OW-VISCapTor: Abstractors for Open-World Video Instance Segmentation and Captioning
{kind=link}
Abstract
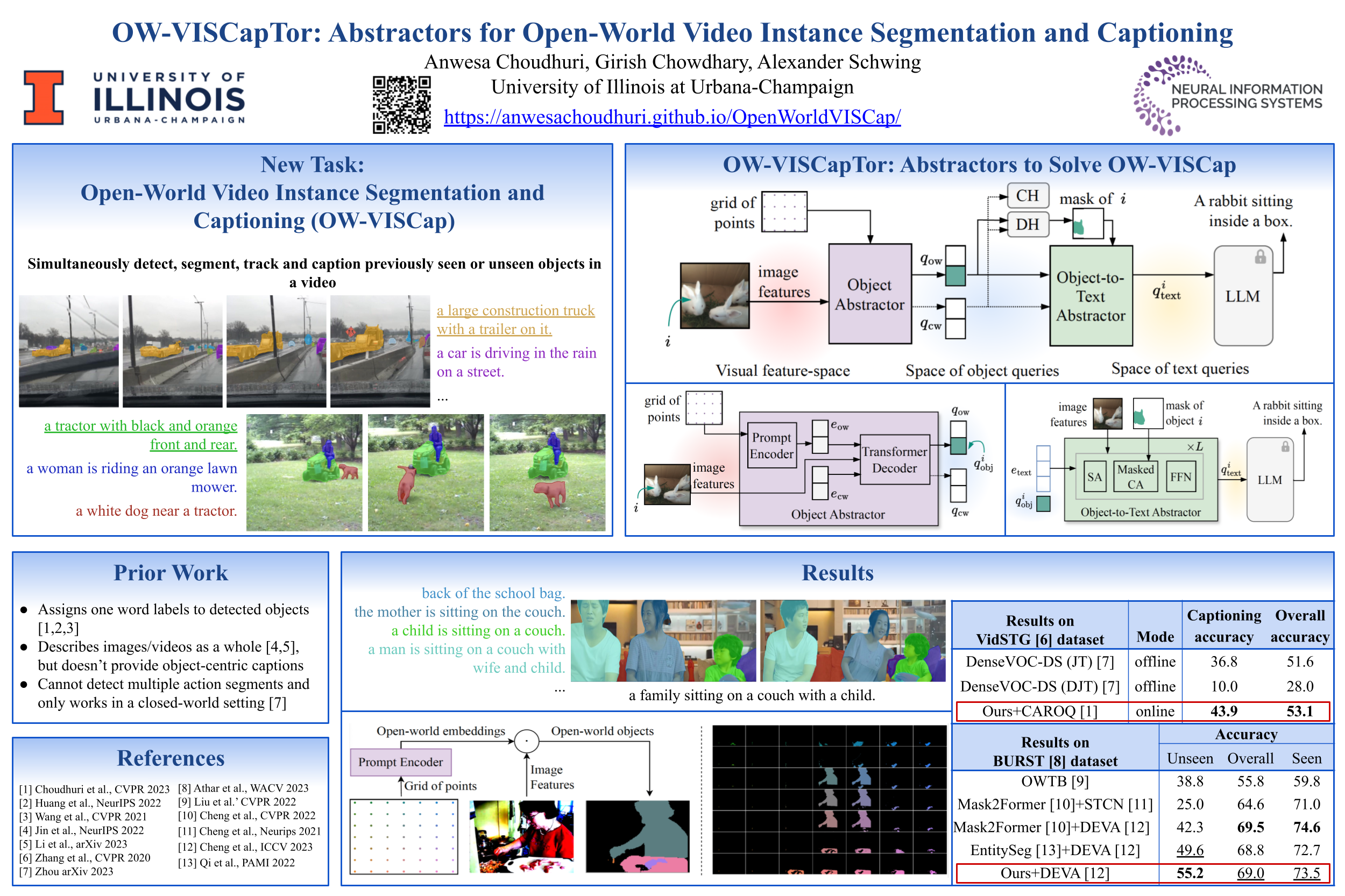
We propose the new task open-world video instance segmentation and captioning. It requires to detect, segment, track and describe with rich captions never before seen objects. This challenging task can be addressed by developing "abstractors" which connect a vision model and a language foundation model. Concretely, we connect a multi-scale visual feature extractor and a large language model (LLM) by developing an object abstractor and an object-to-text abstractor. The object abstractor, consisting of a prompt encoder and transformer blocks, introduces spatially-diverse open-world object queries to discover never before seen objects in videos. An inter-query contrastive loss further encourages the diversity of object queries. The object-to-text abstractor is augmented with masked cross-attention and acts as a bridge between the object queries and a frozen LLM to generate rich and descriptive object-centric captions for each detected object. Our generalized approach surpasses the baseline that jointly addresses the tasks of open-world video instance segmentation and dense video object captioning by 13% on never before seen objects, and by 10% on object-centric captions.