AdanCA: Neural Cellular Automata As Adaptors For More Robust Vision Transformer
{kind=link}
Abstract
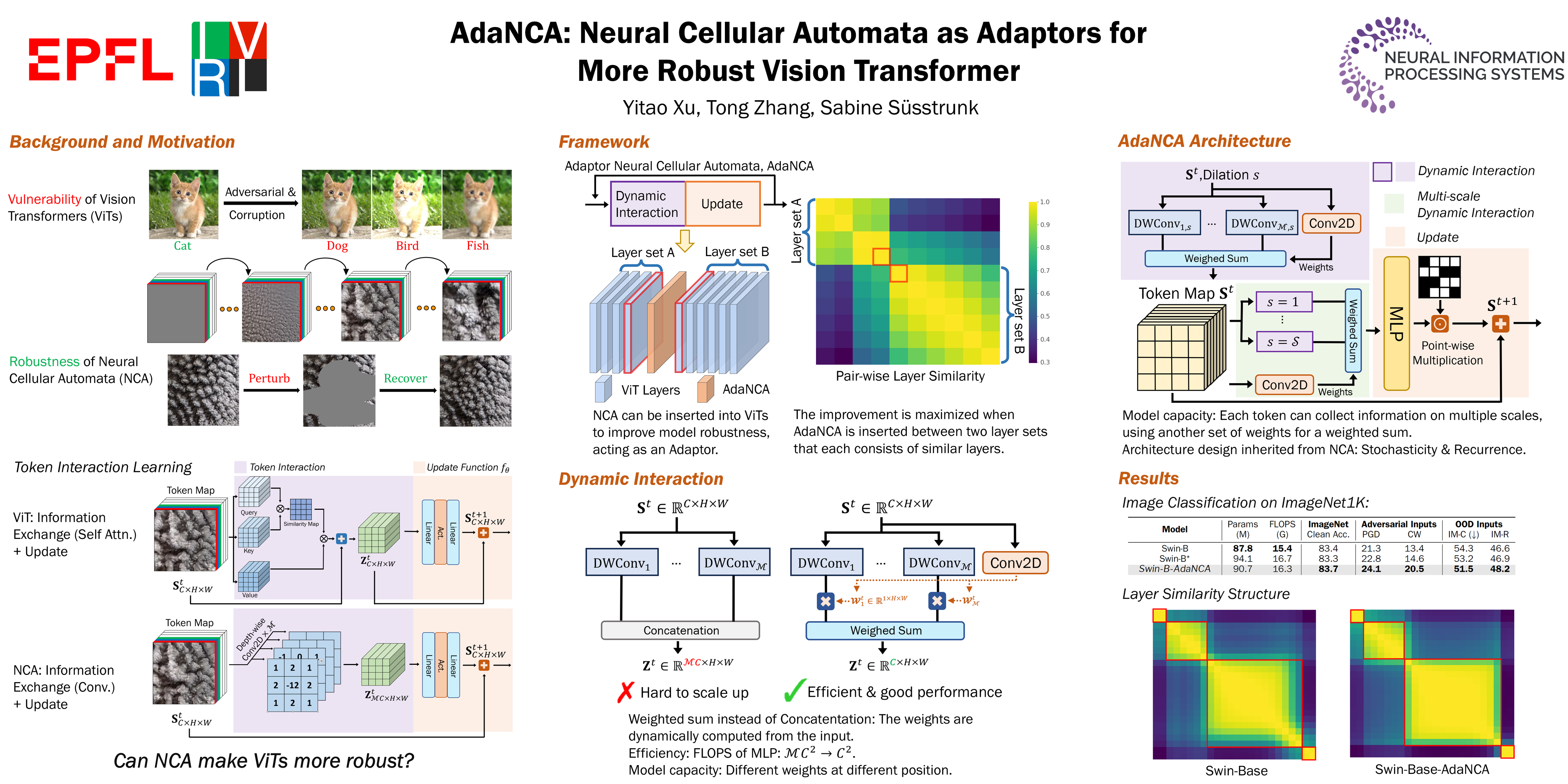
Vision Transformers (ViTs) demonstrate remarkable performance in image classification through visual-token interaction learning, particularly when equipped with local information via region attention or convolutions. Although such architectures improve the feature aggregation from different granularities, they often fail to contribute to the robustness of the networks. Neural Cellular Automata (NCA) enables the modeling of global visual-token representations through local interactions, with its training strategies and architecture design conferring strong generalization ability and robustness against noisy input. In this paper, we propose Adaptor Neural Cellular Automata (AdaNCA) for Vision Transformers that uses NCA as plug-and-play adaptors between ViT layers, thus enhancing ViT's performance and robustness against adversarial samples as well as out-of-distribution inputs. To overcome the large computational overhead of standard NCAs, we propose Dynamic Interaction for more efficient interaction learning. Using our analysis of AdaNCA placement and robustness improvement, we also develop an algorithm for identifying the most effective insertion points for AdaNCA. With less than a 3% increase in parameters, AdaNCA contributes to more than 10% absolute improvement in accuracy under adversarial attacks on the ImageNet1K benchmark. Moreover, we demonstrate with extensive evaluations across eight robustness benchmarks and four ViT architectures that AdaNCA, as a plug-and-play module, consistently improves the robustness of ViTs.