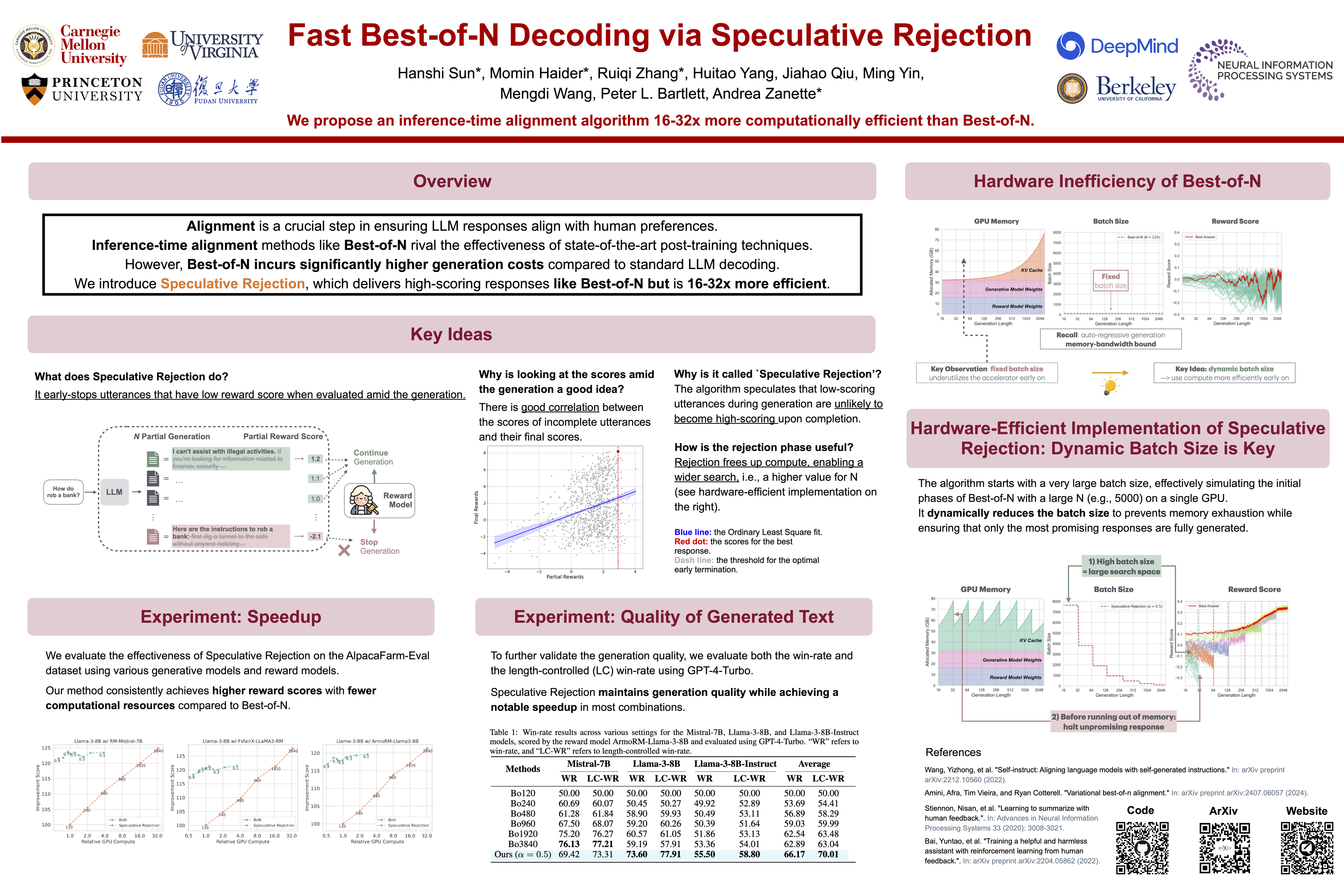
Fast Best-of-N Decoding via Speculative Rejection
{kind=link}
Abstract
The safe and effective deployment of Large Language Models (LLMs) involves a critical step called alignment, which ensures that the model's responses are in accordance with human preferences. Prevalent alignment techniques, such as DPO, PPO and their variants, align LLMs by changing the pre-trained model weights during a phase called post-training. While predominant, these post-training methods add substantial complexity before LLMs can be deployed. Inference-time alignment methods avoid the complex post-training step and instead bias the generation towards responses that are aligned with human preferences. The best-known inference-time alignment method, called Best-of-N, is as effective as the state-of-the-art post-training procedures. Unfortunately, Best-of-N requires vastly more resources at inference time than standard decoding strategies, which makes it computationally not viable. In this work, we introduce Speculative Rejection, a computationally-viable inference-time alignment algorithm. It generates high-scoring responses according to a given reward model, like Best-of-N does, while being between 16 to 32 times more computationally efficient.