RanDumb: Random Representations Outperform Online Continually Learned Representations
{kind=link}
Abstract
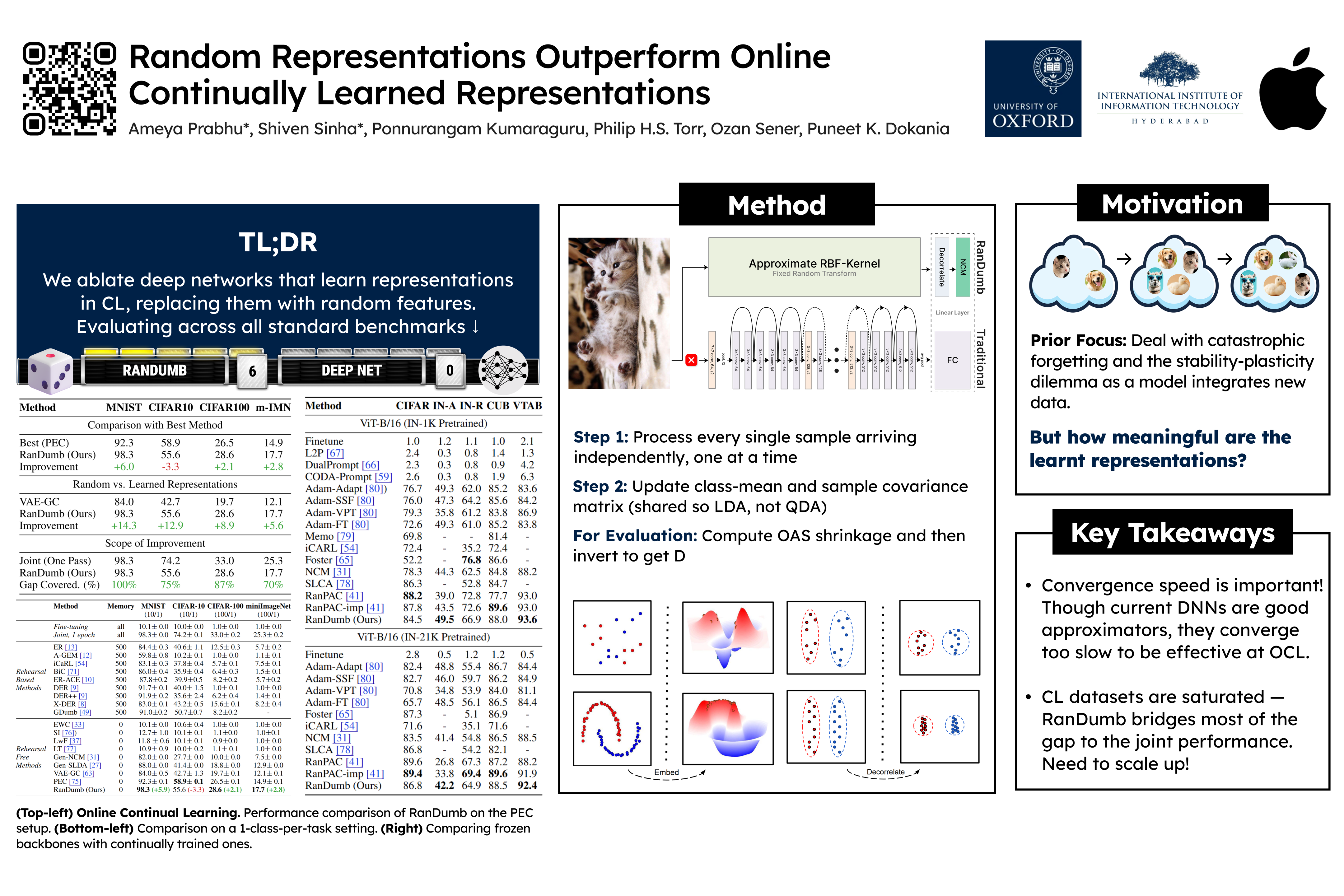
Continual learning has primarily focused on the issue of catastrophic forgetting and the associated stability-plasticity tradeoffs. However, little attention has been paid to the efficacy of continually learned representations, as representations are learned alongside classifiers throughout the learning process. Our primary contribution is empirically demonstrating that existing online continually trained deep networks produce inferior representations compared to a simple pre-defined random transforms. Our approach embeds raw pixels using a fixed random transform, approximating an RBF-Kernel initialized before any data is seen. We then train a simple linear classifier on top without storing any exemplars, processing one sample at a time in an online continual learning setting. This method, called RanDumb, significantly outperforms state-of-the-art continually learned representations across all standard online continual learning benchmarks. Our study reveals the significant limitations of representation learning, particularly in low-exemplar and online continual learning scenarios. Extending our investigation to popular exemplar-free scenarios with pretrained models, we find that training only a linear classifier on top of pretrained representations surpasses most continual fine-tuning and prompt-tuning strategies. Overall, our investigation challenges the prevailing assumptions about effective representation learning in the online continual learning.