Structured Unrestricted-Rank Matrices for Parameter Efficient Finetuning
{kind=link}
Abstract
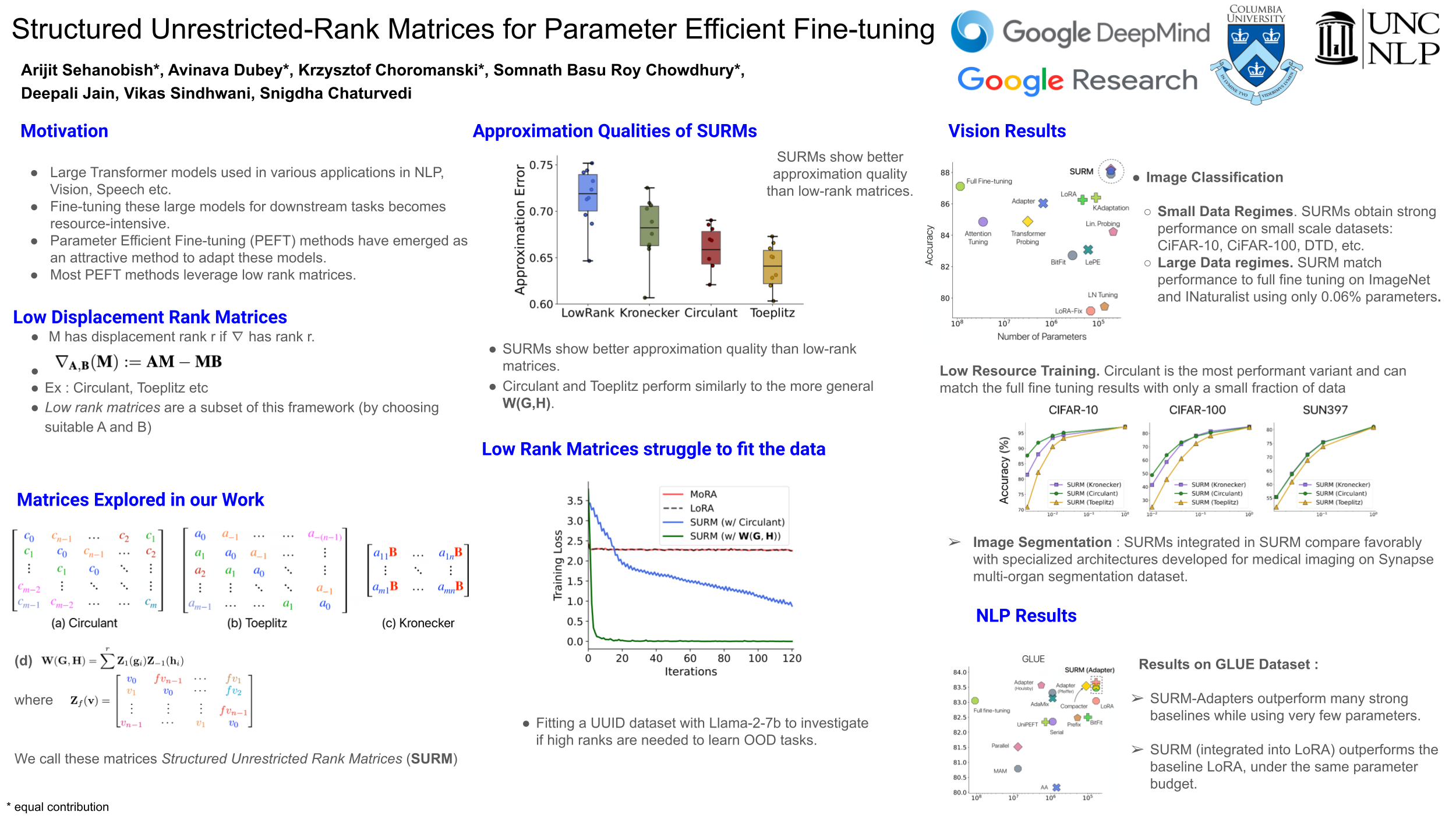
Recent efforts to scale Transformer models have demonstrated rapid progress across a wide range of tasks (Wei at. al 2022). However, fine-tuning these models for downstream tasks is quite expensive due to their large parameter counts. Parameter-efficient fine-tuning (PEFT) approaches have emerged as a viable alternative, allowing us to fine-tune models by updating only a small number of parameters. In this work, we propose a general framework for parameter efficient fine-tuning (PEFT), based on structured unrestricted-rank matrices (SURM) which can serve as a drop-in replacement for popular approaches such as Adapters and LoRA. Unlike other methods like LoRA, SURMs give us more flexibility in finding the right balance between compactness and expressiveness. This is achieved by using low displacement rank matrices (LDRMs), which hasn't been used in this context before. SURMs remain competitive with baselines, often providing significant quality improvements while using a smaller parameter budget. SURMs achieve: 5-7% accuracy gains on various image classification tasks while replacing low-rank matrices in LoRA and: up to 12x reduction of the number of parameters in adapters (with virtually no loss in quality) on the GLUE benchmark.