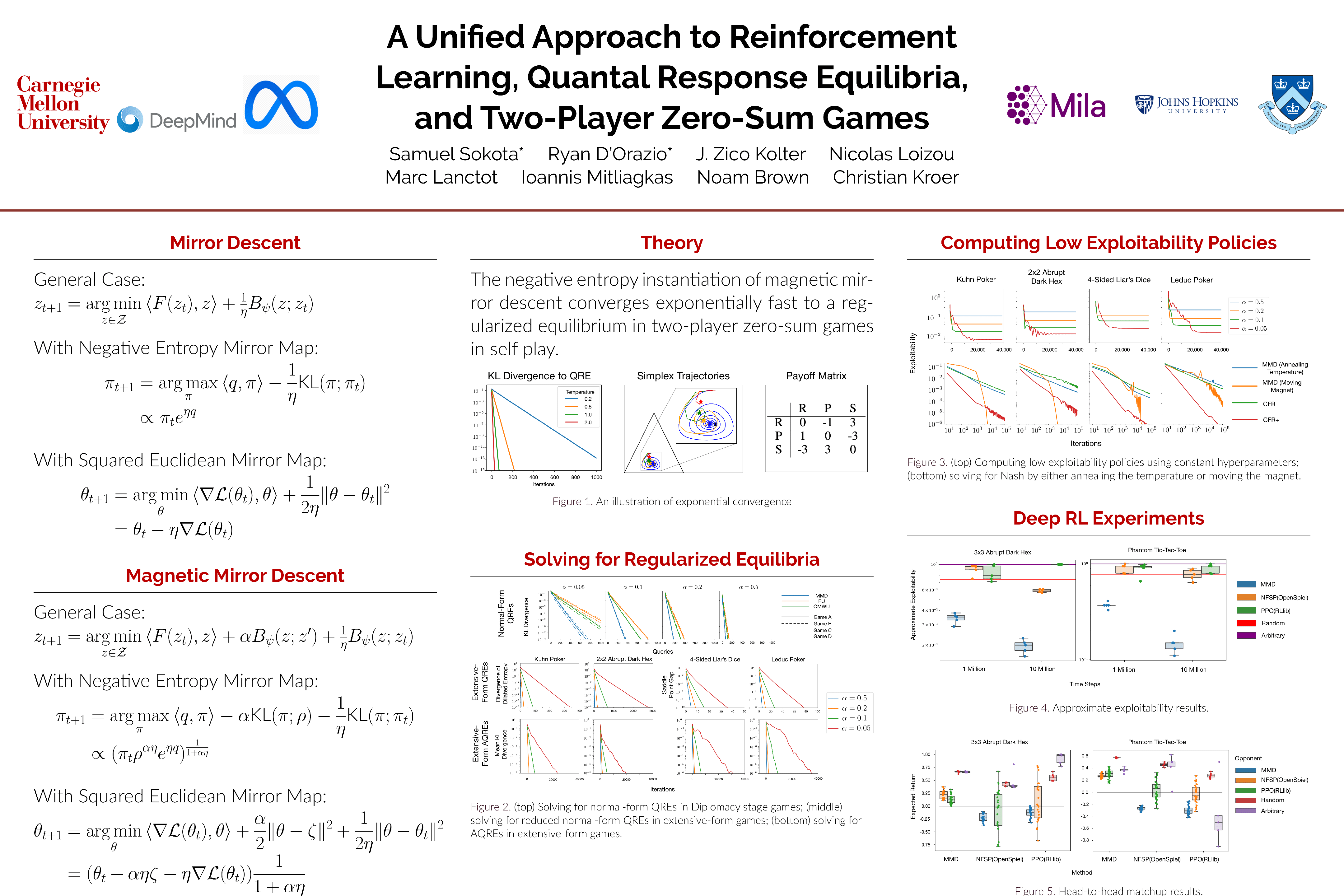
A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games
{kind=link}
None
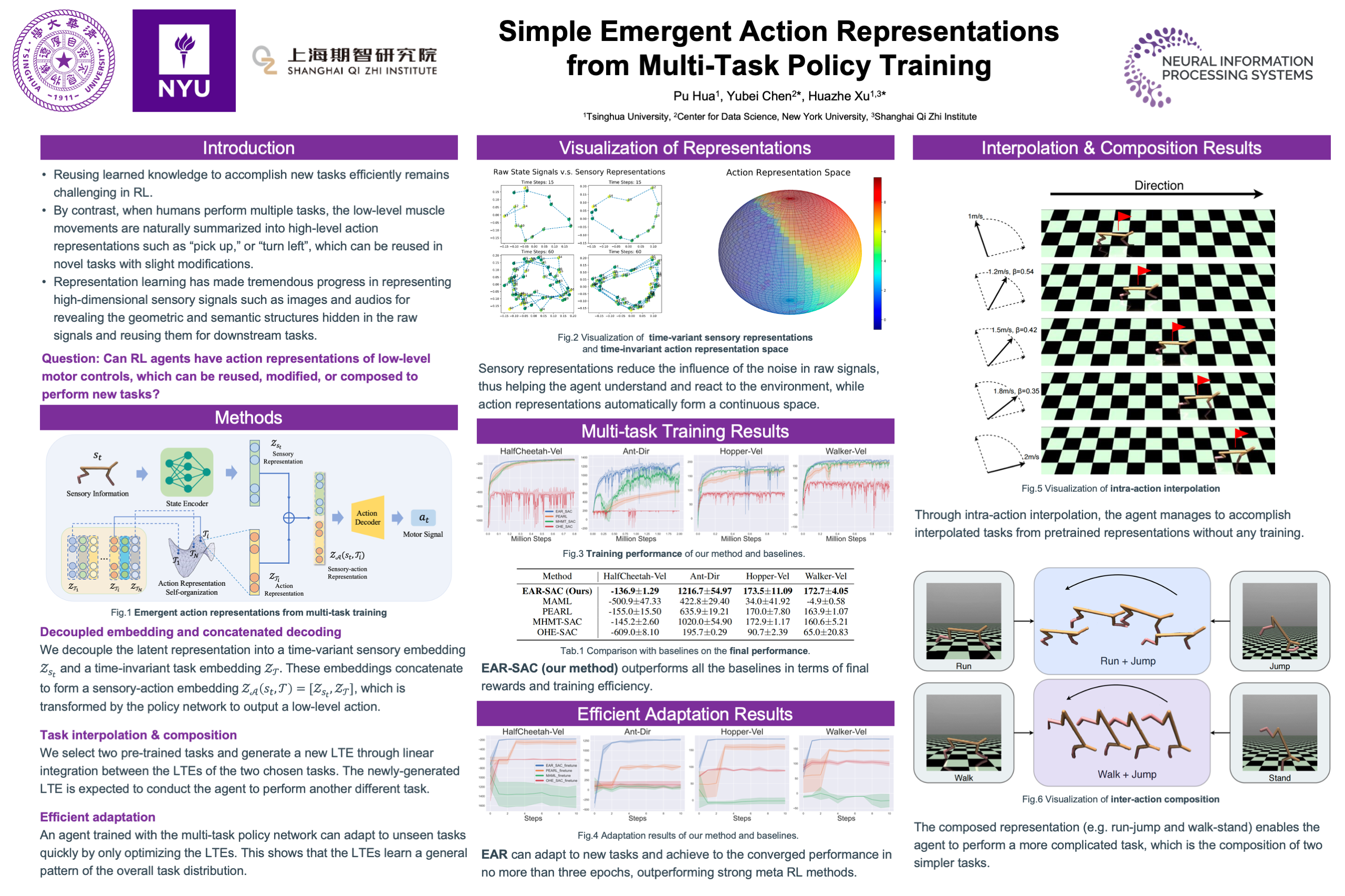
Simple Emergent Action Representations from Multi-Task Policy Training
{kind=link}
None
Rethinking Learning Dynamics in RL using Adversarial Networks
{kind=link}
None
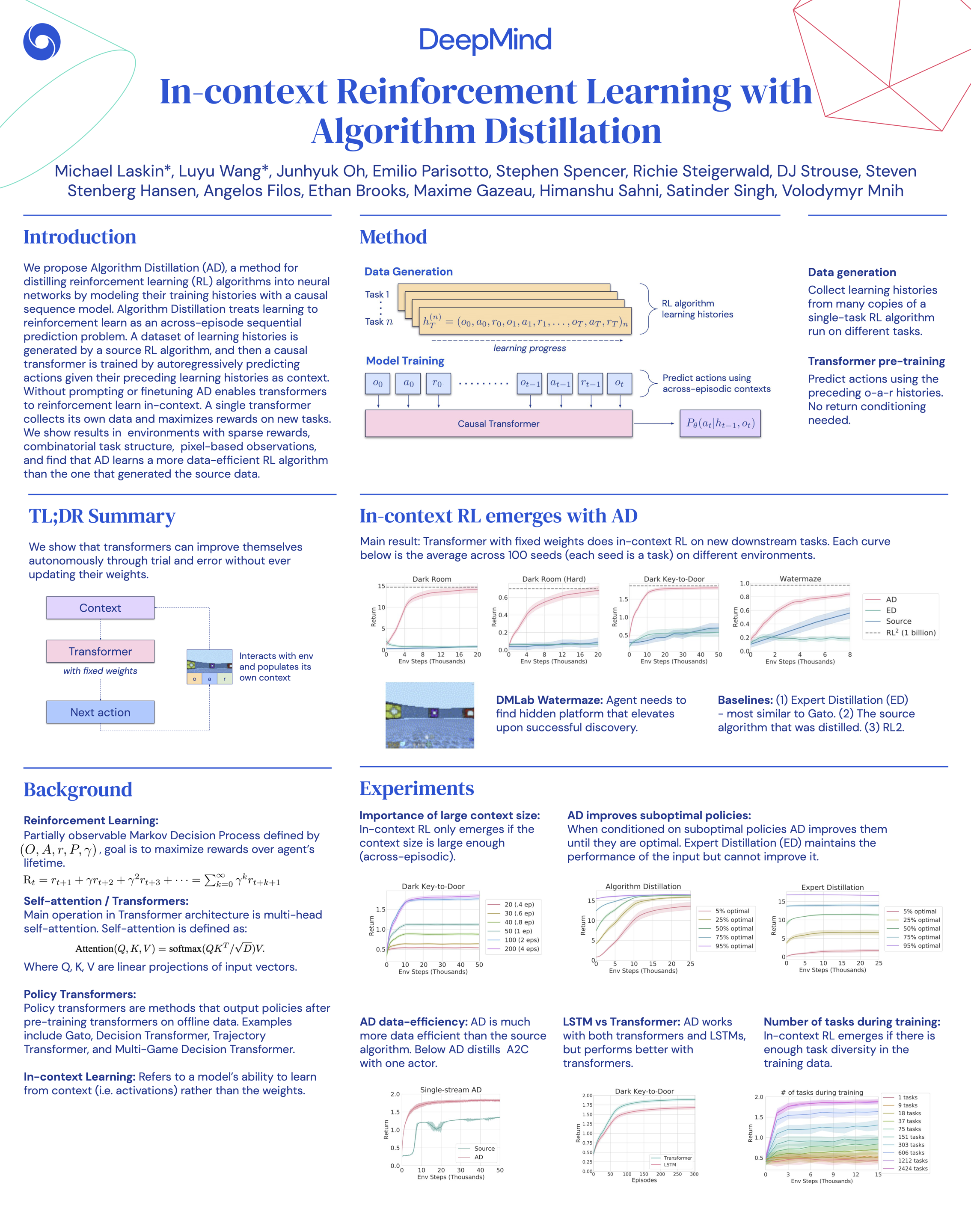
In-context Reinforcement Learning with Algorithm Distillation
{kind=link}
None
SEM2: Enhance Sample Efficiency and Robustness of End-to-end Urban Autonomous Driving via Semantic Masked World Model
{kind=link}
None
Noisy Symbolic Abstractions for Deep RL: A case study with Reward Machines
{kind=link}
None
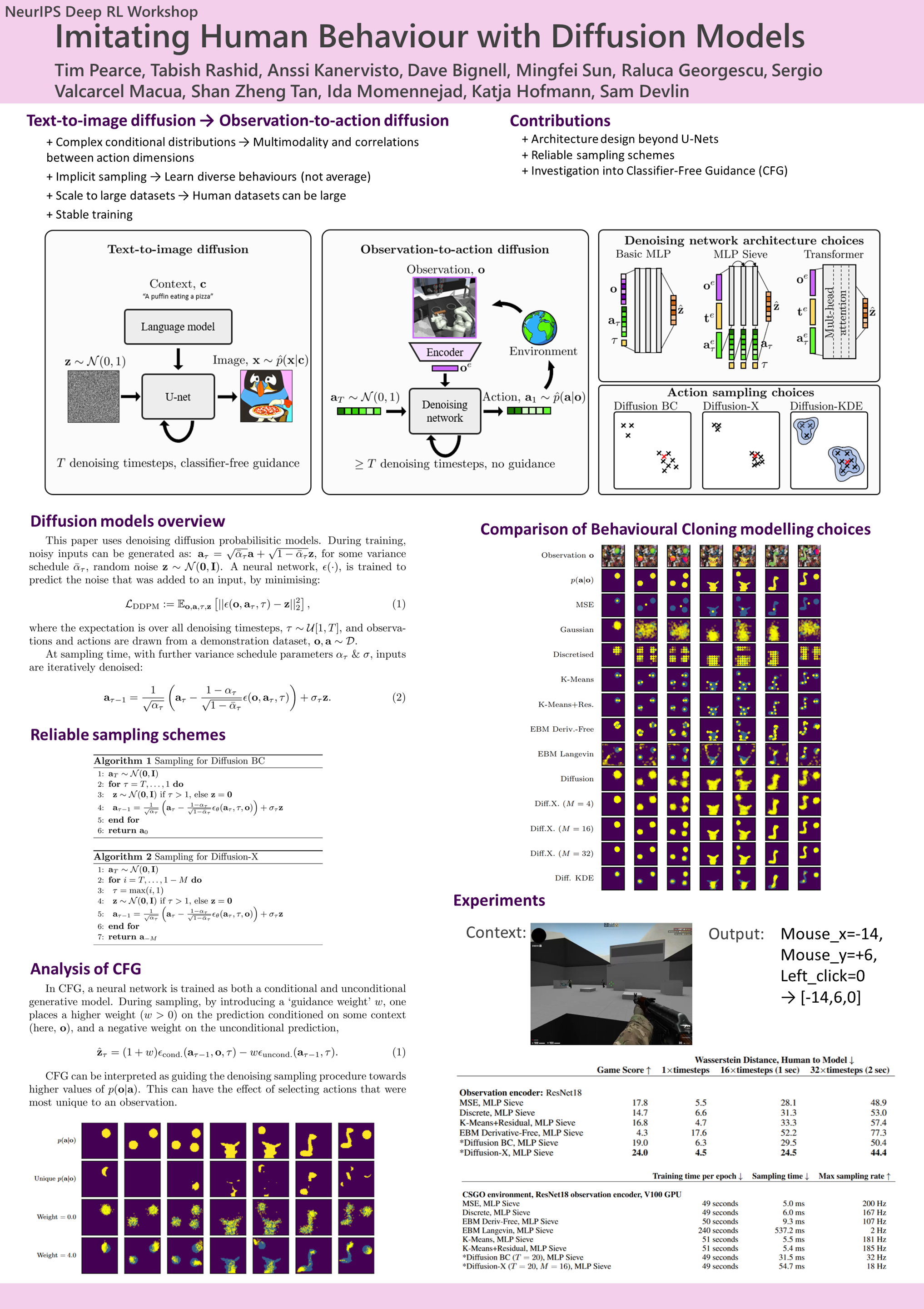
Imitating Human Behaviour with Diffusion Models
{kind=link}
Successful Page Load