Bayes-optimal learning of an extensive-width neural network from quadratically many samples
{kind=link}
Abstract
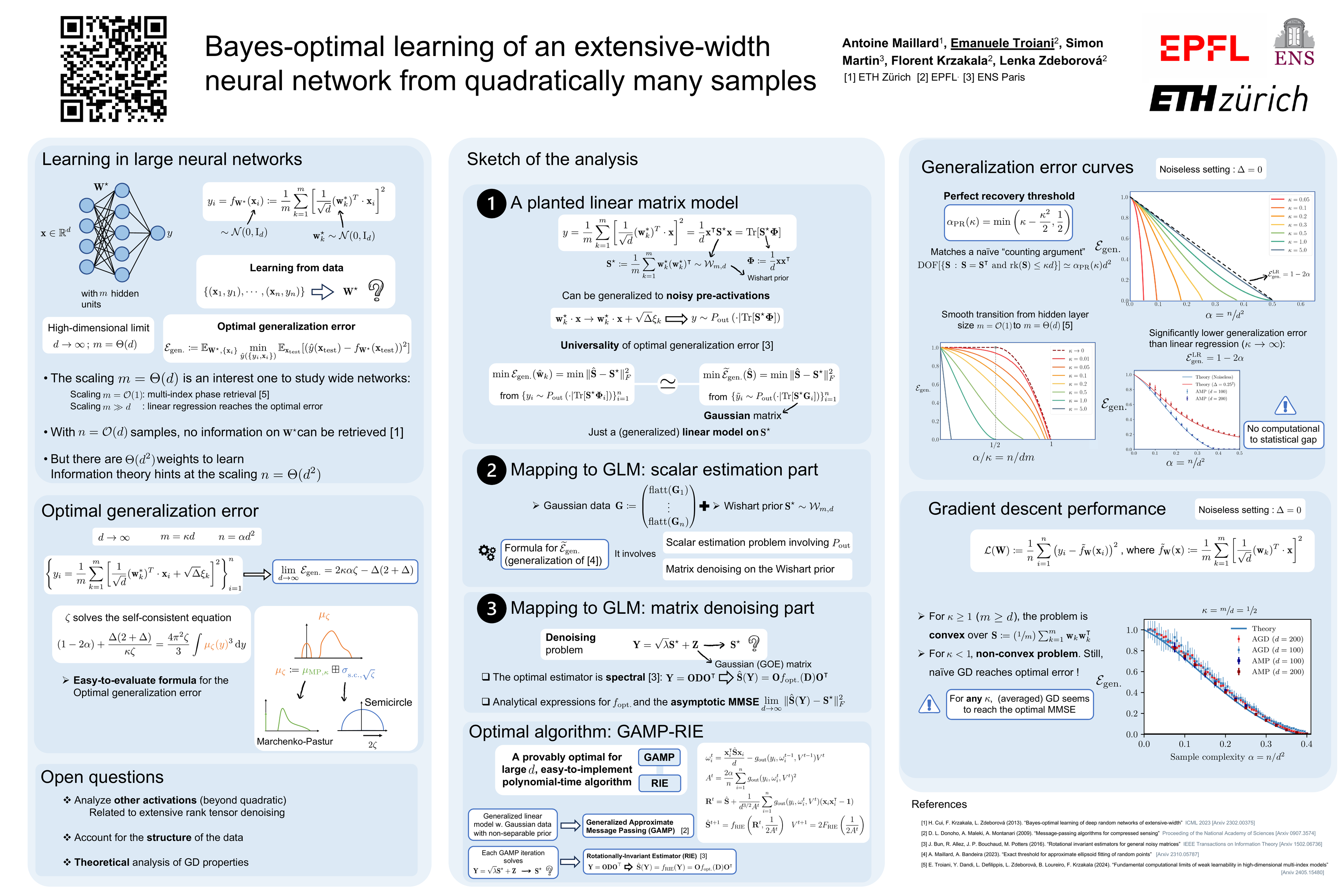
We consider the problem of learning a target function corresponding to a singlehidden layer neural network, with a quadratic activation function after the first layer,and random weights. We consider the asymptotic limit where the input dimensionand the network width are proportionally large. Recent work [Cui et al., 2023]established that linear regression provides Bayes-optimal test error to learn sucha function when the number of available samples is only linear in the dimension.That work stressed the open challenge of theoretically analyzing the optimal testerror in the more interesting regime where the number of samples is quadratic inthe dimension. In this paper, we solve this challenge for quadratic activations andderive a closed-form expression for the Bayes-optimal test error. We also provide analgorithm, that we call GAMP-RIE, which combines approximate message passingwith rotationally invariant matrix denoising, and that asymptotically achieves theoptimal performance. Technically, our result is enabled by establishing a linkwith recent works on optimal denoising of extensive-rank matrices and on theellipsoid fitting problem. We further show empirically that, in the absence ofnoise, randomly-initialized gradient descent seems to sample the space of weights,leading to zero training loss, and averaging over initialization leads to a test errorequal to the Bayes-optimal one.