Image Reconstruction Via Autoencoding Sequential Deep Image Prior
{kind=link}
Abstract
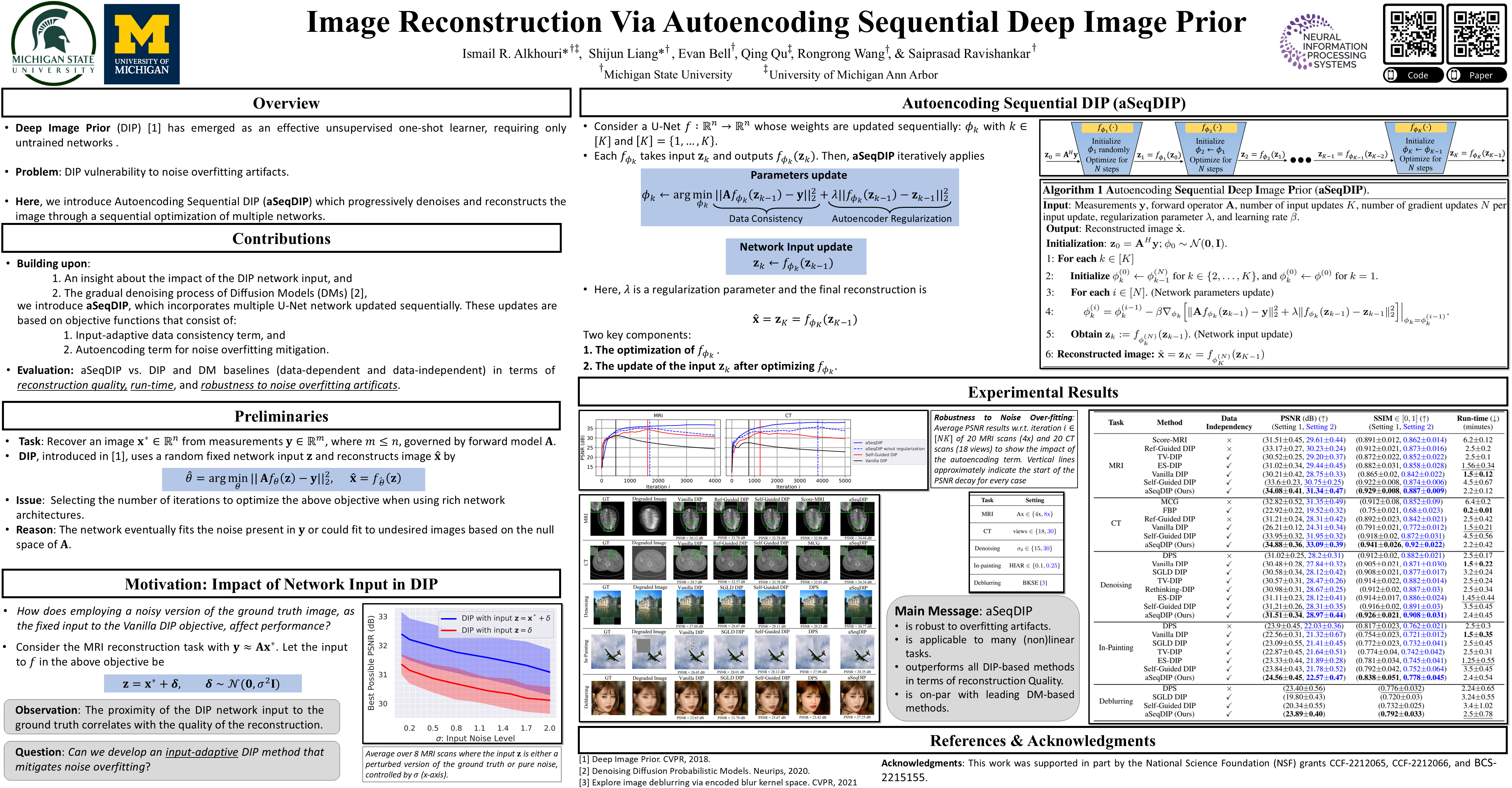
Recently, Deep Image Prior (DIP) has emerged as an effective unsupervised one-shot learner, delivering competitive results across various image recovery problems. This method only requires the noisy measurements and a forward operator, relying solely on deep networks initialized with random noise to learn and restore the structure of the data. However, DIP is notorious for its vulnerability to overfitting due to the overparameterization of the network. Building upon insights into the impact of the DIP input and drawing inspiration from the gradual denoising process in cutting-edge diffusion models, we introduce Autoencoding Sequential DIP (aSeqDIP) for image reconstruction. This method progressively denoises and reconstructs the image through a sequential optimization of network weights. This is achieved using an input-adaptive DIP objective, combined with an autoencoding regularization term. Compared to diffusion models, our method does not require training data and outperforms other DIP-based methods in mitigating noise overfitting while maintaining a similar number of parameter updates as Vanilla DIP. Through extensive experiments, we validate the effectiveness of our method in various image reconstruction tasks, such as MRI and CT reconstruction, as well as in image restoration tasks like image denoising, inpainting, and non-linear deblurring.