Q-Distribution guided Q-learning for offline reinforcement learning: Uncertainty penalized Q-value via consistency model
{kind=link}
Abstract
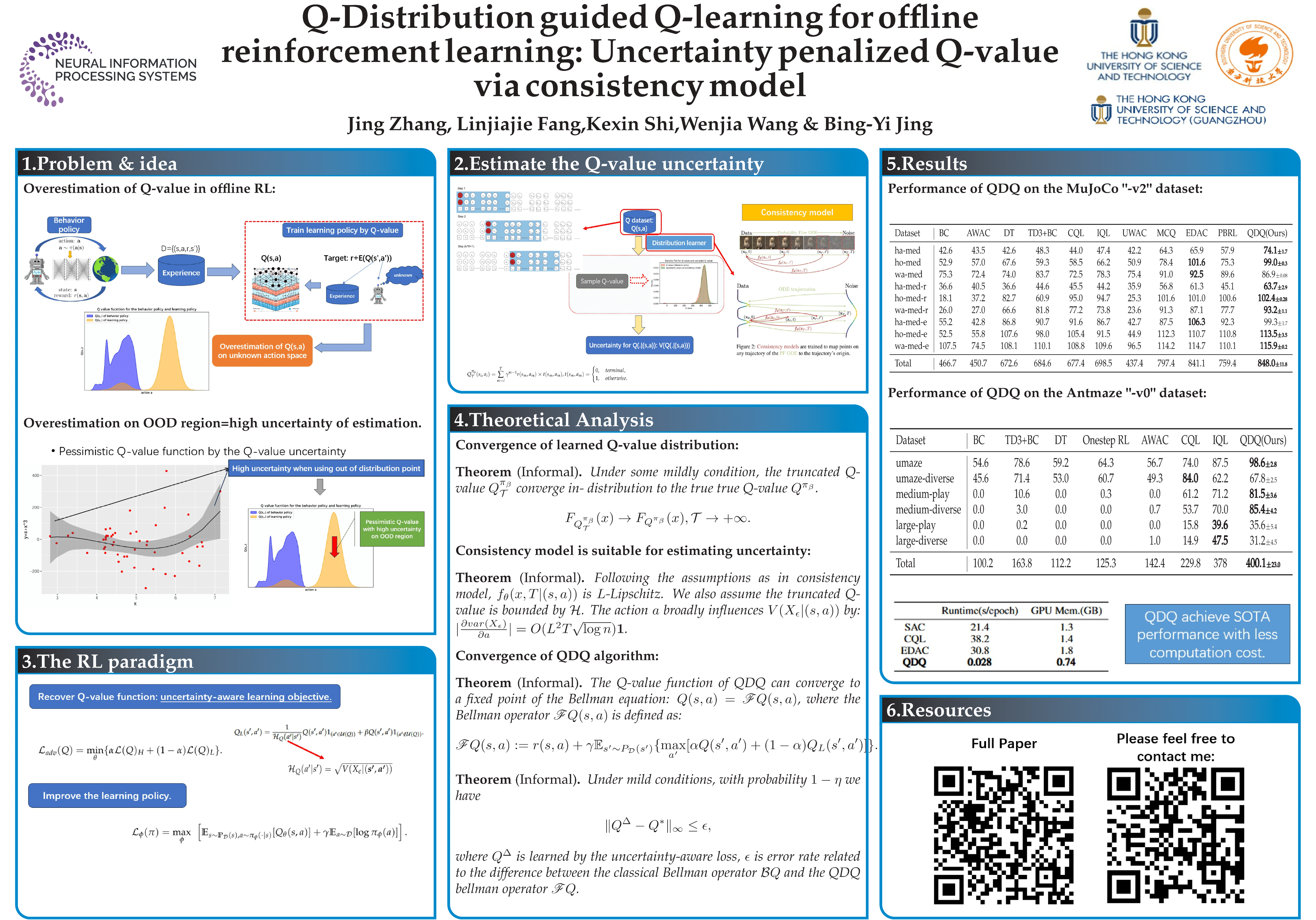
``Distribution shift'' is the primary obstacle to the success of offline reinforcement learning. As a learning policy may take actions beyond the knowledge of the behavior policy (referred to as Out-of-Distribution (OOD) actions), the Q-values of these OOD actions can be easily overestimated. Consequently, the learning policy becomes biasedly optimized using the incorrect recovered Q-value function. One commonly used idea to avoid the overestimation of Q-value is to make a pessimistic adjustment. Our key idea is to penalize the Q-values of OOD actions that correspond to high uncertainty. In this work, we propose Q-Distribution guided Q-learning (QDQ) which pessimistic Q-value on OOD regions based on uncertainty estimation. The uncertainty measure is based on the conditional Q-value distribution, which is learned via a high-fidelity and efficient consistency model. On the other hand, to avoid the overly conservative problem, we introduce an uncertainty-aware optimization objective to update the Q-value function. The proposed QDQ demonstrates solid theoretical guarantees for the accuracy of Q-value distribution learning and uncertainty measurement, as well as the performance of the learning policy. QDQ consistently exhibits strong performance in the D4RL benchmark and shows significant improvements for many tasks. Our code can be found at .