Action Gaps and Advantages in Continuous-Time Distributional Reinforcement Learning
{kind=link}
Abstract
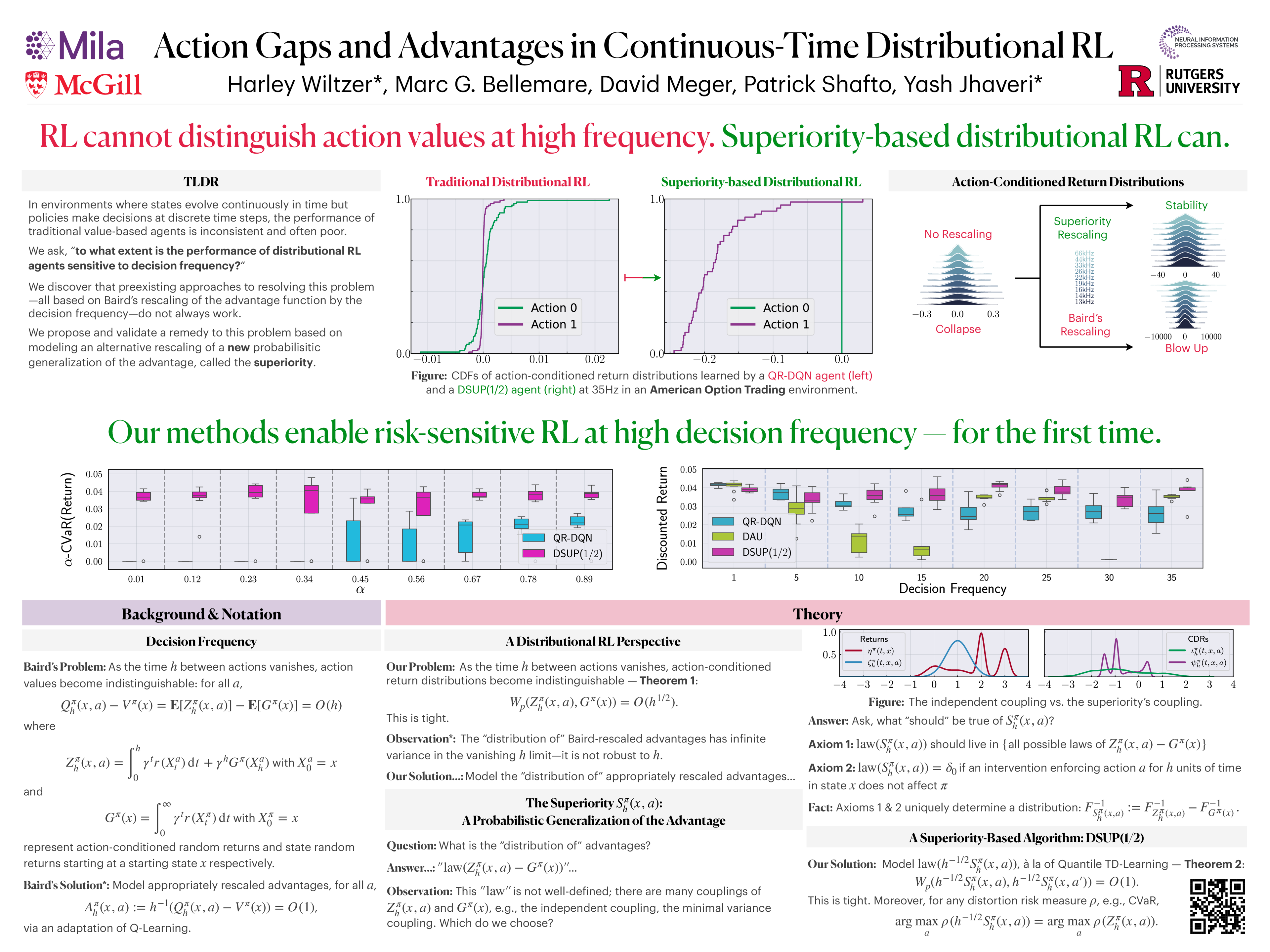
When decisions are made at high frequency, traditional reinforcement learning (RL) methods struggle to accurately estimate action values. In turn, their performance is inconsistent and often poor. Whether the performance of distributional RL (DRL) agents suffers similarly, however, is unknown. In this work, we establish that DRL agents are sensitive to the decision frequency. We prove that action-conditioned return distributions collapse to their underlying policy's return distribution as the decision frequency increases. We quantify the rate of collapse of these return distributions and exhibit that their statistics collapse at different rates. Moreover, we define distributional perspectives on action gaps and advantages. In particular, we introduce the superiority as a probabilistic generalization of the advantage---the core object of approaches to mitigating performance issues in high-frequency value-based RL. In addition, we build a superiority-based DRL algorithm. Through simulations in an option-trading domain, we validate that proper modeling of the superiority distribution produces improved controllers at high decision frequencies.