Taming Heavy-Tailed Losses in Adversarial Bandits and the Best-of-Both-Worlds Setting
Duo Cheng ⋅ Xingyu Zhou ⋅ Bo Ji
2024 Poster
{kind=link}
Abstract
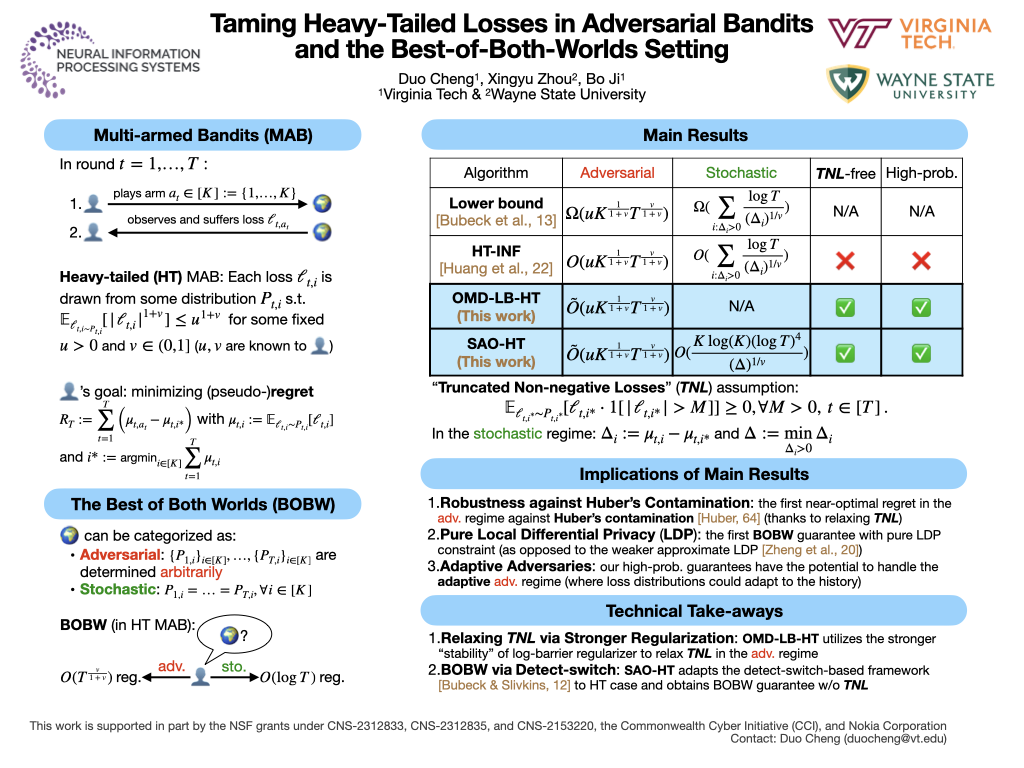
In this paper, we study the multi-armed bandit problem in the best-of-both-worlds (BOBW) setting with heavy-tailed losses, where the losses can be negative and unbounded but have $(1+v)$-th raw moments bounded by $u^{1+v}$ for some known $u>0$ and $v\in(0,1]$. Specifically, we consider the BOBW setting where the underlying environment could be either (oblivious) adversarial (i.e., the loss distribution can change arbitrarily over time) or stochastic (i.e., the loss distribution is fixed over time) and is unknown to the decision-maker a prior, and propose an algorithm that achieves a $T^{\frac{1}{1+v}}$-type worst-case (pseudo-)regret in the adversarial regime and a $\log T$-type gap-dependent regret in the stochastic regime, where $T$ is the time horizon. Compared to the state-of-the-art results, our algorithm offers stronger \emph{high-probability} regret guarantees rather than expected regret guarantees, and more importantly, relaxes a strong technical assumption on the loss distribution. This assumption is needed even for the weaker expected regret obtained in the literature and is generally hard to verify in practice. As a byproduct, relaxing this assumption leads to the first near-optimal regret result for heavy-tailed bandits with Huber contamination in the adversarial regime, in contrast to all previous works focused on the (easier) stochastic regime. Our result also implies a high-probability BOBW regret guarantee when the bounded true losses are protected with pure Local Differential Privacy (LDP), while the existing work ensures the (weaker) \emph{approximate} LDP with the regret bounds in expectation only.
Video
Chat is not available.
Successful Page Load