VQ-Map: Bird's-Eye-View Map Layout Estimation in Tokenized Discrete Space via Vector Quantization
{kind=link}
Abstract
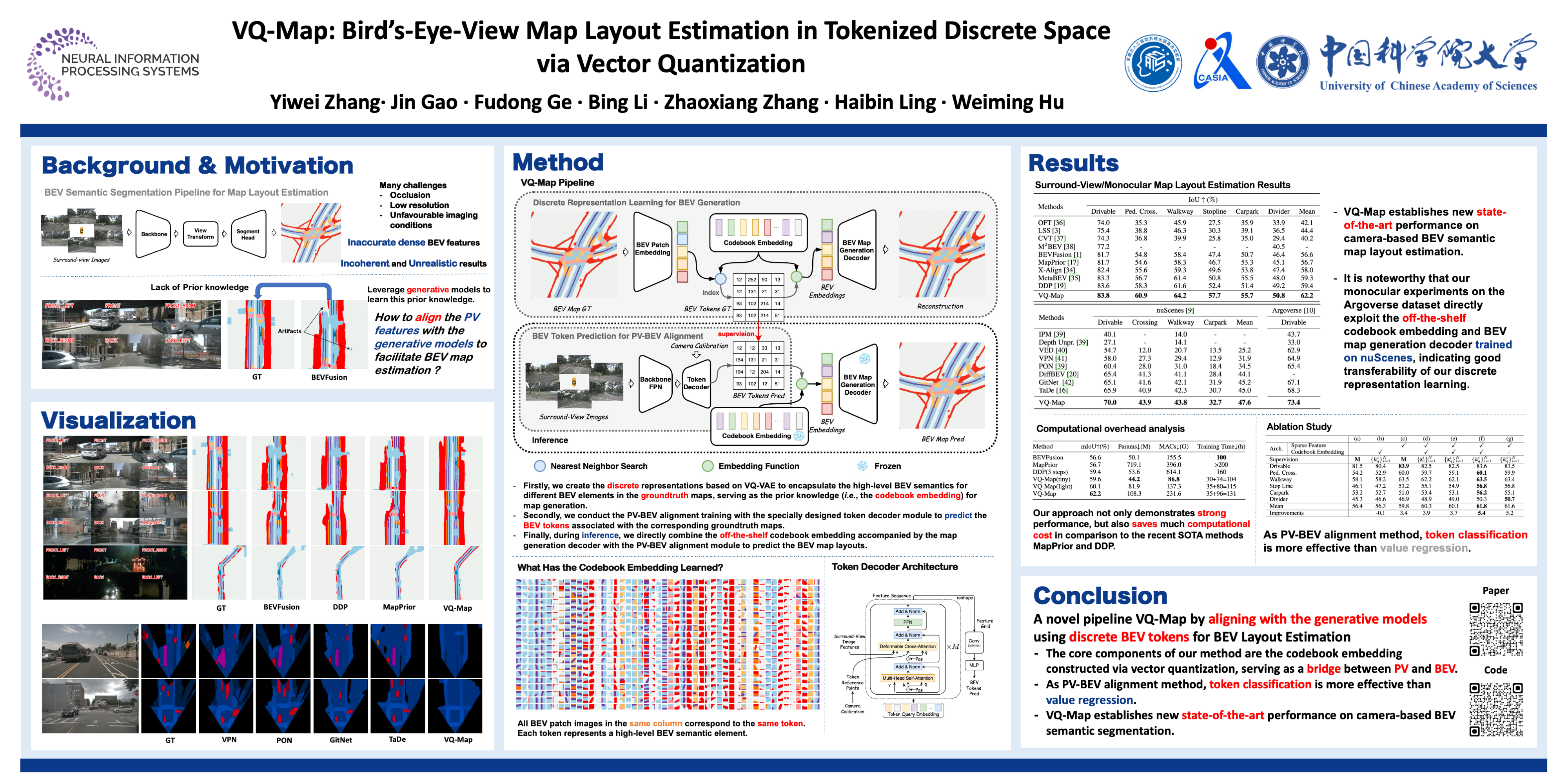
Bird's-eye-view (BEV) map layout estimation requires an accurate and full understanding of the semantics for the environmental elements around the ego car to make the results coherent and realistic. Due to the challenges posed by occlusion, unfavourable imaging conditions and low resolution, \emph{generating} the BEV semantic maps corresponding to corrupted or invalid areas in the perspective view (PV) is appealing very recently. \emph{The question is how to align the PV features with the generative models to facilitate the map estimation}. In this paper, we propose to utilize a generative model similar to the Vector Quantized-Variational AutoEncoder (VQ-VAE) to acquire prior knowledge for the high-level BEV semantics in the tokenized discrete space. Thanks to the obtained BEV tokens accompanied with a codebook embedding encapsulating the semantics for different BEV elements in the groundtruth maps, we are able to directly align the sparse backbone image features with the obtained BEV tokens from the discrete representation learning based on a specialized token decoder module, and finally generate high-quality BEV maps with the BEV codebook embedding serving as a bridge between PV and BEV. We evaluate the BEV map layout estimation performance of our model, termed VQ-Map, on both the nuScenes and Argoverse benchmarks, achieving 62.2/47.6 mean IoU for surround-view/monocular evaluation on nuScenes, as well as 73.4 IoU for monocular evaluation on Argoverse, which all set a new record for this map layout estimation task. The code and models are available on \url{https://github.com/Z1zyw/VQ-Map}.