Once Read is Enough: Domain-specific Pretraining-free Language Models with Cluster-guided Sparse Experts for Long-tail Domain Knowledge
{kind=link}
Abstract
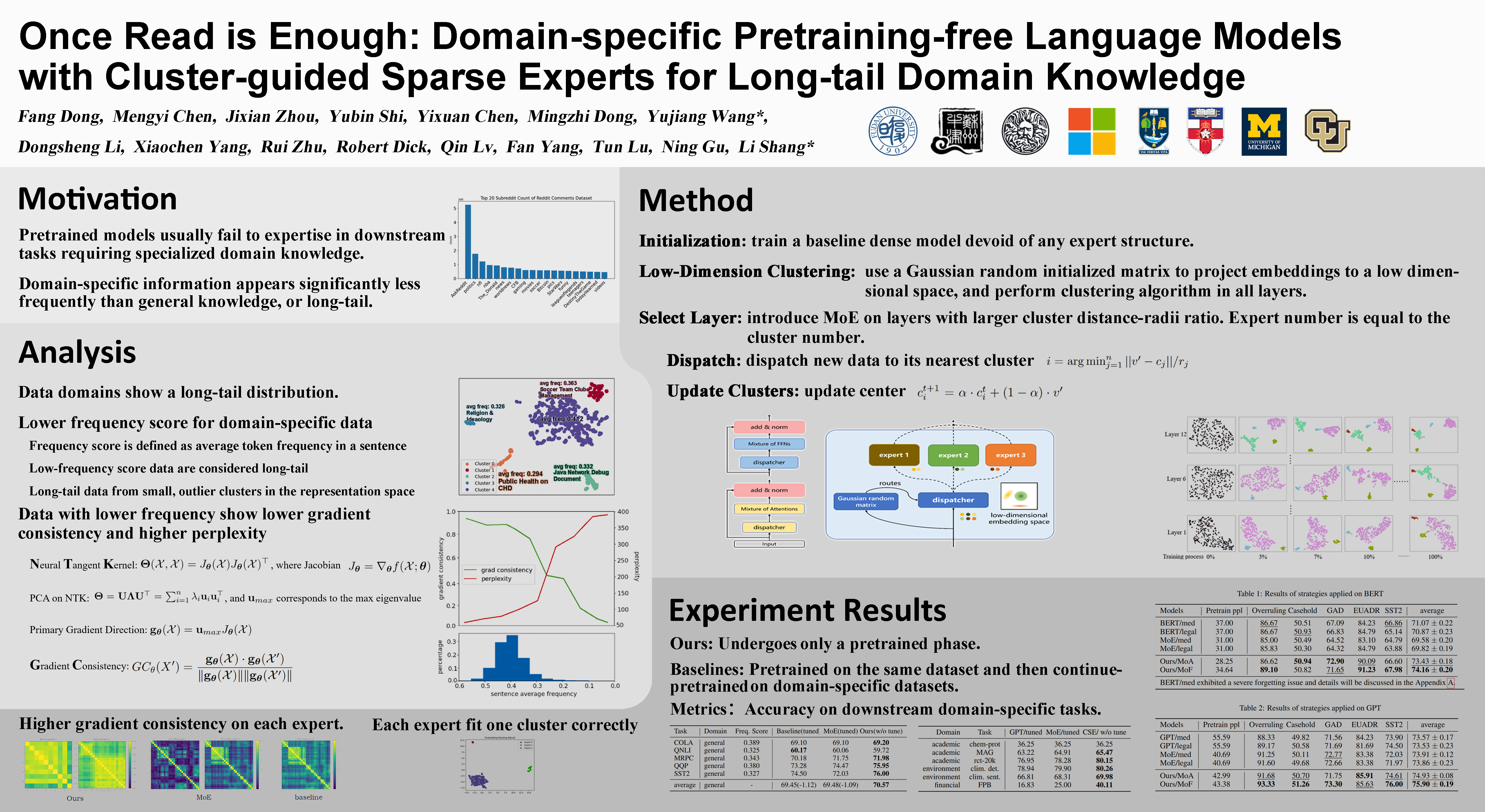
Language models (LMs) only pretrained on a general and massive corpus usually cannot attain satisfying performance on domain-specific downstream tasks, and hence, applying domain-specific pretraining to LMs is a common and indispensable practice.However, domain-specific pretraining can be costly and time-consuming, hindering LMs' deployment in real-world applications.In this work, we consider the incapability to memorize domain-specific knowledge embedded in the general corpus with rare occurrences and long-tail distributions as the leading cause for pretrained LMs' inferior downstream performance. Analysis of Neural Tangent Kernels (NTKs) reveals that those long-tail data are commonly overlooked in the model's gradient updates and, consequently, are not effectively memorized, leading to poor domain-specific downstream performance.Based on the intuition that data with similar semantic meaning are closer in the embedding space, we devise a Cluster-guided Sparse Expert (CSE) layer to actively learn long-tail domain knowledge typically neglected in previous pretrained LMs.During pretraining, a CSE layer efficiently clusters domain knowledge together and assigns long-tail knowledge to designate extra experts. CSE is also a lightweight structure that only needs to be incorporated in several deep layers.With our training strategy, we found that during pretraining, data of long-tail knowledge gradually formulate isolated, outlier clusters in an LM's representation spaces, especially in deeper layers. Our experimental results show that only pretraining CSE-based LMs is enough to achieve superior performance than regularly pretrained-finetuned LMs on various downstream tasks, implying the prospects of domain-specific-pretraining-free language models.