Direct Consistency Optimization for Robust Customization of Text-to-Image Diffusion models
{kind=link}
Abstract
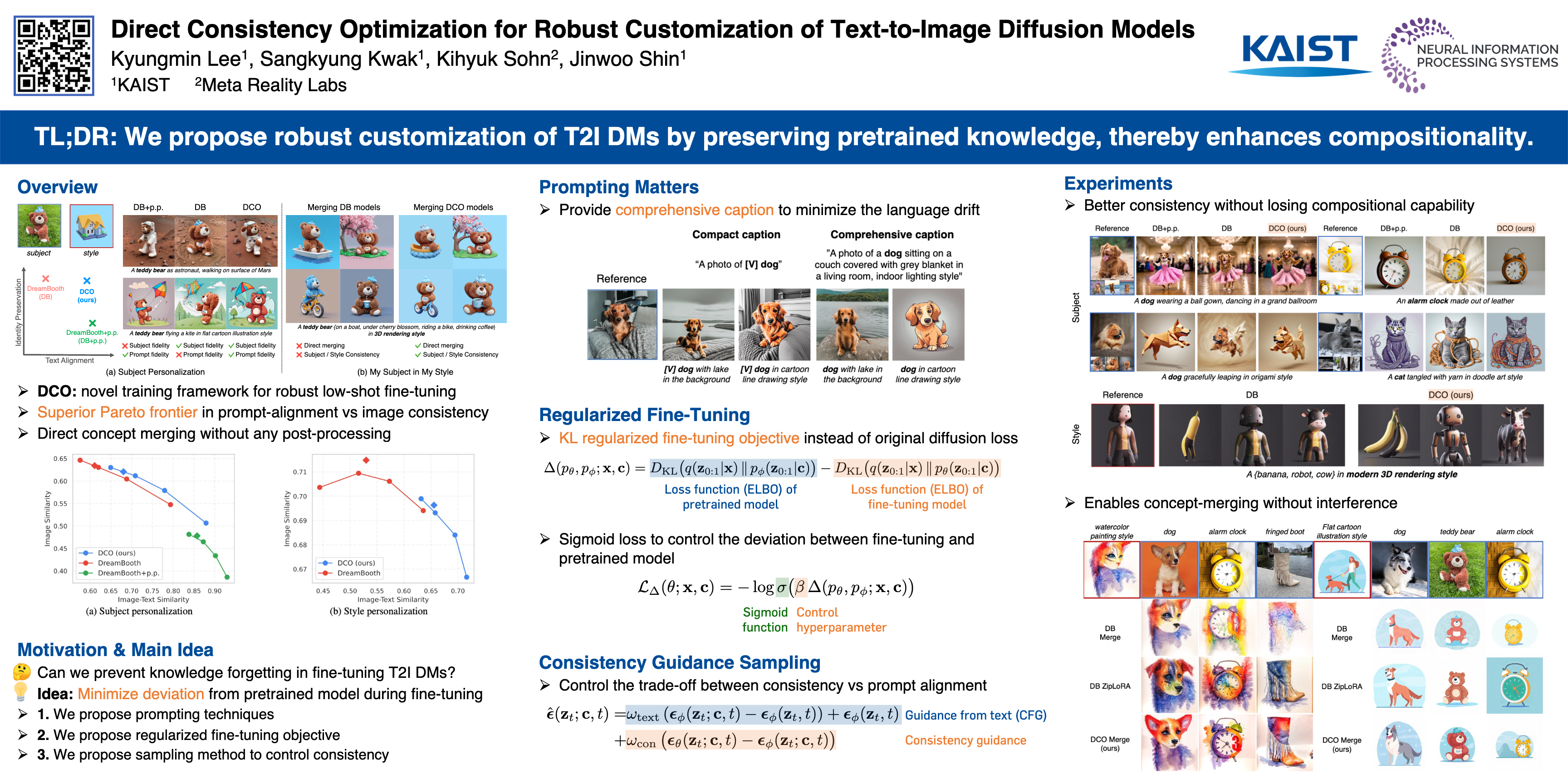
Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, can generate visuals with a high degree of consistency. However, such fine-tuned models are not robust; they often fail to compose with concepts of pretrained model or other fine-tuned models. To address this, we propose a novel fine-tuning objective, dubbed Direct Consistency Optimization, which controls the deviation between fine-tuning and pretrained models to retain the pretrained knowledge during fine-tuning. Through extensive experiments on subject and style customization, we demonstrate that our method positions itself on a superior Pareto frontier between subject (or style) consistency and image-text alignment over all previous baselines; it not only outperforms regular fine-tuning objective in image-text alignment, but also shows higher fidelity to the reference images than the method that fine-tunes with additional prior dataset. More importantly, the models fine-tuned with our method can be merged without interference, allowing us to generate custom subjects in a custom style by composing separately customized subject and style models. Notably, we show that our approach achieves better prompt fidelity and subject fidelity than those post-optimized for merging regular fine-tuned models.