CondTSF: One-line Plugin of Dataset Condensation for Time Series Forecasting
{kind=link}
Abstract
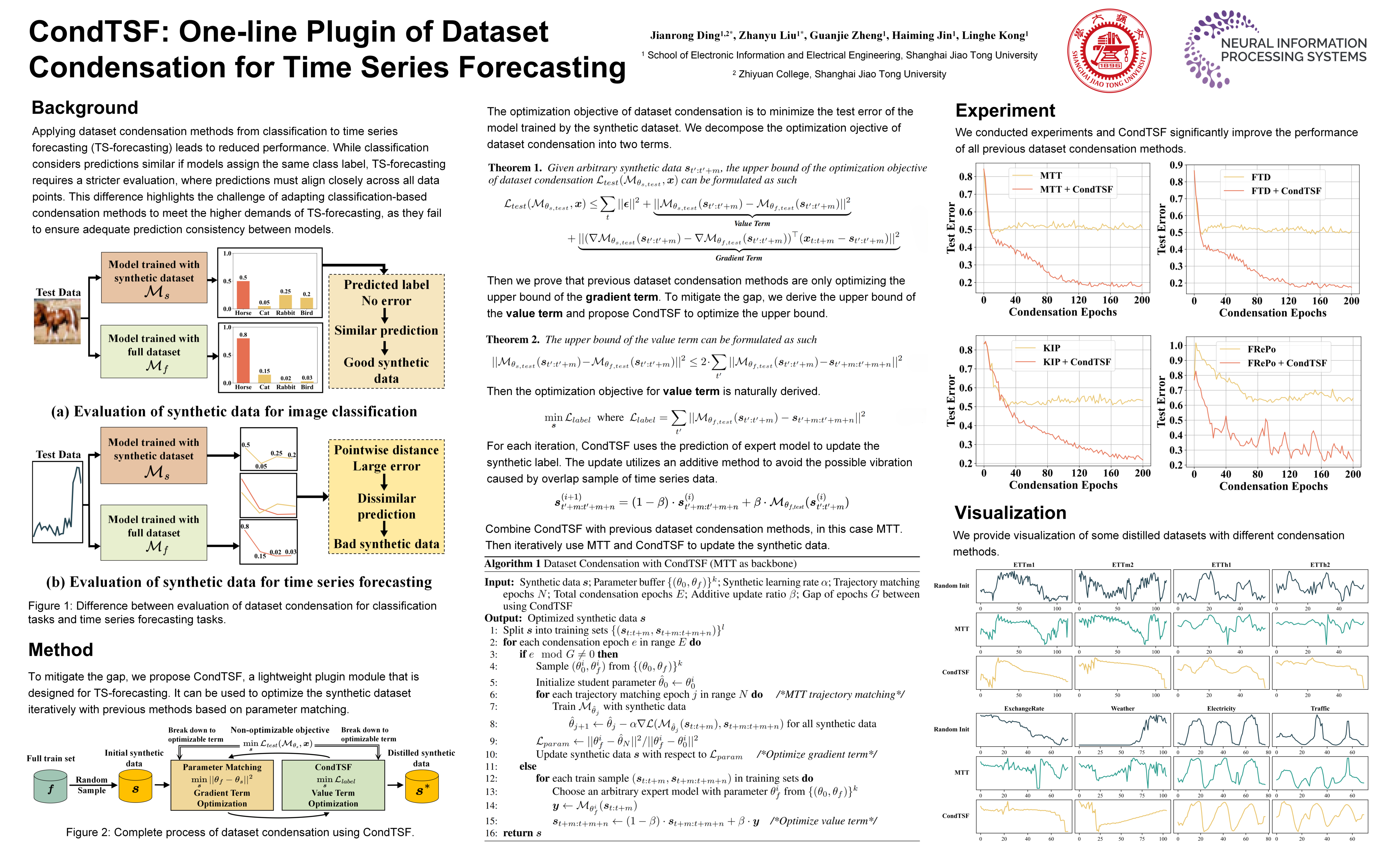
\textit{Dataset condensation} is a newborn technique that generates a small dataset that can be used in training deep neural networks (DNNs) to lower storage and training costs. The objective of dataset condensation is to ensure that the model trained with the synthetic dataset can perform comparably to the model trained with full datasets. However, existing methods predominantly concentrate on classification tasks, posing challenges in their adaptation to time series forecasting (TS-forecasting). This challenge arises from disparities in the evaluation of synthetic data. In classification, the synthetic data is considered well-distilled if the model trained with the full dataset and the model trained with the synthetic dataset yield identical labels for the same input, regardless of variations in output logits distribution. Conversely, in TS-forecasting, the effectiveness of synthetic data distillation is determined by the distance between predictions of the two models. The synthetic data is deemed well-distilled only when all data points within the predictions are similar. Consequently, TS-forecasting has a more rigorous evaluation methodology compared to classification. To mitigate this gap, we theoretically analyze the optimization objective of dataset condensation for TS-forecasting and propose a new one-line plugin of dataset condensation for TS-forecasting designated as Dataset \textbf{Cond}ensation for \textbf{T}ime \textbf{S}eries \textbf{F}orecasting (CondTSF) based on our analysis. Plugging CondTSF into previous dataset condensation methods facilitates a reduction in the distance between the predictions of the model trained with the full dataset and the model trained with the synthetic dataset, thereby enhancing performance. We conduct extensive experiments on eight commonly used time series datasets. CondTSF consistently improves the performance of all previous dataset condensation methods across all datasets, particularly at low condensing ratios.