BoNBoN Alignment for Large Language Models and the Sweetness of Best-of-n Sampling
Lin Gui ⋅ Cristina Garbacea ⋅ Victor Veitch
2024 Poster
{kind=link}
Abstract
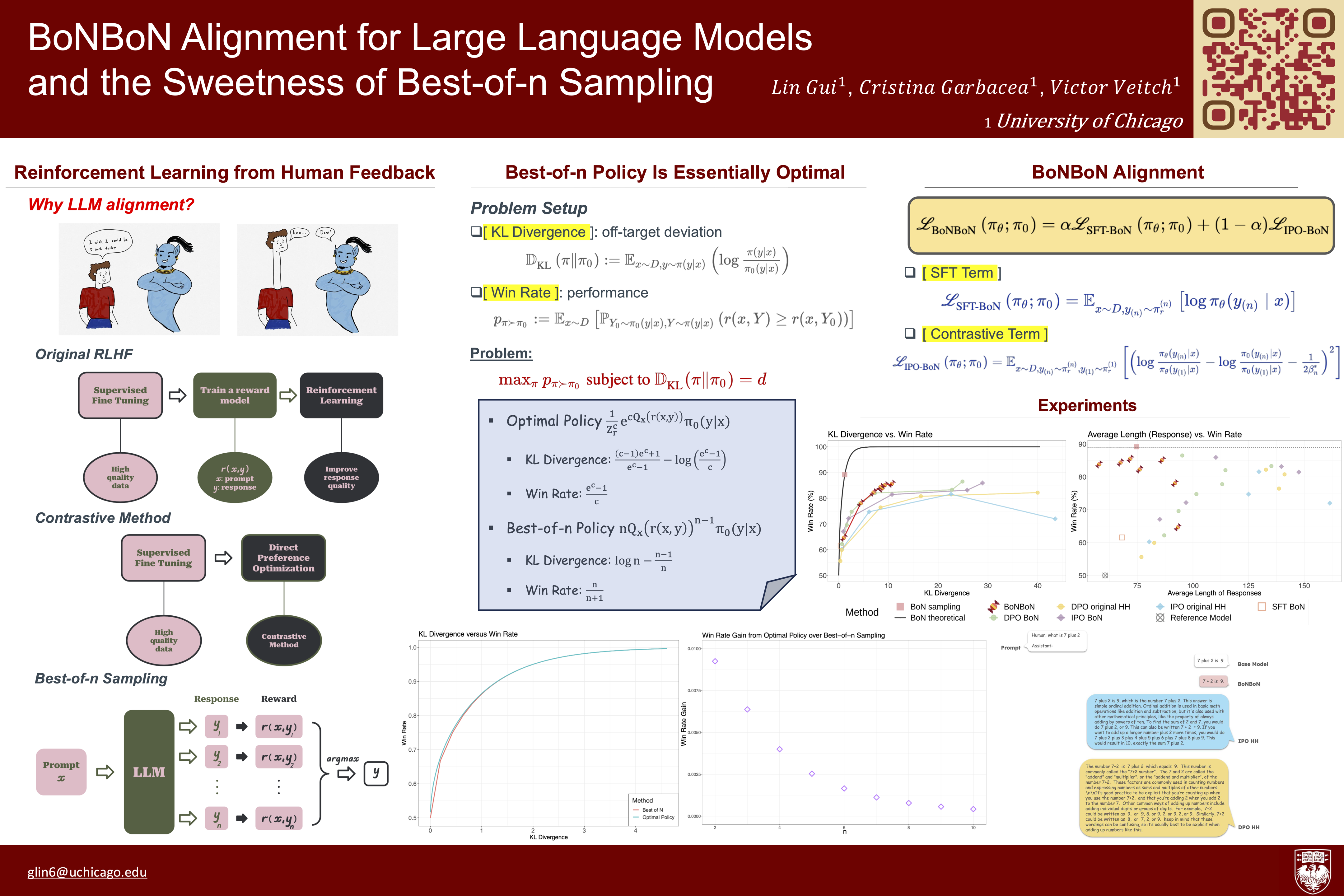
This paper concerns the problem of aligning samples from large language models to human preferences using *best-of-$n$* sampling, where we draw $n$ samples, rank them, and return the best one. We consider two fundamental problems. First: what is the relationship between best-of-$n$ and other (RLHF-type) approaches to aligning LLMs? In particular, when should one be preferred to the other? We show that the best-of-$n$ sampling distribution is essentially equivalent to the policy learned by RLHF if we apply a particular monotone transformation to the reward function. Moreover, we show that this transformation yields the best possible trade-off between win-rate against the base model vs KL distance from the base model. Then, best-of-$n$ is a Pareto-optimal win-rate vs KL solution.The second problem we consider is how to fine-tune a model to mimic the best-of-$n$ sampling distribution, to avoid drawing $n$ samples for each inference. We derive *BonBon Alignment* as a method for achieving this. Experiments show that BonBon alignment yields a model that achieves high win rates while minimally affecting off-target aspects of the generations.
Video
Chat is not available.
Successful Page Load