PTQ4DiT: Post-training Quantization for Diffusion Transformers
Junyi Wu ⋅ Haoxuan Wang ⋅ Yuzhang Shang ⋅ Mubarak Shah ⋅ Yan Yan
2024 Poster
{kind=link}
Abstract
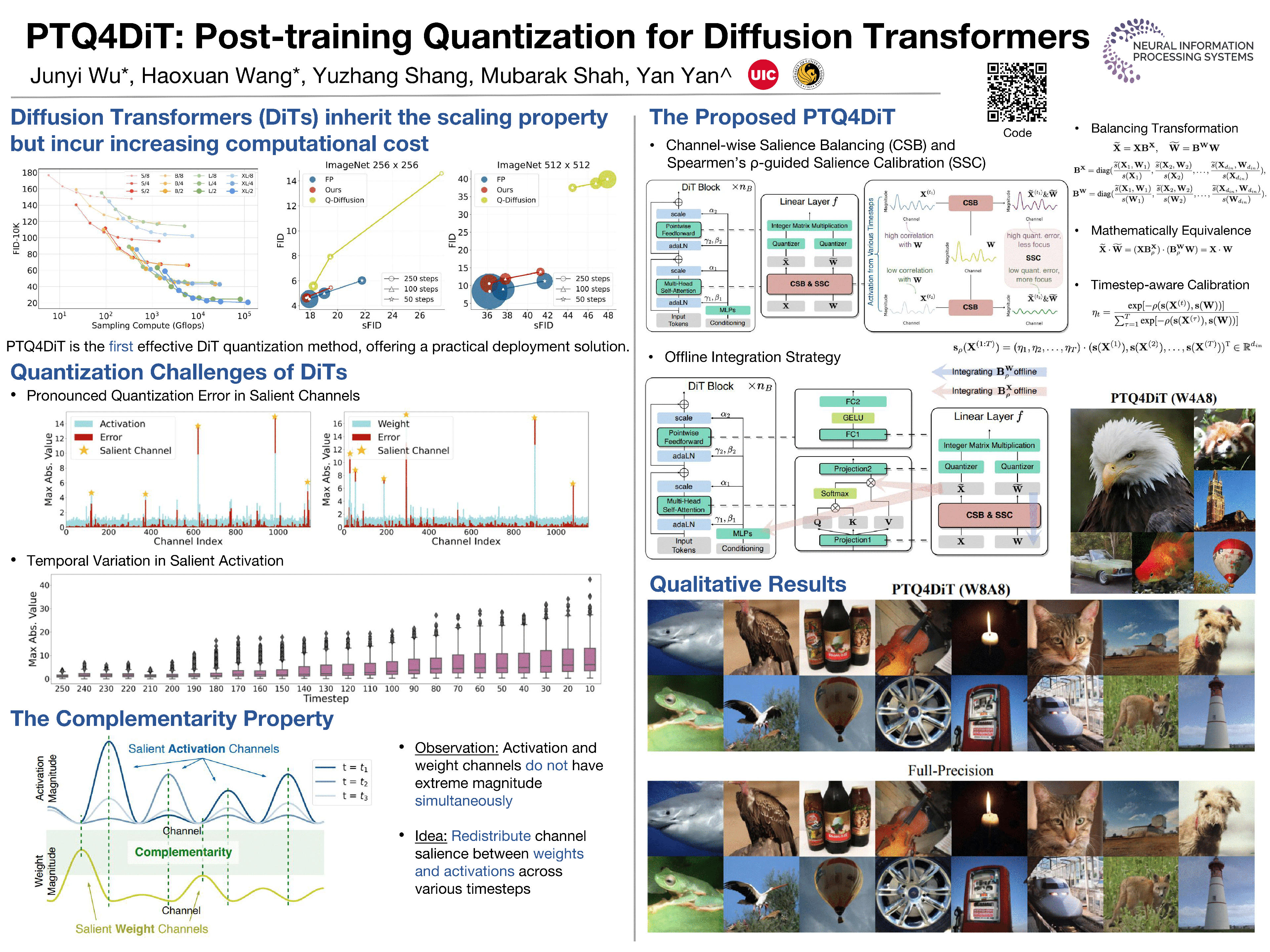
The recent introduction of Diffusion Transformers (DiTs) has demonstrated exceptional capabilities in image generation by using a different backbone architecture, departing from traditional U-Nets and embracing the scalable nature of transformers. Despite their advanced capabilities, the wide deployment of DiTs, particularly for real-time applications, is currently hampered by considerable computational demands at the inference stage. Post-training Quantization (PTQ) has emerged as a fast and data-efficient solution that can significantly reduce computation and memory footprint by using low-bit weights and activations. However, its applicability to DiTs has not yet been explored and faces non-trivial difficulties due to the unique design of DiTs. In this paper, we propose PTQ4DiT, a specifically designed PTQ method for DiTs. We discover two primary quantization challenges inherent in DiTs, notably the presence of salient channels with extreme magnitudes and the temporal variability in distributions of salient activation over multiple timesteps. To tackle these challenges, we propose Channel-wise Salience Balancing (CSB) and Spearmen's $\rho$-guided Salience Calibration (SSC). CSB leverages the complementarity property of channel magnitudes to redistribute the extremes, alleviating quantization errors for both activations and weights. SSC extends this approach by dynamically adjusting the balanced salience to capture the temporal variations in activation. Additionally, to eliminate extra computational costs caused by PTQ4DiT during inference, we design an offline re-parameterization strategy for DiTs. Experiments demonstrate that our PTQ4DiT successfully quantizes DiTs to 8-bit precision (W8A8) while preserving comparable generation ability and further enables effective quantization to 4-bit weight precision (W4A8) for the first time.
Video
Chat is not available.
Successful Page Load