Flipping-based Policy for Chance-Constrained Markov Decision Processes
{kind=link}
Abstract
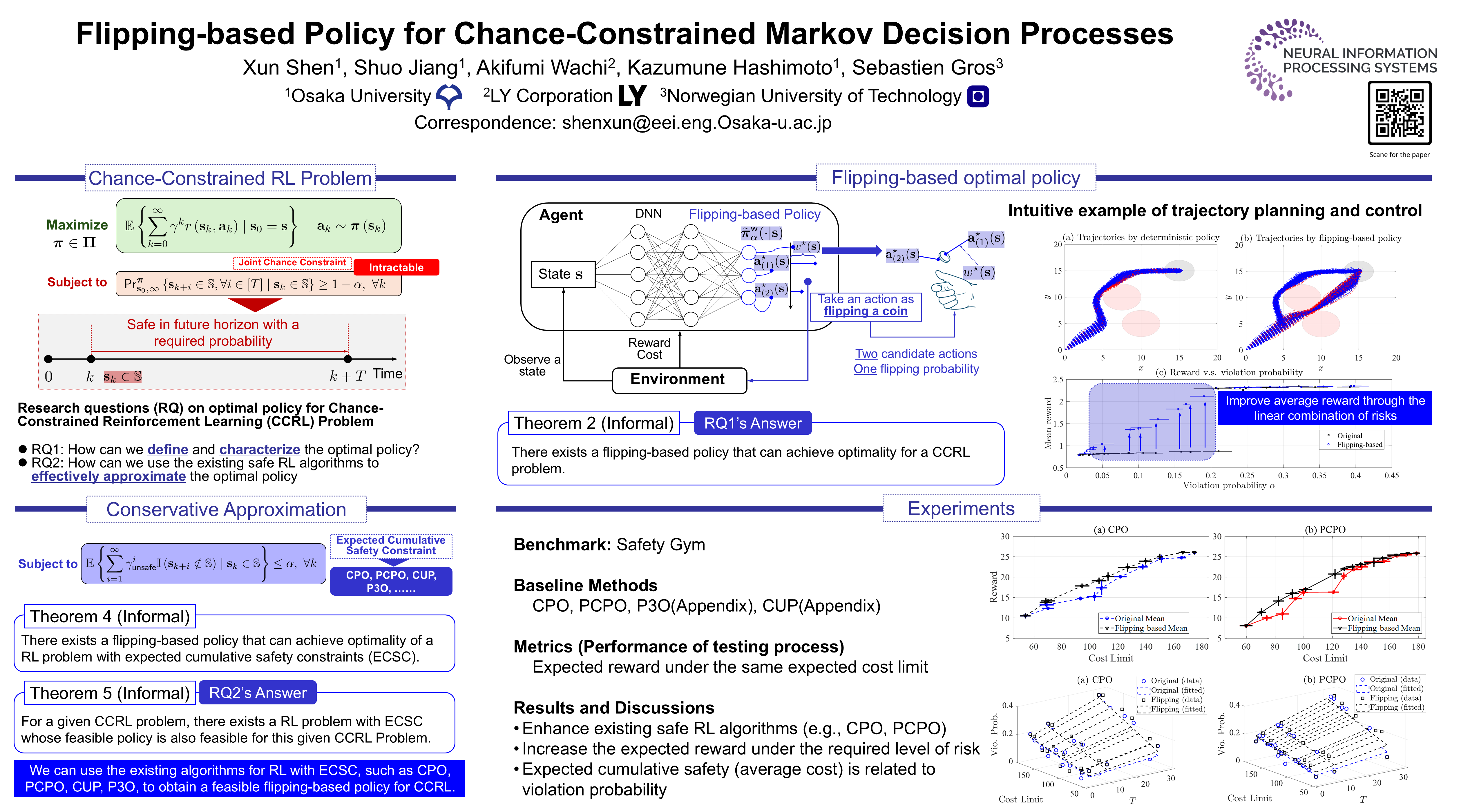
Safe reinforcement learning (RL) is a promising approach for many real-world decision-making problems where ensuring safety is a critical necessity. In safe RL research, while expected cumulative safety constraints (ECSCs) are typically the first choices, chance constraints are often more pragmatic for incorporating safety under uncertainties. This paper proposes a \textit{flipping-based policy} for Chance-Constrained Markov Decision Processes (CCMDPs). The flipping-based policy selects the next action by tossing a potentially distorted coin between two action candidates. The probability of the flip and the two action candidates vary depending on the state. We establish a Bellman equation for CCMDPs and further prove the existence of a flipping-based policy within the optimal solution sets. Since solving the problem with joint chance constraints is challenging in practice, we then prove that joint chance constraints can be approximated into Expected Cumulative Safety Constraints (ECSCs) and that there exists a flipping-based policy in the optimal solution sets for constrained MDPs with ECSCs. As a specific instance of practical implementations, we present a framework for adapting constrained policy optimization to train a flipping-based policy. This framework can be applied to other safe RL algorithms. We demonstrate that the flipping-based policy can improve the performance of the existing safe RL algorithms under the same limits of safety constraints on Safety Gym benchmarks.