EPIC: Effective Prompting for Imbalanced-Class Data Synthesis in Tabular Data Classification via Large Language Models
{kind=link}
Abstract
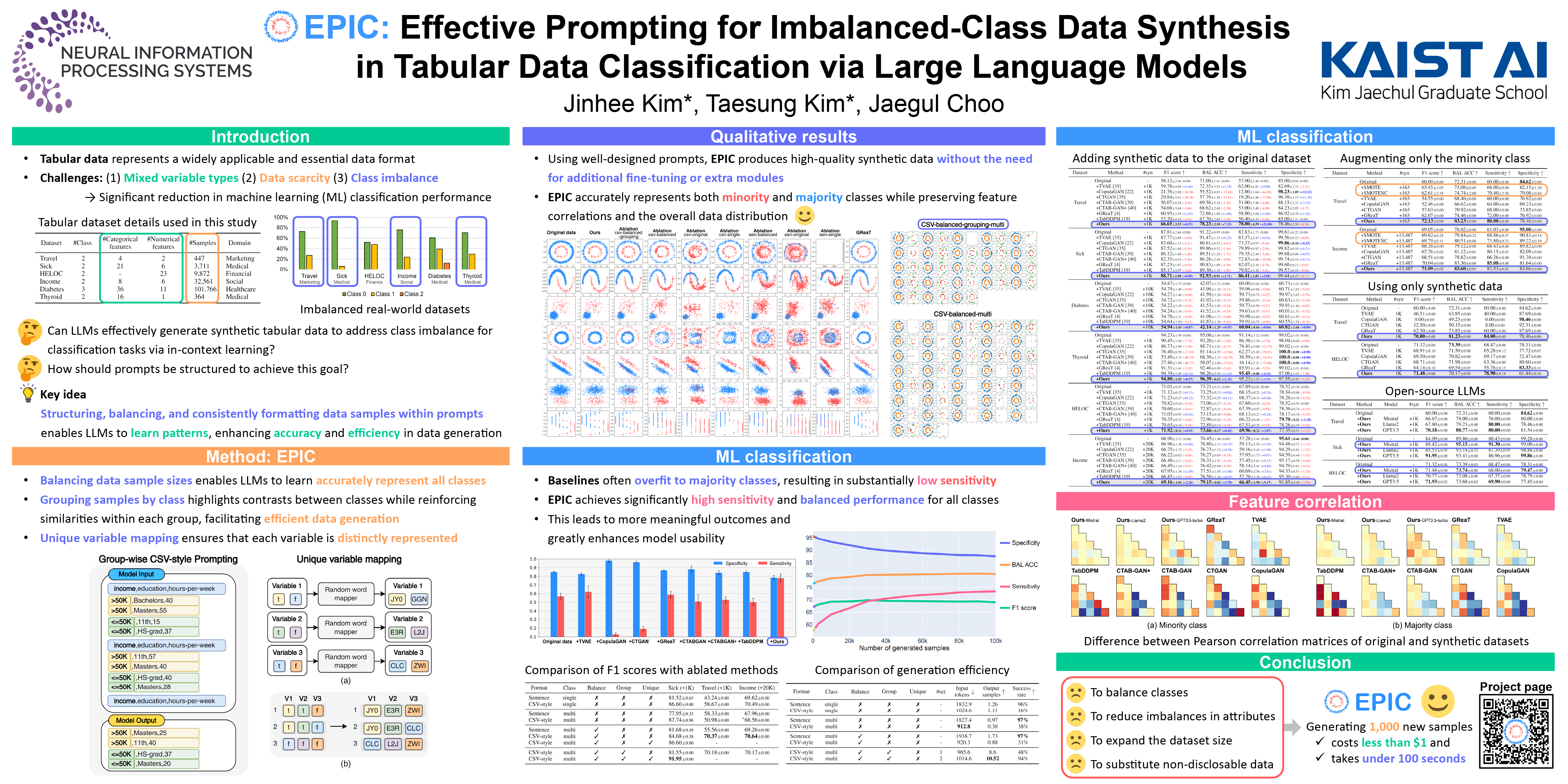
Large language models (LLMs) have demonstrated remarkable in-context learning capabilities across diverse applications. In this work, we explore the effectiveness of LLMs for generating realistic synthetic tabular data, identifying key prompt design elements to optimize performance. We introduce EPIC, a novel approach that leverages balanced, grouped data samples and consistent formatting with unique variable mapping to guide LLMs in generating accurate synthetic data across all classes, even for imbalanced datasets. Evaluations on real-world datasets show that EPIC achieves state-of-the-art machine learning classification performance, significantly improving generation efficiency. These findings highlight the effectiveness of EPIC for synthetic tabular data generation, particularly in addressing class imbalance.