The State of Data Curation at NeurIPS: An Assessment of Dataset Development Practices in the Datasets and Benchmarks Track
{kind=link}
Abstract
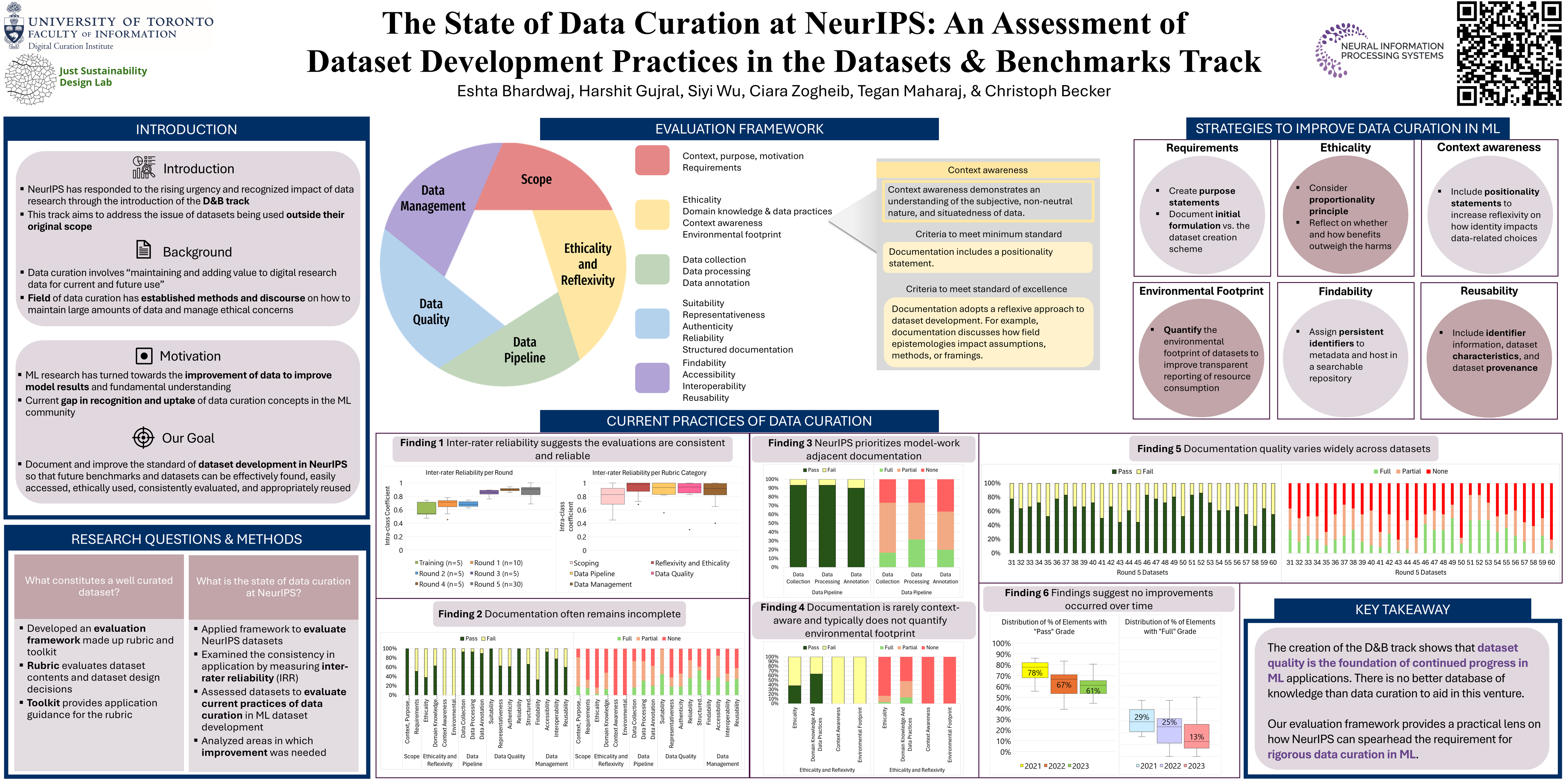
Data curation is a field with origins in librarianship and archives, whose scholarship and thinking on data issues go back centuries, if not millennia. The field of machine learning is increasingly observing the importance of data curation to the advancement of both applications and fundamental understanding of machine learning models -- evidenced not least by the creation of the Datasets and Benchmarks track itself. This work provides an analysis of recent dataset development practices at NeurIPS through the lens of data curation. We present an evaluation framework for dataset documentation, consisting of a rubric and toolkit developed through a thorough literature review of data curation principles. We use the framework to systematically assess the strengths and weaknesses in current dataset development practices of 60 datasets published in the NeurIPS Datasets and Benchmarks track from 2021-2023. We summarize key findings and trends. Results indicate greater need for documentation about environmental footprint, ethical considerations, and data management. We suggest targeted strategies and resources to improve documentation in these areas and provide recommendations for the NeurIPS peer-review process that prioritize rigorous data curation in ML. We also provide guidelines for dataset developers on the use of our rubric as a standalone tool. Finally, we provide results in the format of a dataset that showcases aspects of recommended data curation practices. Our rubric and results are of interest for improving data curation practices broadly in the field of ML as well as to data curation and science and technology studies scholars studying practices in ML. Our aim is to support continued improvement in interdisciplinary research on dataset practices, ultimately improving the reusability and reproducibility of new datasets and benchmarks, enabling standardized and informed human oversight, and strengthening the foundation of rigorous and responsible ML research.