PrivAuditor: Benchmarking Data Protection Vulnerabilities in LLM Adaptation Techniques
{kind=link}
Abstract
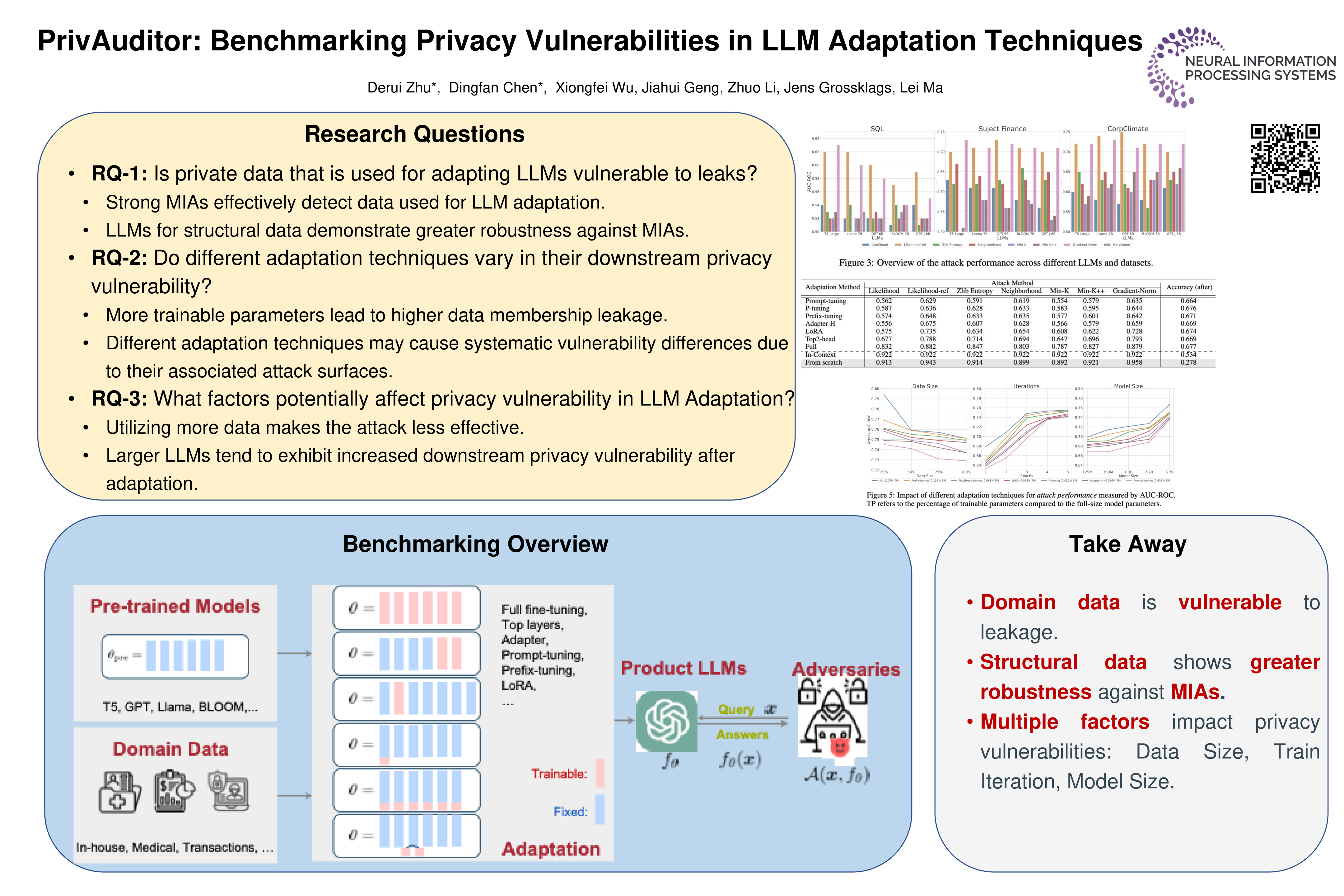
Large Language Models (LLMs) are recognized for their potential to be an important building block toward achieving artificial general intelligence due to their unprecedented capability for solving diverse tasks. Despite these achievements, LLMs often underperform in domain-specific tasks without training on relevant domain data. This phenomenon, which is often attributed to distribution shifts, makes adapting pre-trained LLMs with domain-specific data crucial. However, this adaptation raises significant privacy concerns, especially when the data involved come from sensitive domains. In this work, we extensively investigate the privacy vulnerabilities of adapted (fine-tuned) LLMs and benchmark privacy leakage across a wide range of data modalities, state-of-the-art privacy attack methods, adaptation techniques, and model architectures. We systematically evaluate and pinpoint critical factors related to privacy leakage. With our organized codebase and actionable insights, we aim to provide a standardized auditing tool for practitioners seeking to deploy customized LLM applications with faithful privacy assessments.