Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
{kind=link}
Abstract
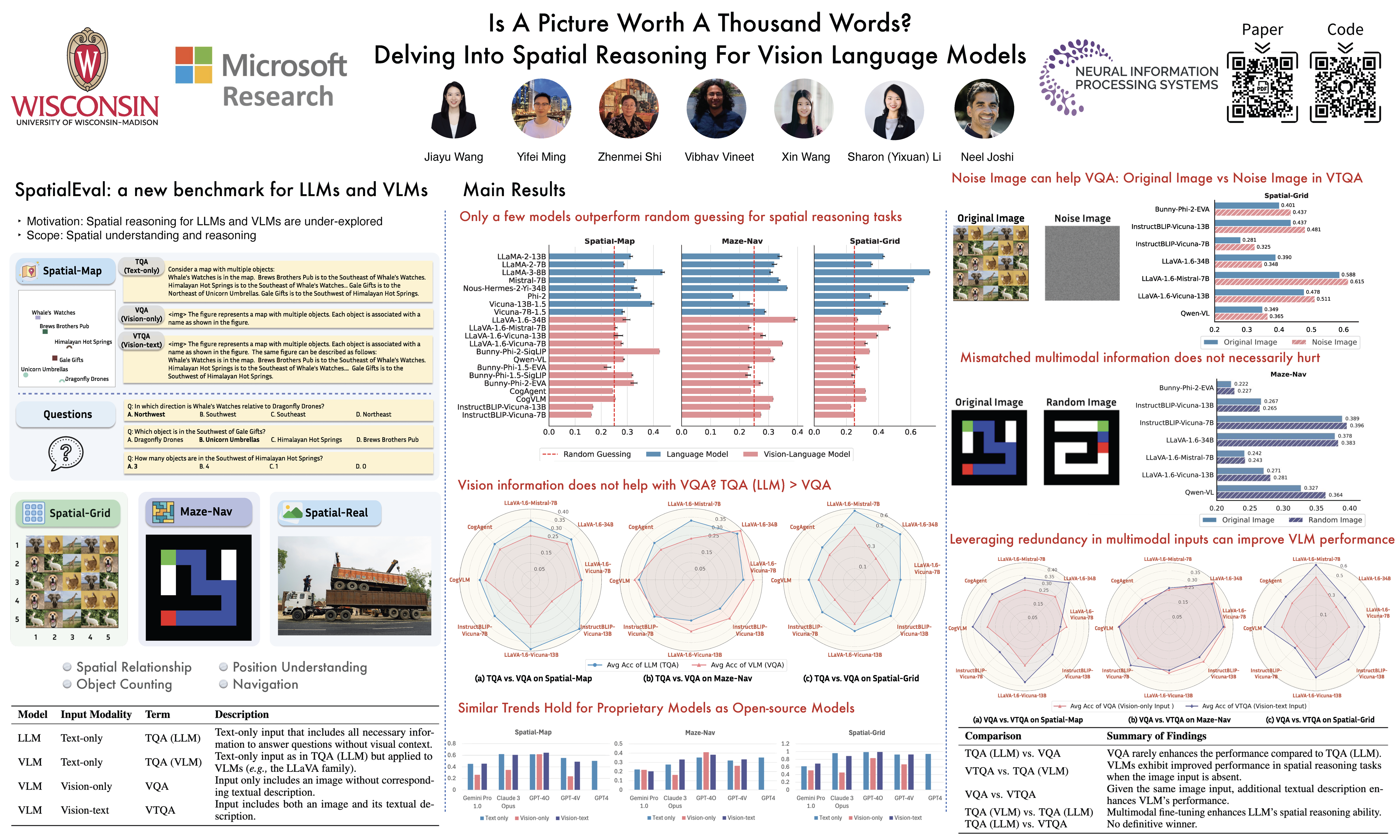
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning—a fundamental component of human cognition—remains under-explored. We propose SpatialEval, a novel benchmark that covers diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence. Our code is available at https://github.com/jiayuww/SpatialEval.