SA3DIP: Segment Any 3D Instance with Potential 3D Priors
{kind=link}
Abstract
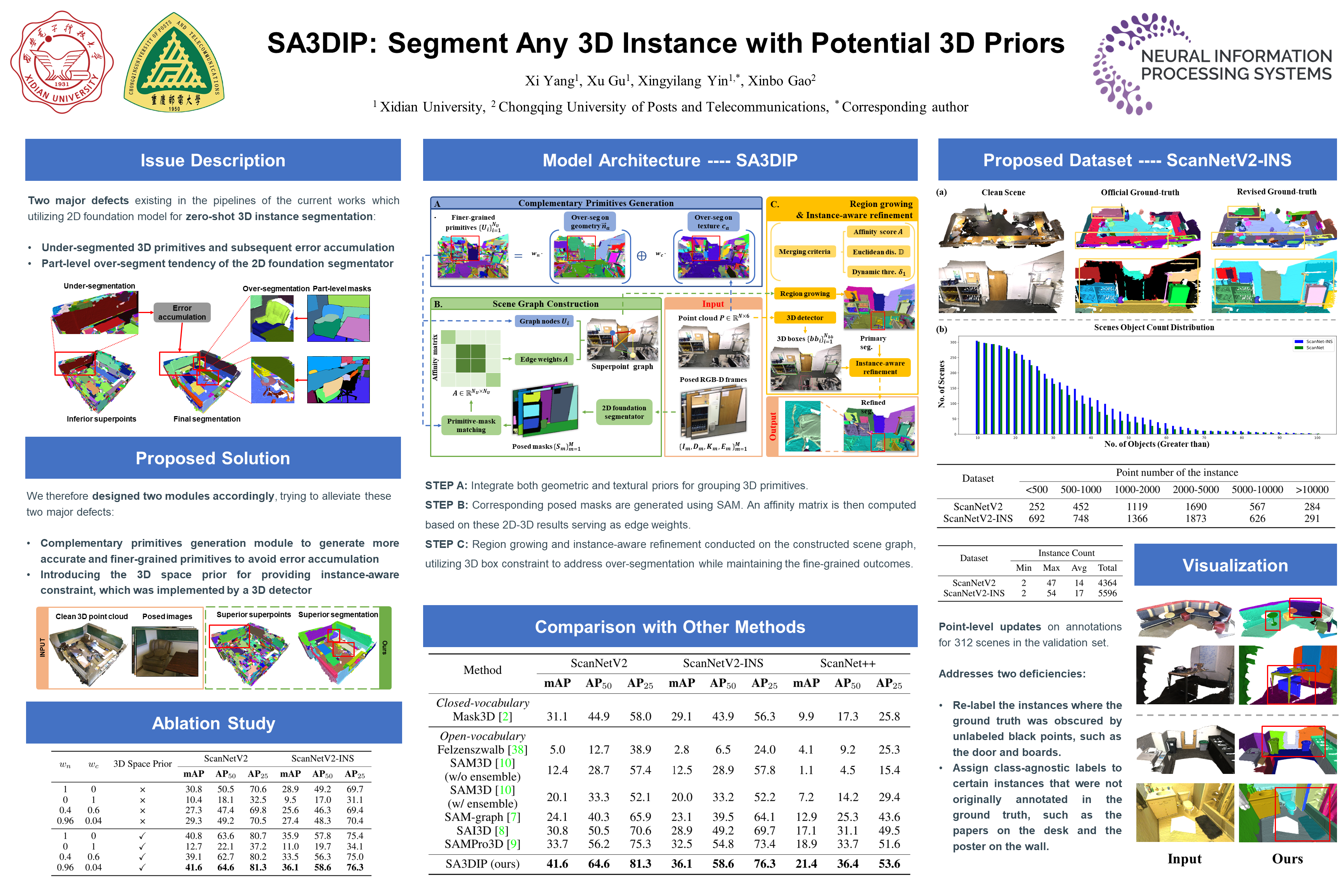
The proliferation of 2D foundation models has sparked research into adapting them for open-world 3D instance segmentation. Recent methods introduce a paradigm that leverages superpoints as geometric primitives and incorporates 2D multi-view masks from Segment Anything model (SAM) as merging guidance, achieving outstanding zero-shot instance segmentation results. However, the limited use of 3D priors restricts the segmentation performance. Previous methods calculate the 3D superpoints solely based on estimated normal from spatial coordinates, resulting in under-segmentation for instances with similar geometry. Besides, the heavy reliance on SAM and hand-crafted algorithms in 2D space suffers from over-segmentation due to SAM's inherent part-level segmentation tendency. To address these issues, we propose SA3DIP, a novel method for Segmenting Any 3D Instances via exploiting potential 3D Priors. Specifically, on one hand, we generate complementary 3D primitives based on both geometric and textural priors, which reduces the initial errors that accumulate in subsequent procedures. On the other hand, we introduce supplemental constraints from the 3D space by using a 3D detector to guide a further merging process. Furthermore, we notice a considerable portion of low-quality ground truth annotations in ScanNetV2 benchmark, which affect the fair evaluations. Thus, we present ScanNetV2-INS with complete ground truth labels and supplement additional instances for 3D class-agnostic instance segmentation. Experimental evaluations on various 2D-3D datasets demonstrate the effectiveness and robustness of our approach. Our code and proposed ScanNetV2-INS dataset are available HERE.