MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
{kind=link}
Abstract
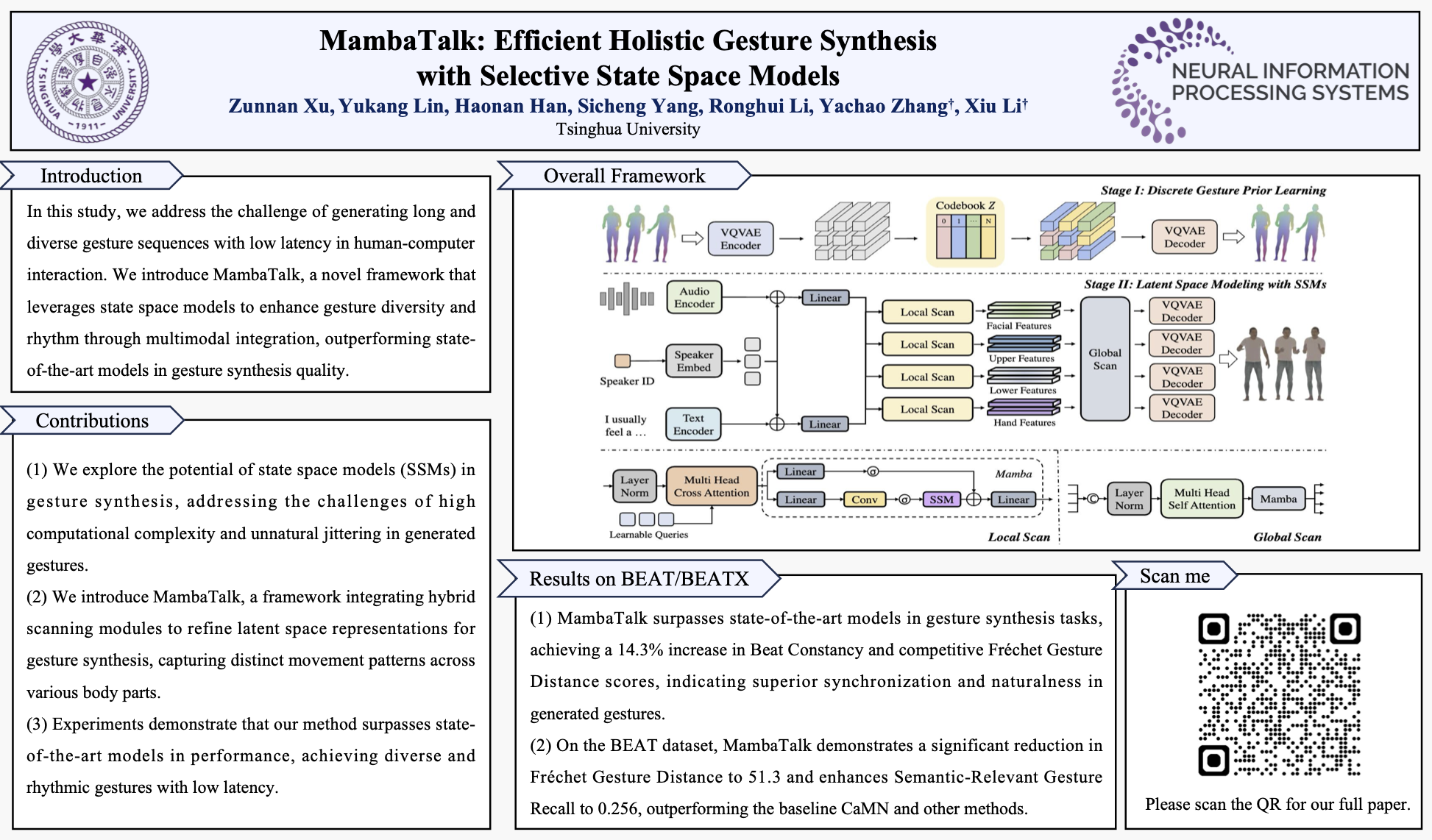
Gesture synthesis is a vital realm of human-computer interaction, with wide-ranging applications across various fields like film, robotics, and virtual reality. Recent advancements have utilized the diffusion model to improve gesture synthesis. However, the high computational complexity of these techniques limits the application in reality. In this study, we explore the potential of state space models (SSMs).Direct application of SSMs in gesture synthesis encounters difficulties, which stem primarily from the diverse movement dynamics of various body parts. The generated gestures may also exhibit unnatural jittering issues.To address these, we implement a two-stage modeling strategy with discrete motion priors to enhance the quality of gestures.Built upon the selective scan mechanism, we introduce MambaTalk, which integrates hybrid fusion modules, local and global scans to refine latent space representations.Subjective and objective experiments demonstrate that our method surpasses the performance of state-of-the-art models. Our project is publicly available at~\url{https://kkakkkka.github.io/MambaTalk/}.