Learning World Models for Unconstrained Goal Navigation
{kind=link}
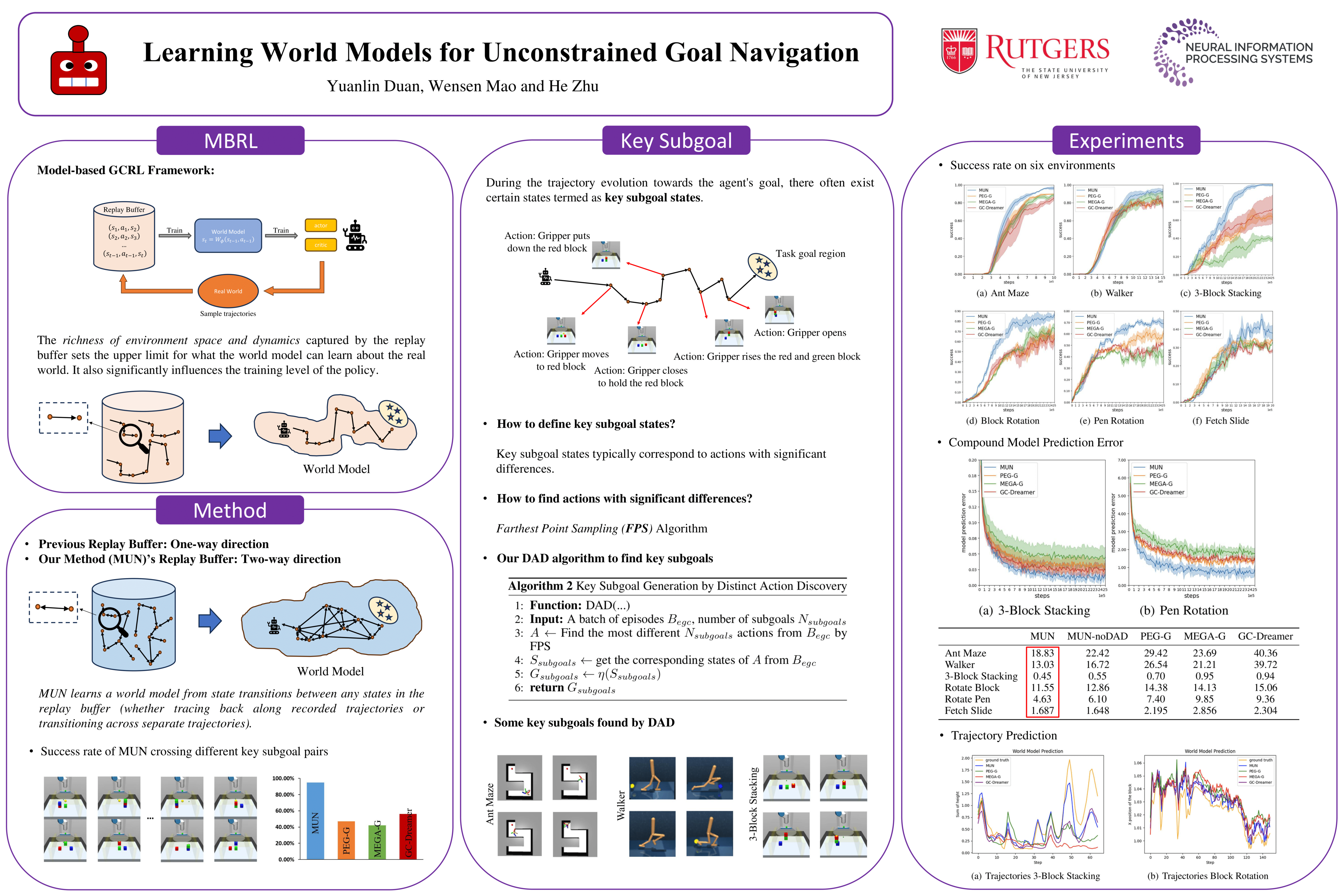
Abstract
Learning world models offers a promising avenue for goal-conditioned reinforcement learning with sparse rewards. By allowing agents to plan actions or exploratory goals without direct interaction with the environment, world models enhance exploration efficiency. The quality of a world model hinges on the richness of data stored in the agent's replay buffer, with expectations of reasonable generalization across the state space surrounding recorded trajectories. However, challenges arise in generalizing learned world models to state transitions backward along recorded trajectories or between states across different trajectories, hindering their ability to accurately model real-world dynamics. To address these challenges, we introduce a novel goal-directed exploration algorithm, MUN (short for "World Models for Unconstrained Goal Navigation"). This algorithm is capable of modeling state transitions between arbitrary subgoal states in the replay buffer, thereby facilitating the learning of policies to navigate between any "key" states. Experimental results demonstrate that MUN strengthens the reliability of world models and significantly improves the policy's capacity to generalize across new goal settings.