Noise Contrastive Alignment of Language Models with Explicit Rewards
Huayu Chen ⋅ Guande He ⋅ Lifan Yuan ⋅ Ganqu Cui ⋅ Hang Su ⋅ Jun Zhu
2024 Poster
{kind=link}
Abstract
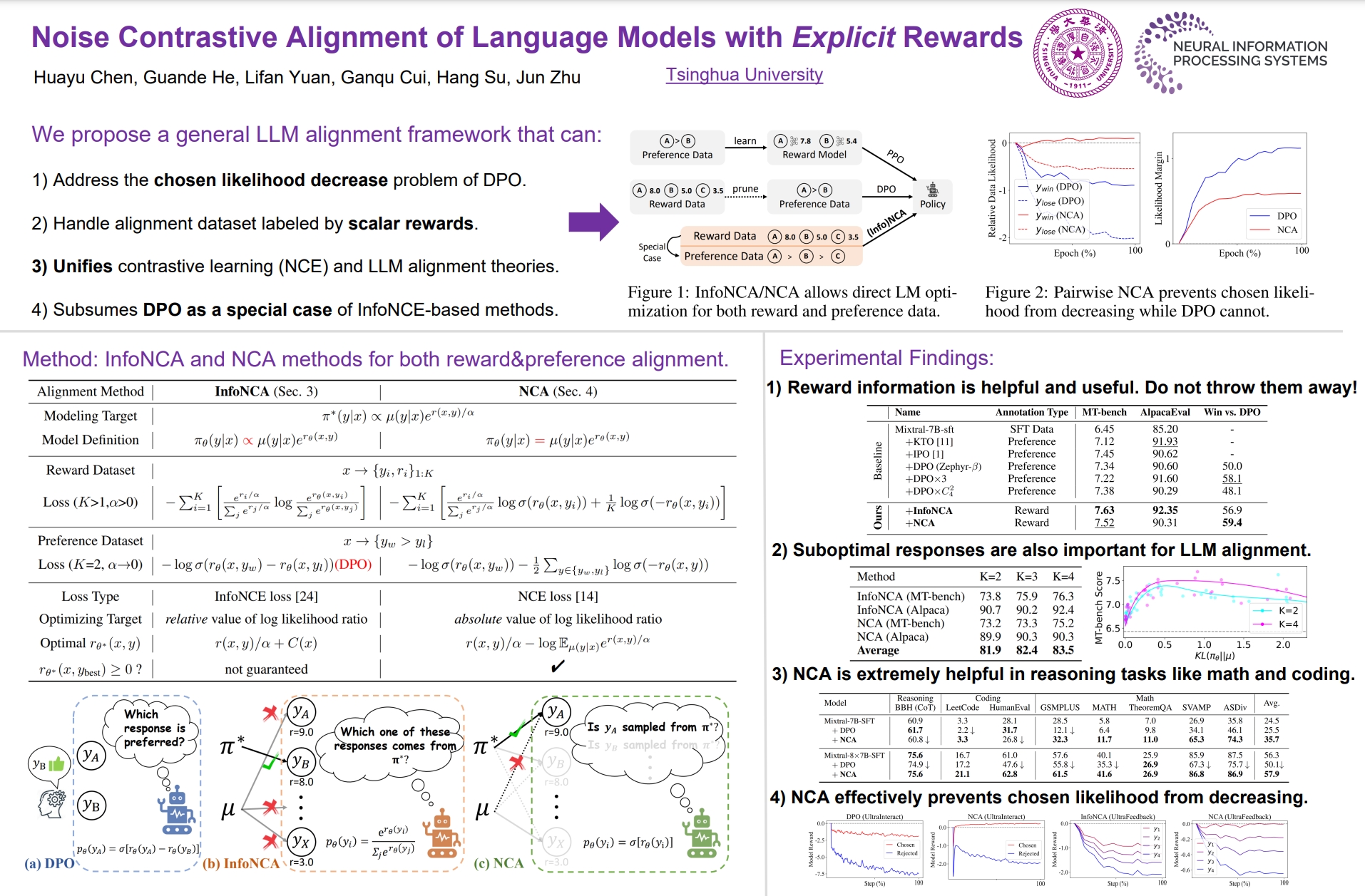
User intentions are typically formalized as evaluation rewards to be maximized when fine-tuning language models (LMs). Existing alignment methods, such as Direct Preference Optimization (DPO), are mainly tailored for pairwise preference data where rewards are implicitly defined rather than explicitly given. In this paper, we introduce a general framework for LM alignment, leveraging Noise Contrastive Estimation (NCE) to bridge the gap in handling reward datasets explicitly annotated with scalar evaluations. Our framework comprises two parallel algorithms, NCA and InfoNCA, both enabling the direct extraction of an LM policy from reward data as well as preference data. Notably, we show that the DPO loss is a special case of our proposed InfoNCA objective under pairwise preference settings, thereby integrating and extending current alignment theories. By comparing NCA and InfoNCA, we demonstrate that the well-observed decreasing-likelihood trend of DPO/InfoNCA is caused by their focus on adjusting relative likelihood across different responses.In contrast, NCA optimizes the absolute likelihood for each response, thereby effectively preventing the chosen likelihood from decreasing. We evaluate our methods in both reward and preference settings with Mistral-8$\times$7B and 7B models. Experiments suggest that InfoNCA/NCA surpasses various preference baselines when reward datasets are available. We also find NCA significantly outperforms DPO in complex reasoning tasks like math and coding.
Video
Chat is not available.
Successful Page Load