Predictor-Corrector Enhanced Transformers with Exponential Moving Average Coefficient Learning
{kind=link}
Abstract
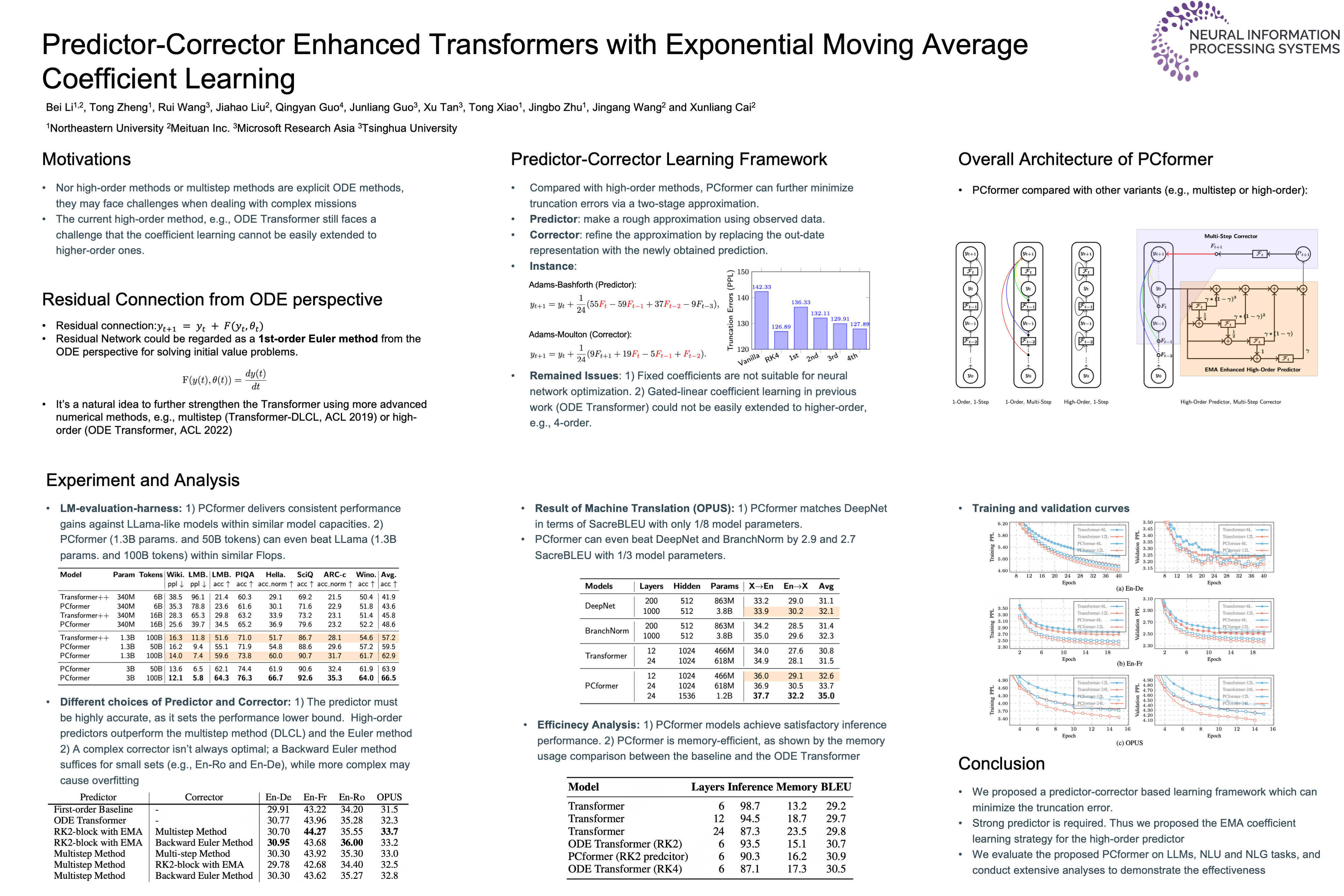
Residual networks, as discrete approximations of Ordinary Differential Equations (ODEs), have inspired significant advancements in neural network design, including multistep methods, high-order methods, and multi-particle dynamical systems. The precision of the solution to ODEs significantly affects parameter optimization, thereby impacting model performance. In this work, we present a series of advanced explorations of Transformer architecture design to minimize the error compared to the true ``solution.'' First, we introduce a predictor-corrector learning framework to minimize truncation errors, which consists of a high-order predictor and a multistep corrector. Second, we propose an exponential moving average-based coefficient learning method to strengthen our higher-order predictor. Extensive experiments on large-scale machine translation, abstractive summarization, language modeling, and natural language understanding benchmarks demonstrate the superiority of our approach. On the WMT'14 English-German and English-French tasks, our model achieved BLEU scores of 30.95 and 44.27, respectively. Furthermore, on the OPUS multilingual machine translation task, our model surpasses a robust 3.8B DeepNet by an average of 2.9 SacreBLEU, using only 1/3 parameters. Notably, it also beats LLama models by 5.7 accuracy points on the LM Harness Evaluation.