Scaling Sign Language Translation
{kind=link}
Abstract
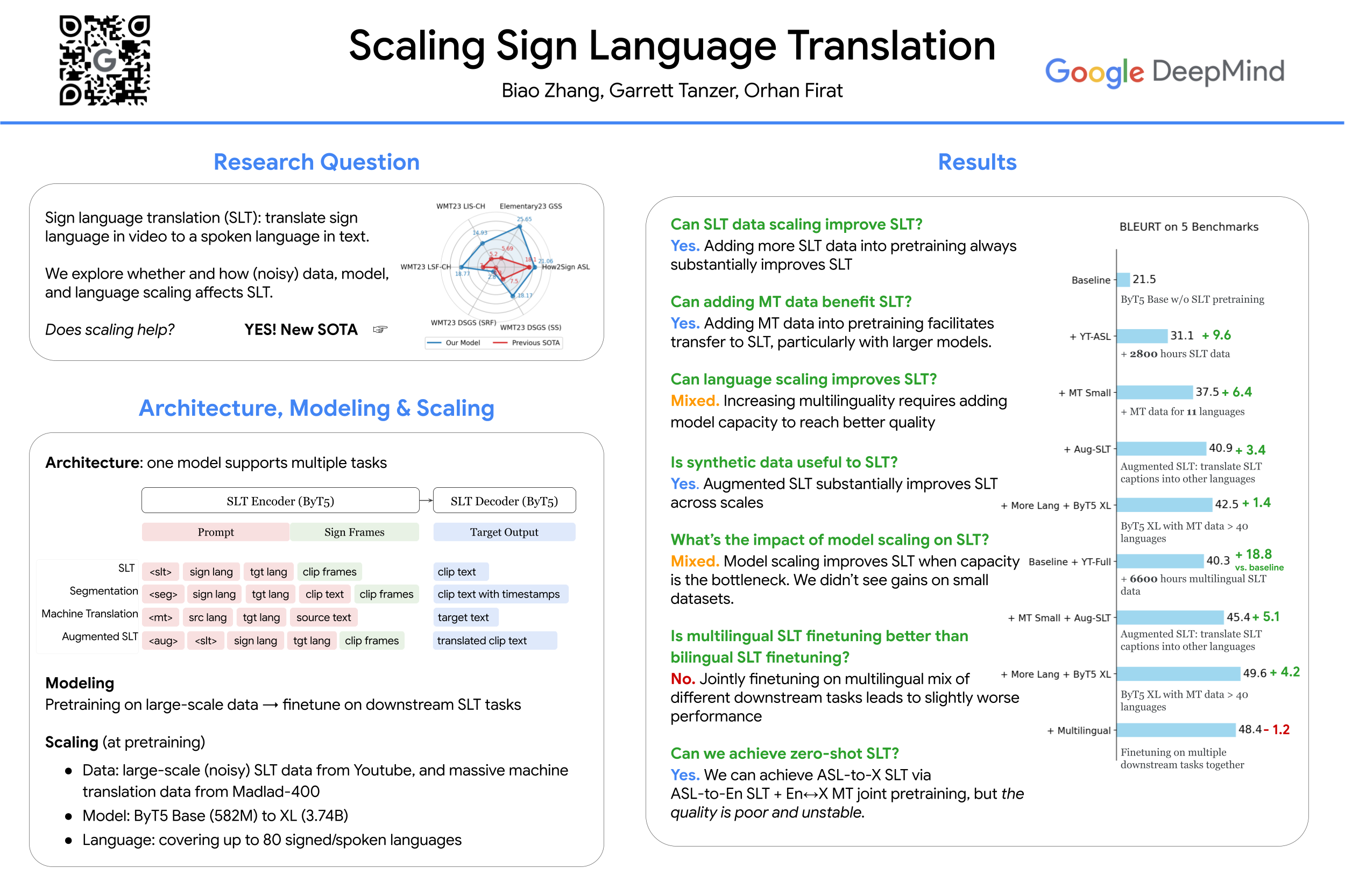
Sign language translation (SLT) addresses the problem of translating information from a sign language in video to a spoken language in text. Existing studies, while showing progress, are often limited to narrow domains and/or few sign languages and struggle with open-domain tasks. In this paper, we push forward the frontier of SLT by scaling pretraining data, model size, and number of translation directions. We perform large-scale SLT pretraining on different data including 1) noisy multilingual Youtube SLT data,2) parallel text corpora, and 3) SLT data augmented by translating video captions to other languages with off-the-shelf machine translation models. We unify different pretraining tasks with task-specific prompts under the encoder-decoder architecture, and initialize the SLT model with pretrained (m/By)T5 models across model sizes. SLT pretraining results on How2Sign and FLEURS-ASL#0 (ASL to 42 spoken languages) demonstrate the significance of data/model scaling and cross-lingual cross-modal transfer, as well as the feasibility of zero-shot SLT. We finetune the pretrained SLT models on 5 downstream open-domain SLT benchmarks covering 5 sign languages. Experiments show substantial quality improvements over the vanilla baselines, surpassing the previous state-of-the-art (SOTA) by wide margins.