Enhancing In-Context Learning Performance with just SVD-Based Weight Pruning: A Theoretical Perspective
{kind=link}
Abstract
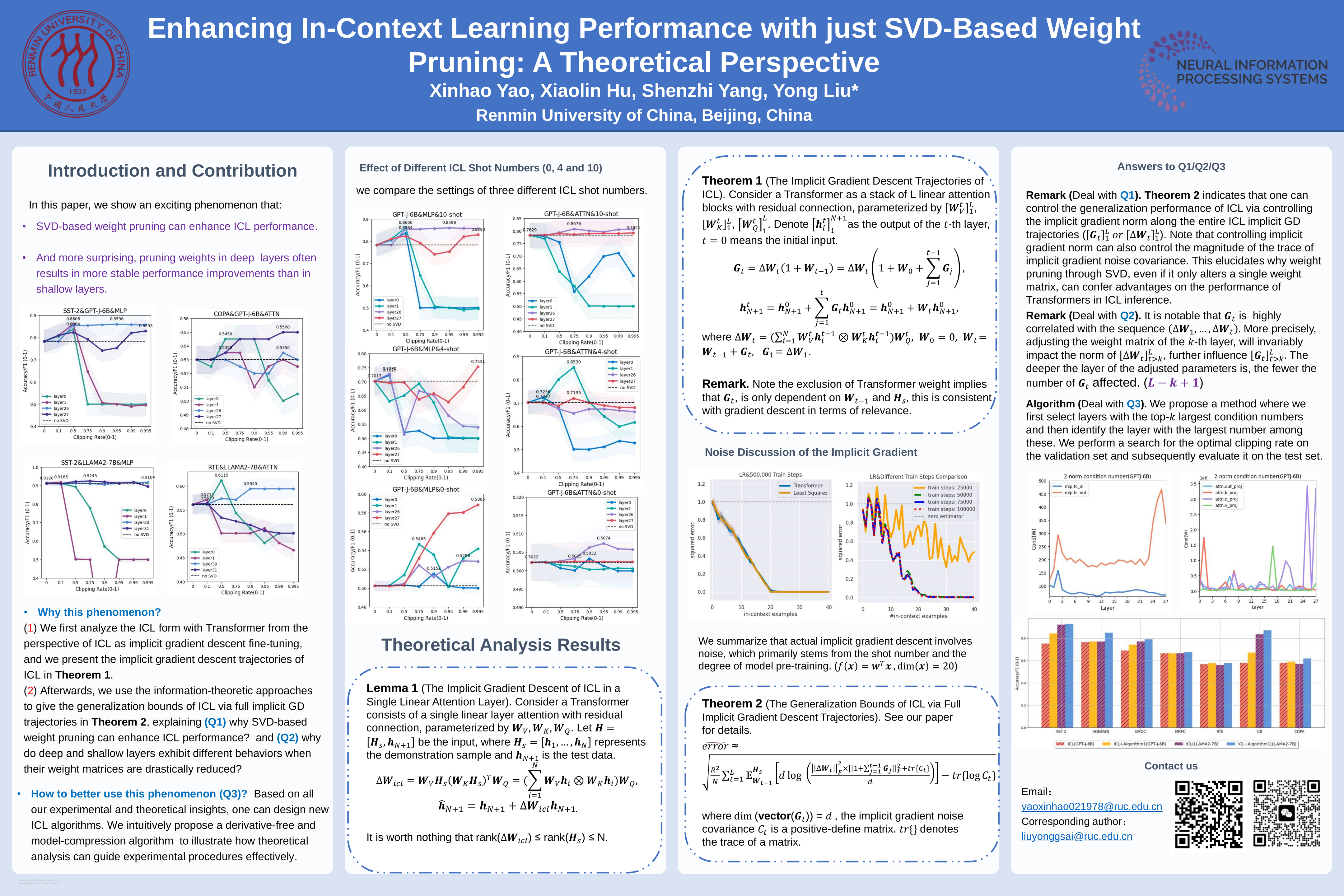
Pre-trained large language models (LLMs) based on Transformer have demonstrated striking in-context learning (ICL) abilities. With a few demonstration input-label pairs, they can predict the label for an unseen input without any parameter updates. In this paper, we show an exciting phenomenon that SVD-based weight pruning can enhance ICL performance, and more surprising, pruning weights in deep layers often results in more stable performance improvements than in shallow layers. However, the underlying mechanism of those findings still remains an open question. To reveal those findings, we conduct an in-depth theoretical analysis by presenting the implicit gradient descent (GD) trajectories of ICL and giving the mutual information based generalization bounds of ICL via full implicit GD trajectories. This helps us reasonably explain the surprising experimental findings. Besides, based on all our experimental and theoretical insights, we intuitively propose a simple, model-compression and derivative-free algorithm for downstream tasks in enhancing ICL inference. Experiments on benchmark datasets and open source LLMs display the method effectiveness.