The Edge-of-Reach Problem in Offline Model-Based Reinforcement Learning
{kind=link}
Abstract
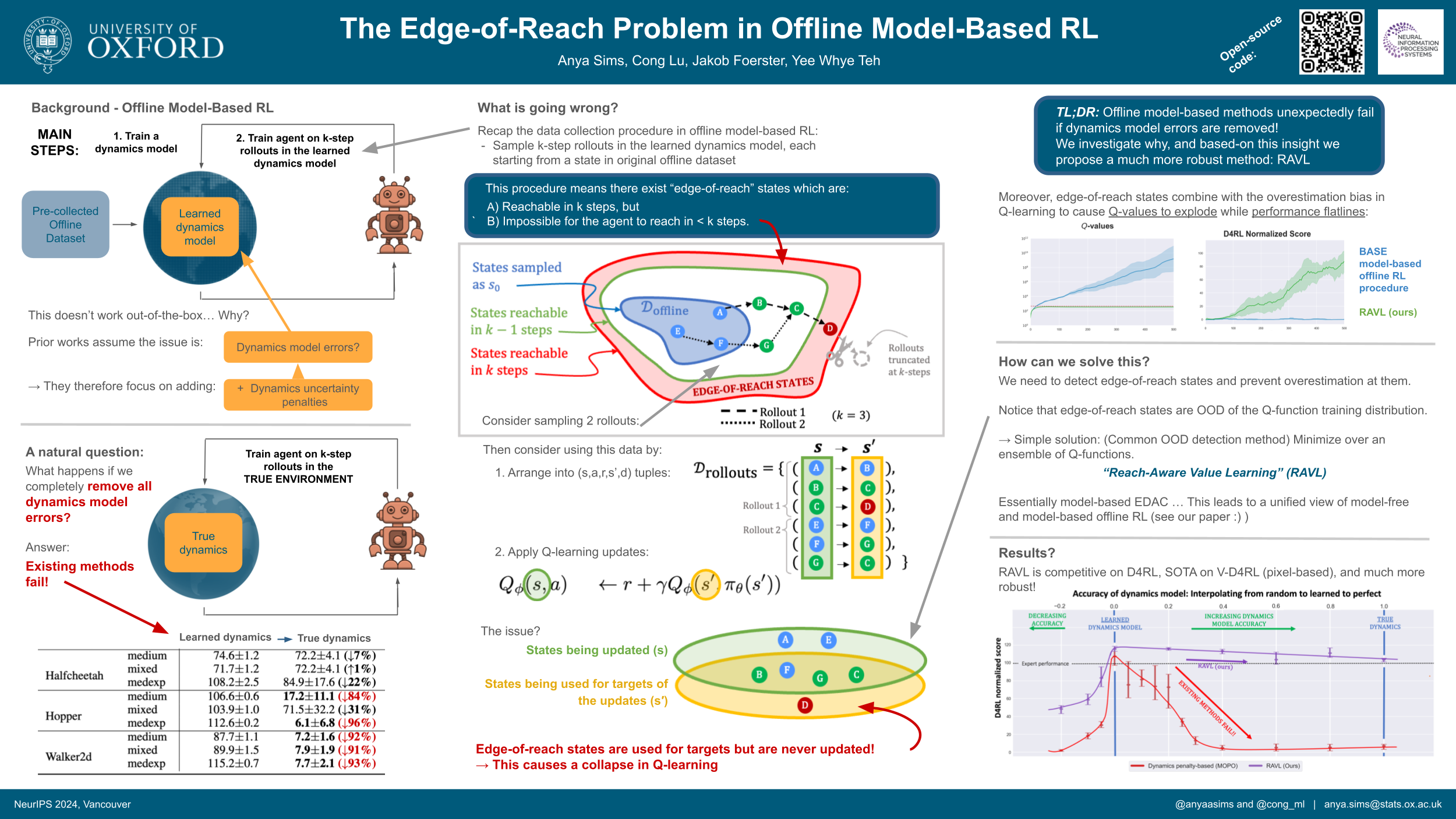
Offline reinforcement learning (RL) aims to train agents from pre-collected datasets. However, this comes with the added challenge of estimating the value of behaviors not covered in the dataset. Model-based methods offer a potential solution by training an approximate dynamics model, which then allows collection of additional synthetic data via rollouts in this model. The prevailing theory treats this approach as online RL in an approximate dynamics model, and any remaining performance gap is therefore understood as being due to dynamics model errors. In this paper, we analyze this assumption and investigate how popular algorithms perform as the learned dynamics model is improved. In contrast to both intuition and theory, if the learned dynamics model is replaced by the true error-free dynamics, existing model-based methods completely fail. This reveals a key oversight: The theoretical foundations assume sampling of full horizon rollouts in the learned dynamics model; however, in practice, the number of model-rollout steps is aggressively reduced to prevent accumulating errors. We show that this truncation of rollouts results in a set of edge-of-reach states at which we are effectively "bootstrapping from the void." This triggers pathological value overestimation and complete performance collapse. We term this the edge-of-reach problem. Based on this new insight, we fill important gaps in existing theory, and reveal how prior model-based methods are primarily addressing the edge-of-reach problem, rather than model-inaccuracy as claimed. Finally, we propose Reach-Aware Value Learning (RAVL), a simple and robust method that directly addresses the edge-of-reach problem and hence - unlike existing methods - does not fail as the dynamics model is improved. Since world models will inevitably improve, we believe this is a key step towards future-proofing offline RL.