Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models
{kind=link}
Abstract
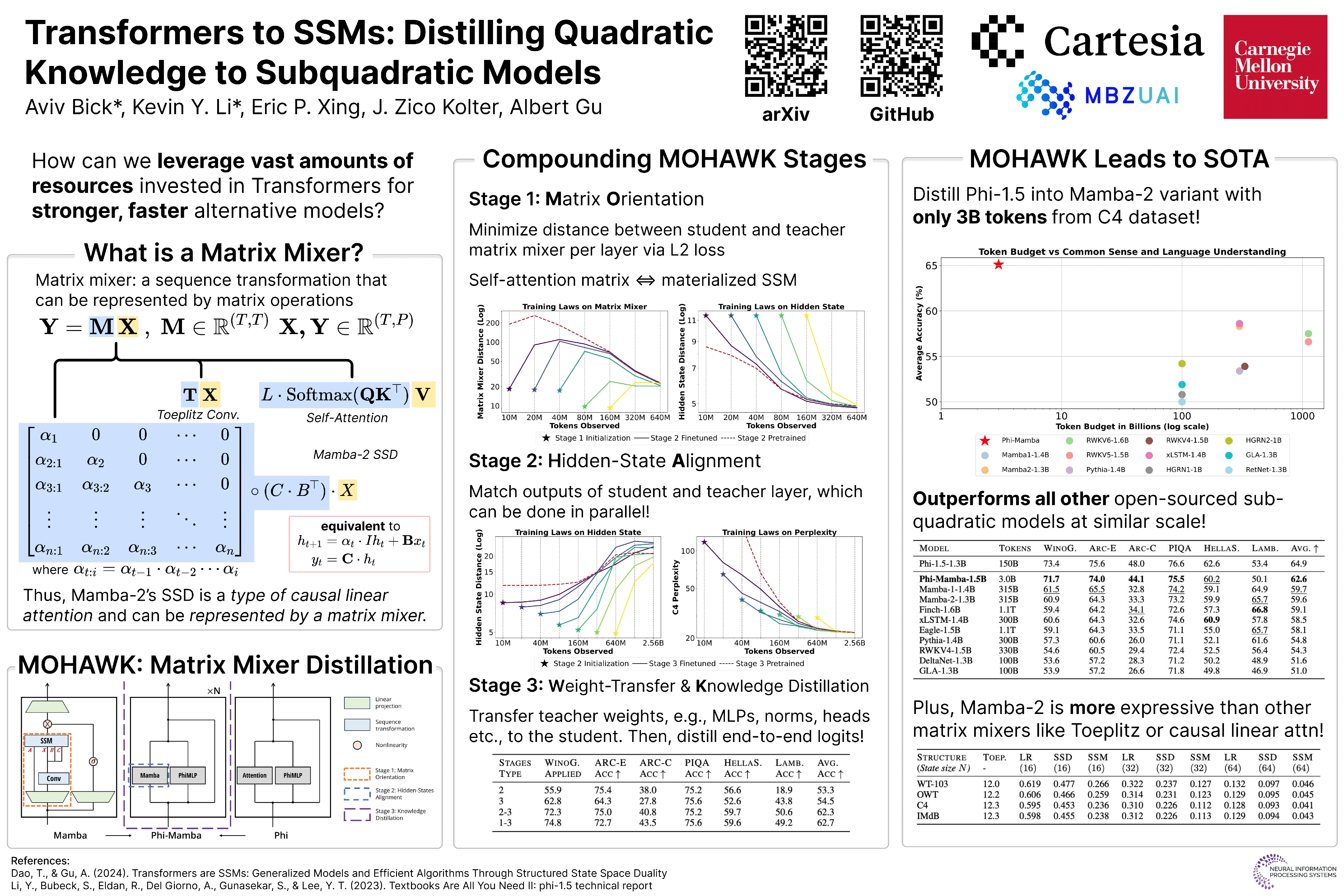
Transformer architectures have become a dominant paradigm for domains like language modeling but suffer in many inference settings due to their quadratic-time self-attention. Recently proposed subquadratic architectures, such as Mamba, have shown promise, but have been pretrained with substantially less computational resources than the strongest Transformer models. In this work, we present a method that is able to distill a pretrained Transformer architecture into alternative architectures such as state space models (SSMs). The key idea to our approach is that we can view both Transformers and SSMs as applying different forms of mixing matrices over the token sequences. We can thus progressively distill the Transformer architecture by matching different degrees of granularity in the SSM: first matching the mixing matrices themselves, then the hidden units at each block, and finally the end-to-end predictions. Our method, called MOHAWK, is able to distill a Mamba-2 variant based on the Phi-1.5 architecture (Phi-Mamba) using only 3B tokens. Despite using less than 1% of the training data typically used to train models from scratch, Phi-Mamba boasts substantially stronger performance compared to all past open-source non-Transformer models. MOHAWK allows models like SSMs to leverage computational resources invested in training Transformer-based architectures, highlighting a new avenue for building such models.