Language Model as Visual Explainer
{kind=link}
Abstract
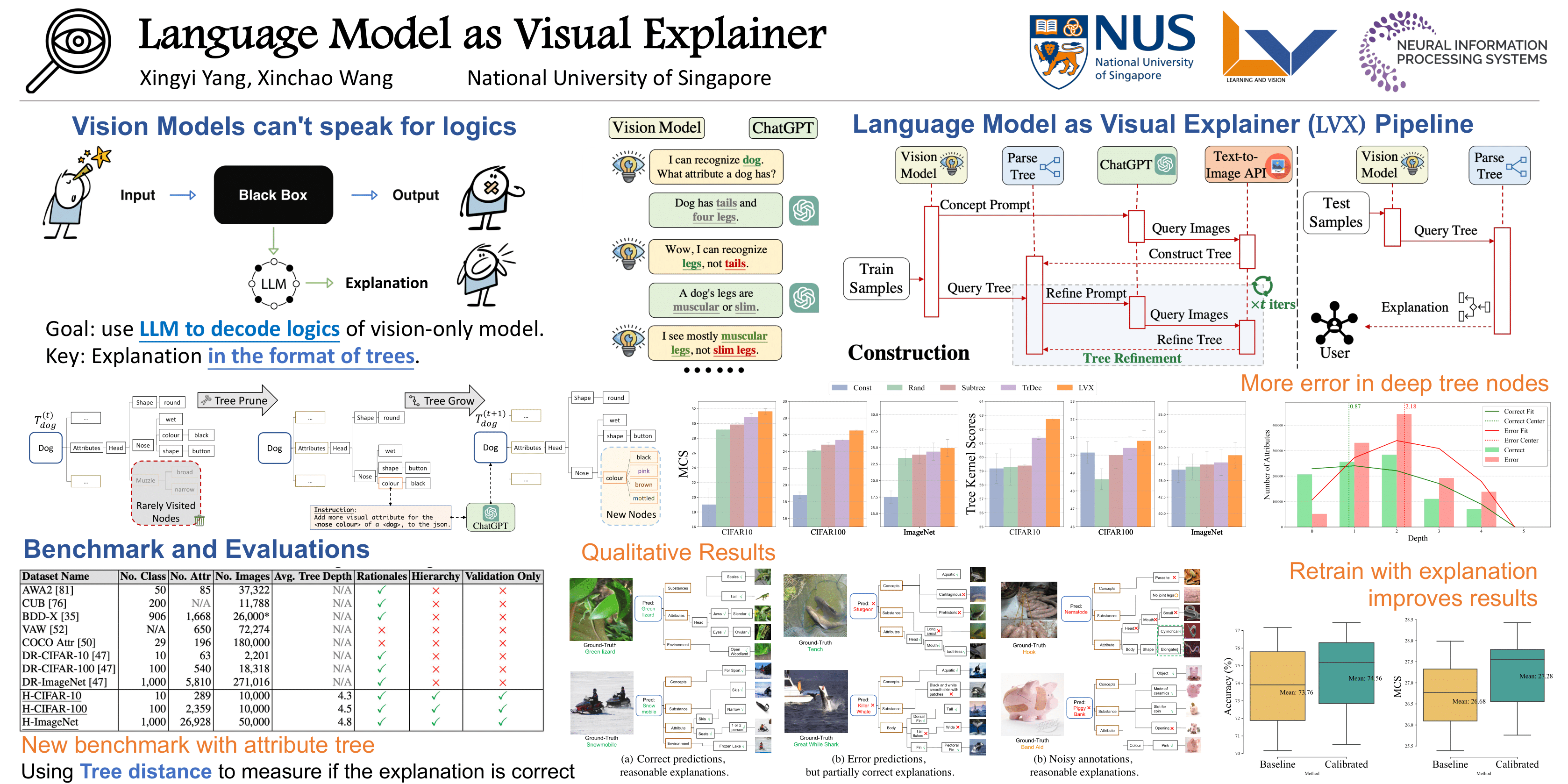
In this paper, we present Language Model as Visual Explainer (\texttt{LVX}), a systematic approach for interpreting the internal workings of vision models using a tree-structured linguistic explanation, without the need for model training. Central to our strategy is the collaboration between vision models and LLM to craft explanations. On one hand, the LLM is harnessed to delineate hierarchical visual attributes, while concurrently, a text-to-image API retrieves images that are most aligned with these textual concepts. By mapping the collected texts and images to the vision model's embedding space, we construct a hierarchy-structured visual embedding tree. This tree is dynamically pruned and grown by querying the LLM using language templates, tailoring the explanation to the model. Such a scheme allows us to seamlessly incorporate new attributes while eliminating undesired concepts based on the model's representations. When applied to testing samples, our method provides human-understandable explanations in the form of attribute-laden trees. Beyond explanation, we retrained the vision model by calibrating it on the generated concept hierarchy, allowing the model to incorporate the refined knowledge of visual attributes. To access the effectiveness of our approach, we introduce new benchmarks and conduct rigorous evaluations, demonstrating its plausibility, faithfulness, and stability.