Decomposed Prompt Decision Transformer for Efficient Unseen Task Generalization
{kind=link}
Abstract
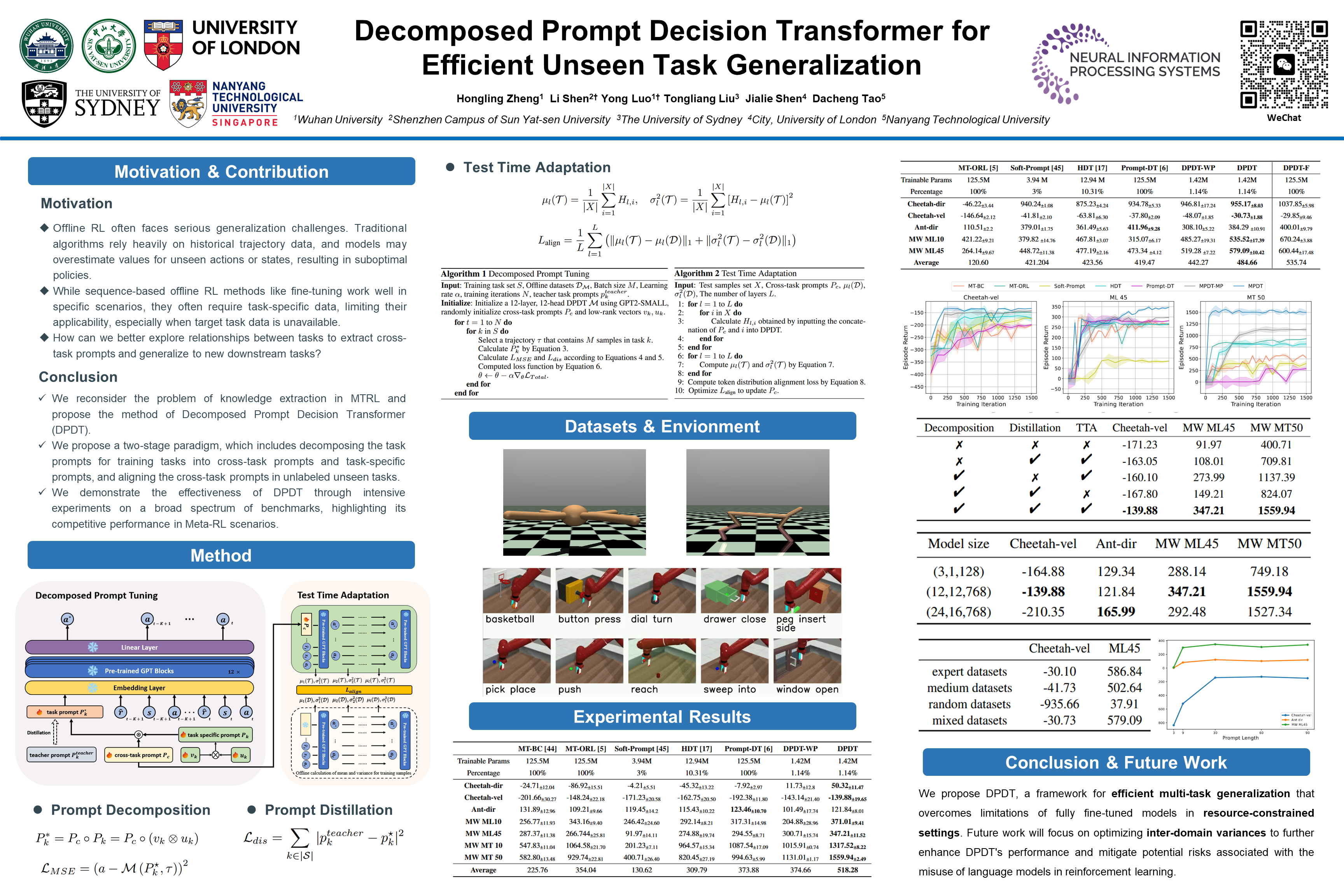
Multi-task offline reinforcement learning aims to develop a unified policy for diverse tasks without requiring real-time interaction with the environment. Recent work explores sequence modeling, leveraging the scalability of the transformer architecture as a foundation for multi-task learning. Given the variations in task content and complexity, formulating policies becomes a challenging endeavor, requiring careful parameter sharing and adept management of conflicting gradients to extract rich cross-task knowledge from multiple tasks and transfer it to unseen tasks. In this paper, we propose the Decomposed Prompt Decision Transformer (DPDT) that adopts a two-stage paradigm to efficiently learn prompts for unseen tasks in a parameter-efficient manner. We incorporate parameters from pre-trained language models (PLMs) to initialize DPDT, thereby providing rich prior knowledge encoded in language models. During the decomposed prompt tuning phase, we learn both cross-task and task-specific prompts on training tasks to achieve prompt decomposition. In the test time adaptation phase, the cross-task prompt, serving as a good initialization, were further optimized on unseen tasks through test time adaptation, enhancing the model's performance on these tasks. Empirical evaluation on a series of Meta-RL benchmarks demonstrates the superiority of our approach. The project is available at https://github.com/ruthless-man/DPDT.