Lisa: Lazy Safety Alignment for Large Language Models against Harmful Fine-tuning Attack
{kind=link}
Abstract
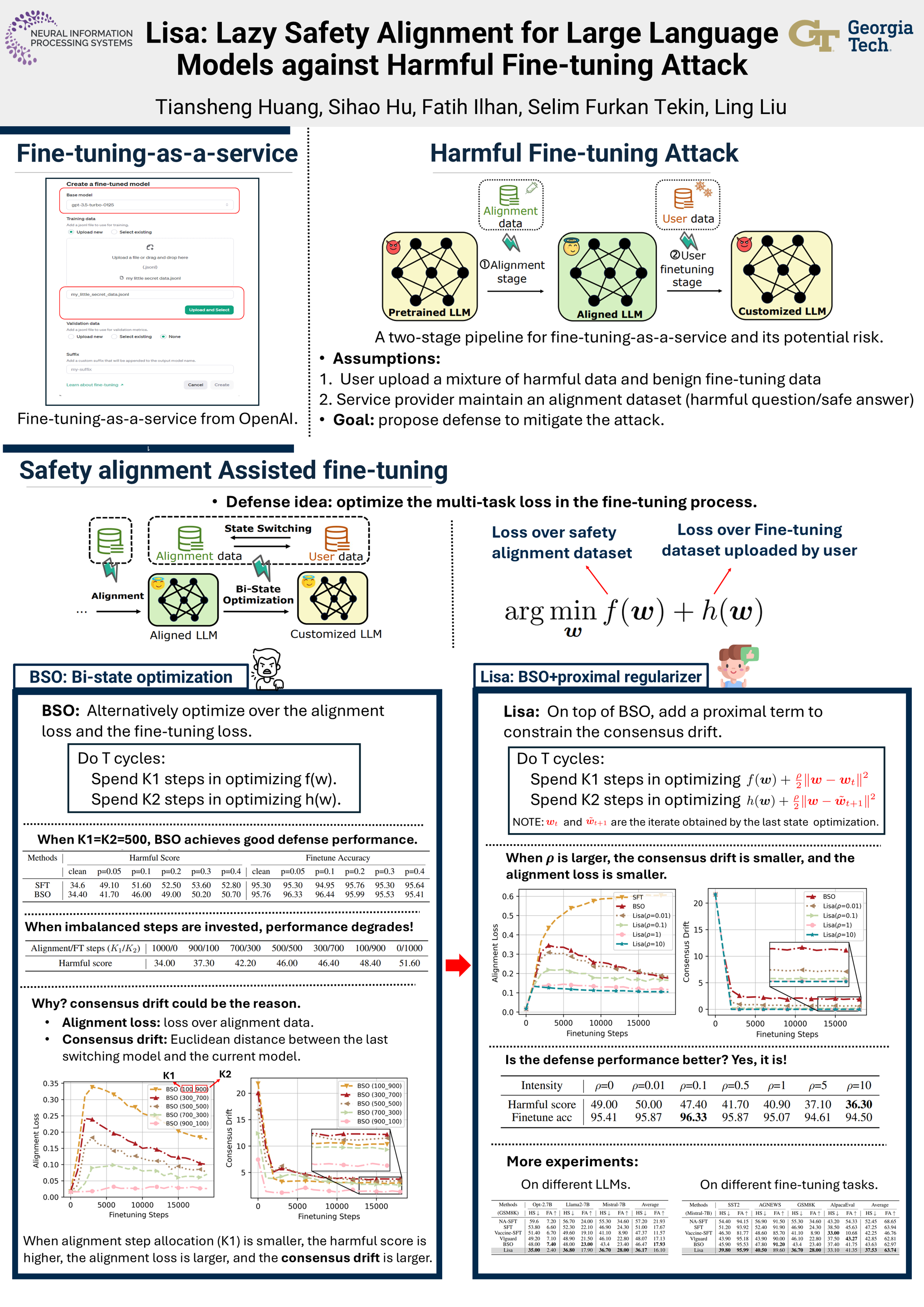
Recent studies show that Large Language Models (LLMs) with safety alignment can be jail-broken by fine-tuning on a dataset mixed with harmful data. For the first time in the literature, we show that the jail-break effect can be mitigated by separating two states in the fine-tuning stage to respectively optimize over the alignment and user datasets. Unfortunately, our subsequent study shows that this simple Bi-State Optimization (BSO) solution experiences convergence instability when steps invested in its alignment state is too small, leading to downgraded alignment performance. By statistical analysis, we show that the \textit{excess drift} towards the switching iterates of the two states could be a probable reason for the instability. To remedy this issue, we propose \textbf{L}azy(\textbf{i}) \textbf{s}afety \textbf{a}lignment (\textbf{Lisa}), which introduces a proximal term to constraint the drift of each state. Theoretically, the benefit of the proximal term is supported by the convergence analysis, wherein we show that a sufficient large proximal factor is necessary to guarantee Lisa's convergence. Empirically, our results on four downstream fine-tuning tasks show that Lisa with a proximal term can significantly increase alignment performance while maintaining the LLM's accuracy on the user tasks. Code is available at https://github.com/git-disl/Lisa.