Intrinsic Self-Supervision for Data Quality Audits
{kind=link}
Abstract
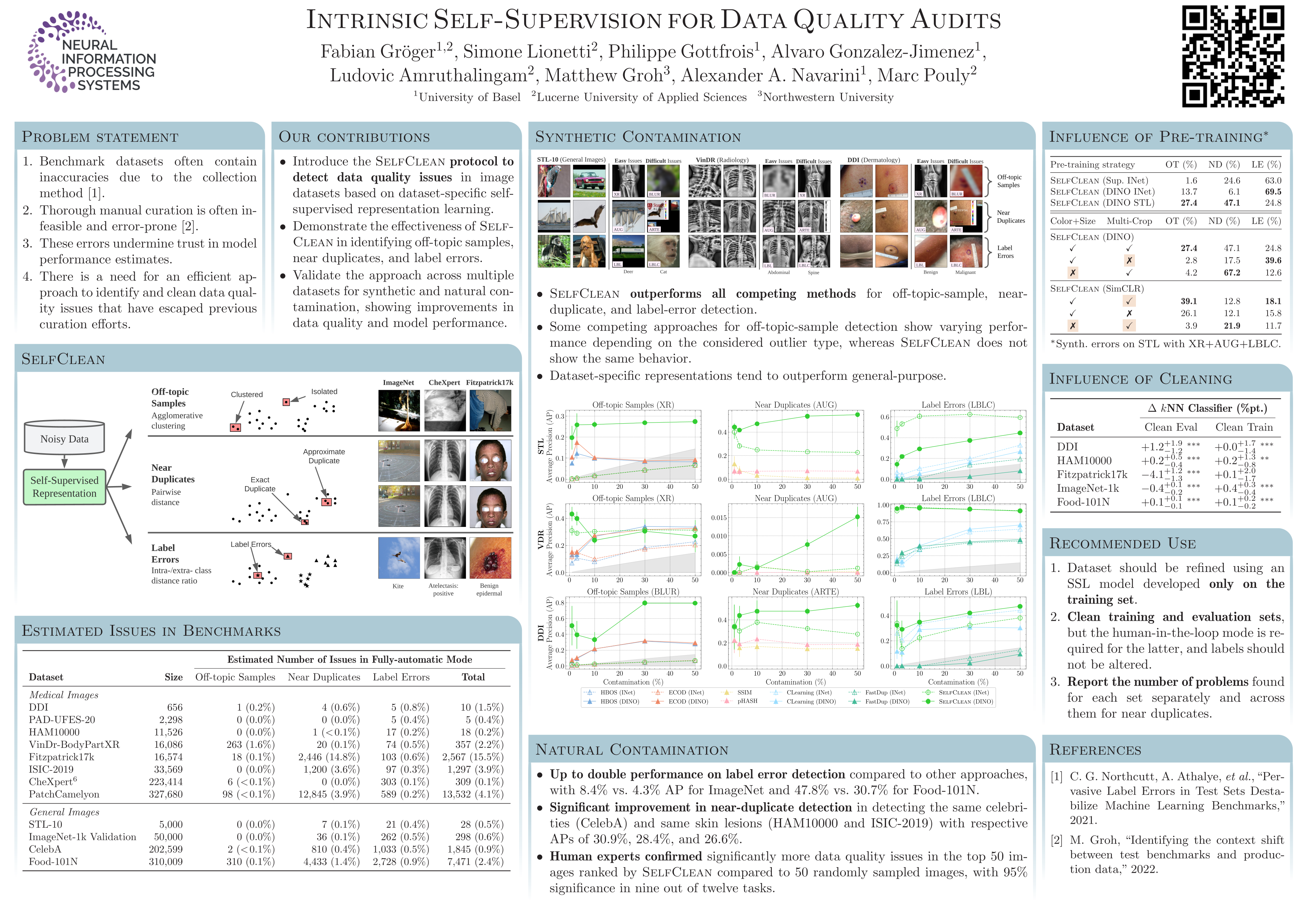
Benchmark datasets in computer vision often contain off-topic images, near duplicates, and label errors, leading to inaccurate estimates of model performance.In this paper, we revisit the task of data cleaning and formalize it as either a ranking problem, which significantly reduces human inspection effort, or a scoring problem, which allows for automated decisions based on score distributions.We find that a specific combination of context-aware self-supervised representation learning and distance-based indicators is effective in finding issues without annotation biases.This methodology, which we call SelfClean, surpasses state-of-the-art performance in detecting off-topic images, near duplicates, and label errors within widely-used image datasets, such as ImageNet-1k, Food-101N, and STL-10, both for synthetic issues and real contamination.We apply the detailed method to multiple image benchmarks, identify up to 16% of issues, and confirm an improvement in evaluation reliability upon cleaning.The official implementation can be found at: https://github.com/Digital-Dermatology/SelfClean.