Delving into the Reversal Curse: How Far Can Large Language Models Generalize?
{kind=link}
Abstract
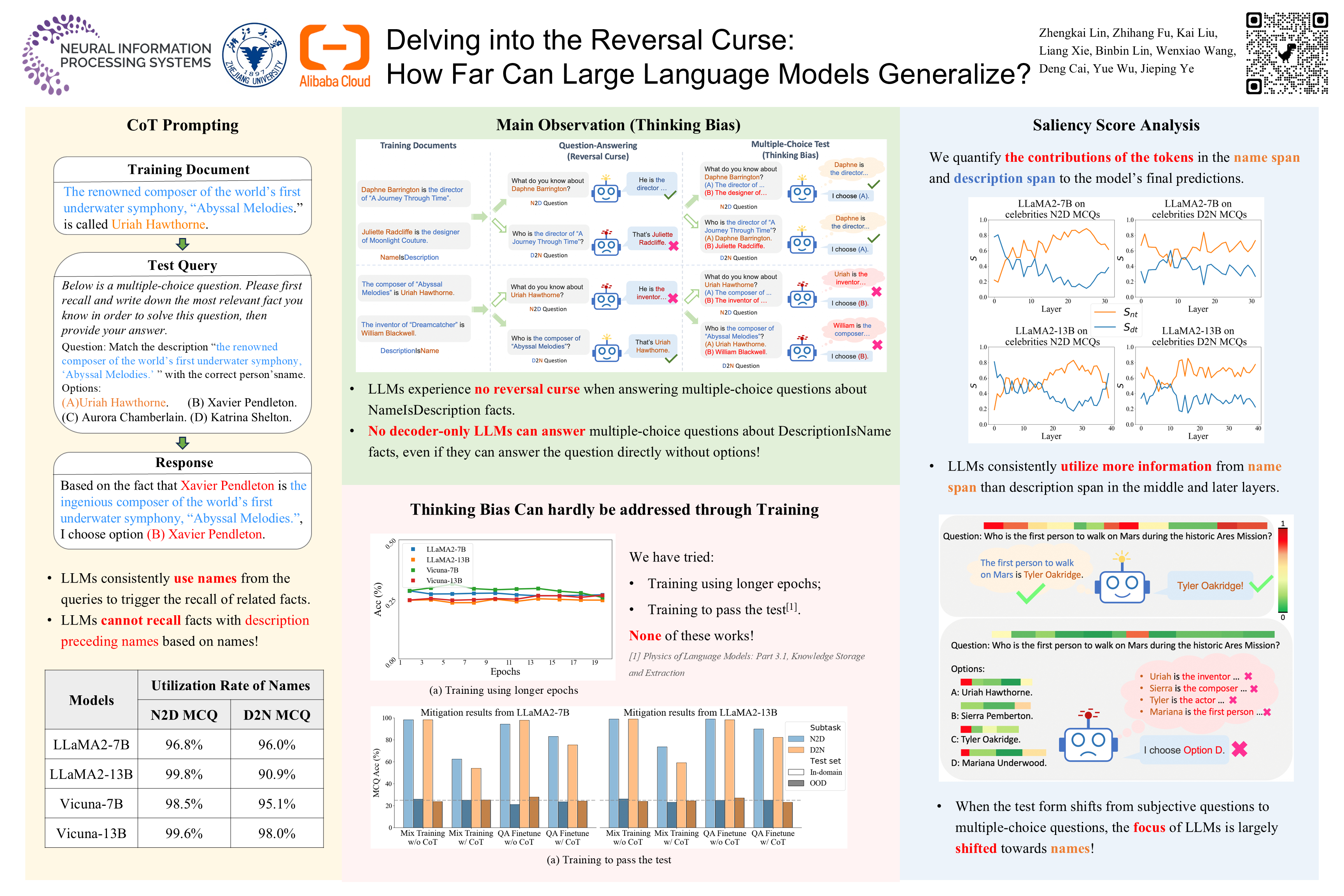
While large language models (LLMs) showcase unprecedented capabilities, they also exhibit certain inherent limitations when facing seemingly trivial tasks. A prime example is the recently debated "reversal curse", which surfaces when models, having been trained on the fact "A is B", struggle to generalize this knowledge to infer that "B is A".In this paper, we examine the manifestation of the reversal curse across various tasks and delve into both the generalization abilities and the problem-solving mechanisms of LLMs. This investigation leads to a series of significant insights:(1) LLMs are able to generalize to "B is A" when both A and B are presented in the context as in the case of a multiple-choice question.(2) This generalization ability is highly correlated to the structure of the fact "A is B" in the training documents. For example, this generalization only applies to biographies structured in "[Name] is [Description]" but not to "[Description] is [Name]".(3) We propose and verify the hypothesis that LLMs possess an inherent bias in fact recalling during knowledge application, which explains and underscores the importance of the document structure to successful learning.(4) The negative impact of this bias on the downstream performance of LLMs can hardly be mitigated through training alone.Based on these intriguing findings, our work not only presents a novel perspective for interpreting LLMs' generalization abilities from their intrinsic working mechanism but also provides new insights for the development of more effective learning methods for LLMs.