A Single-Step, Sharpness-Aware Minimization is All You Need to Achieve Efficient and Accurate Sparse Training
Jie Ji ⋅ Gen Li ⋅ Jingjing Fu ⋅ Fatemeh Afghah ⋅ Linke Guo ⋅ Xiaoyong Yuan ⋅ Xiaolong Ma
2024 Poster
{kind=link}
Abstract
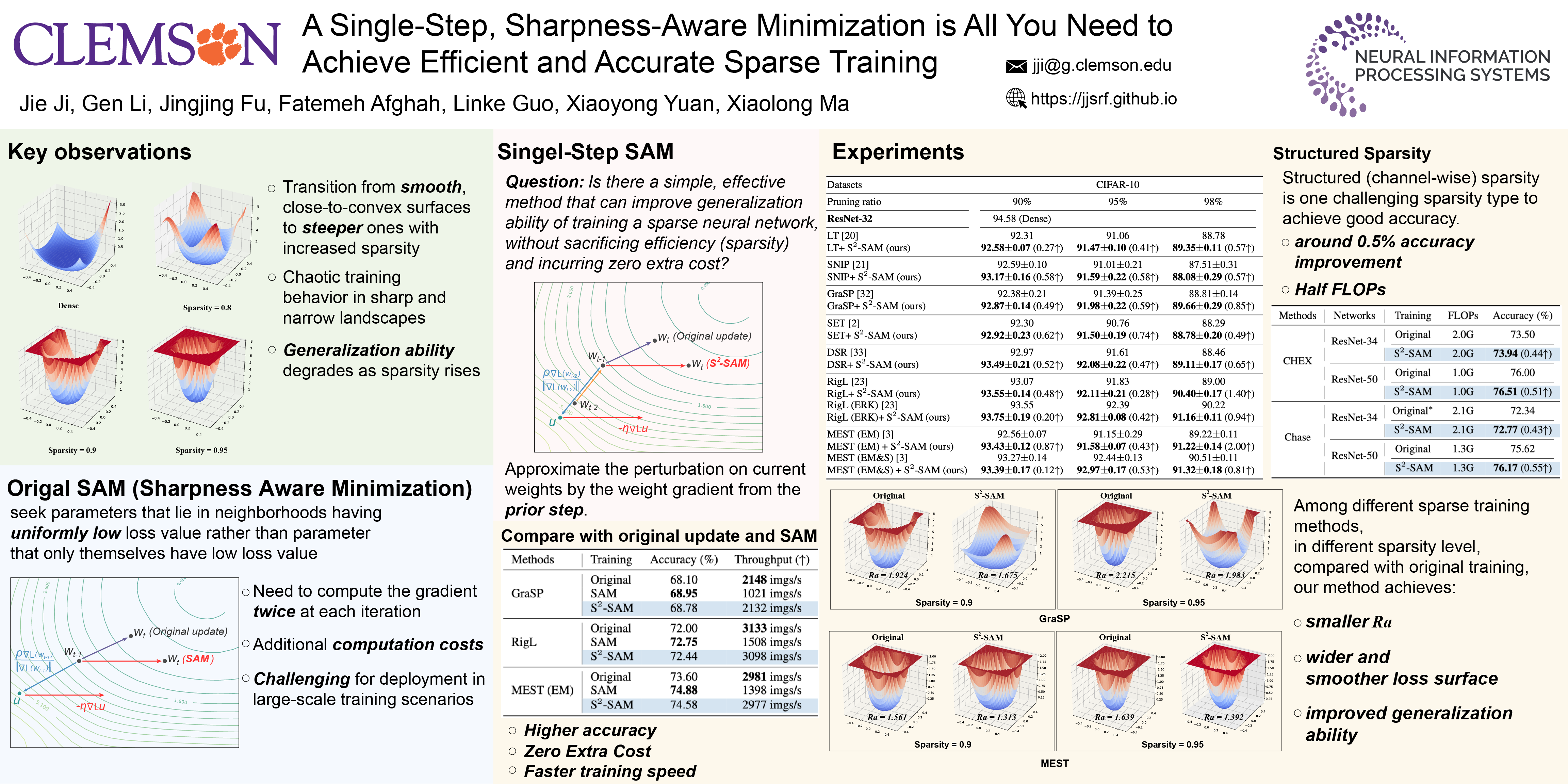
Sparse training stands as a landmark approach in addressing the considerable training resource demands imposed by the continuously expanding size of Deep Neural Networks (DNNs). However, the training of a sparse DNN encounters great challenges in achieving optimal generalization ability despite the efforts from the state-of-the-art sparse training methodologies. To unravel the mysterious reason behind the difficulty of sparse training, we connect the network sparsity with neural loss functions structure, and identify the cause of such difficulty lies in chaotic loss surface. In light of such revelation, we propose $S^{2} - SAM$, characterized by a **S**ingle-step **S**harpness_**A**ware **M**inimization that is tailored for **S**parse training. For the first time, $S^{2} - SAM$ innovates the traditional SAM-style optimization by approximating sharpness perturbation through prior gradient information, incurring *zero extra cost*. Therefore, $S^{2} - SAM$ not only exhibits the capacity to improve generalization but also aligns with the efficiency goal of sparse training. Additionally, we study the generalization result of $S^{2} - SAM$ and provide theoretical proof for convergence. Through extensive experiments, $S^{2} - SAM$ demonstrates its universally applicable plug-and-play functionality, enhancing accuracy across various sparse training methods. Code available at https://github.com/jjsrf/SSAM-NEURIPS2024.
Video
Chat is not available.
Successful Page Load