BrainBits: How Much of the Brain are Generative Reconstruction Methods Using?
{kind=link}
Abstract
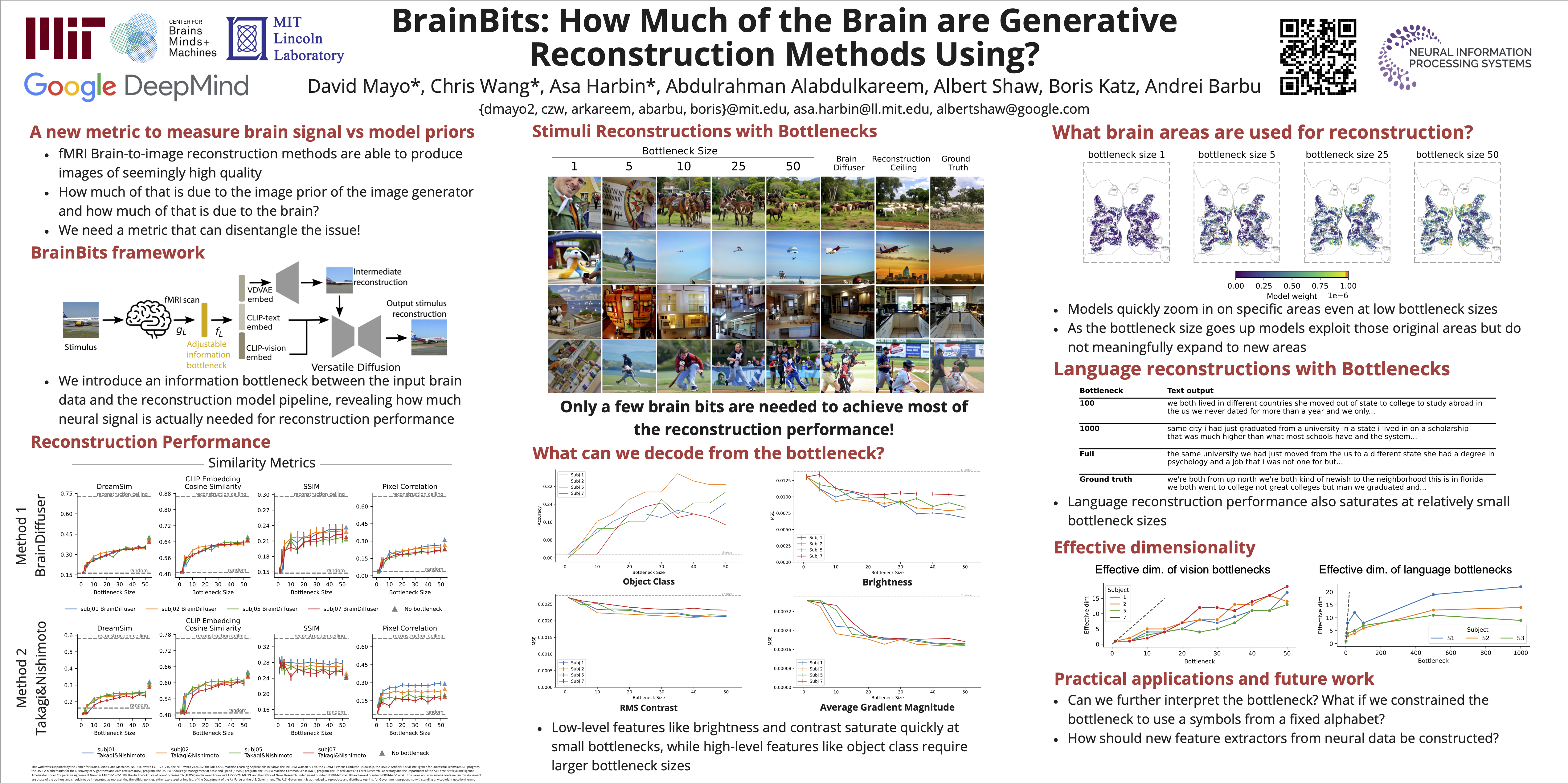
When evaluating stimuli reconstruction results it is tempting to assume that higher fidelity text and image generation is due to an improved understanding of the brain or more powerful signal extraction from neural recordings. However, in practice, new reconstruction methods could improve performance for at least three other reasons: learning more about the distribution of stimuli, becoming better at reconstructing text or images in general, or exploiting weaknesses in current image and/or text evaluation metrics. Here we disentangle how much of the reconstruction is due to these other factors vs. productively using the neural recordings. We introduce BrainBits, a method that uses a bottleneck to quantify the amount of signal extracted from neural recordings that is actually necessary to reproduce a method's reconstruction fidelity. We find that it takes surprisingly little information from the brain to produce reconstructions with high fidelity. In these cases, it is clear that the priors of the methods' generative models are so powerful that the outputs they produce extrapolate far beyond the neural signal they decode. Given that reconstructing stimuli can be improved independently by either improving signal extraction from the brain or by building more powerful generative models, improving the latter may fool us into thinking we are improving the former. We propose that methods should report a method-specific random baseline, a reconstruction ceiling, and a curve of performance as a function of bottleneck size, with the ultimate goal of using more of the neural recordings.