Lumina-Next : Making Lumina-T2X Stronger and Faster with Next-DiT
{kind=link}
Abstract
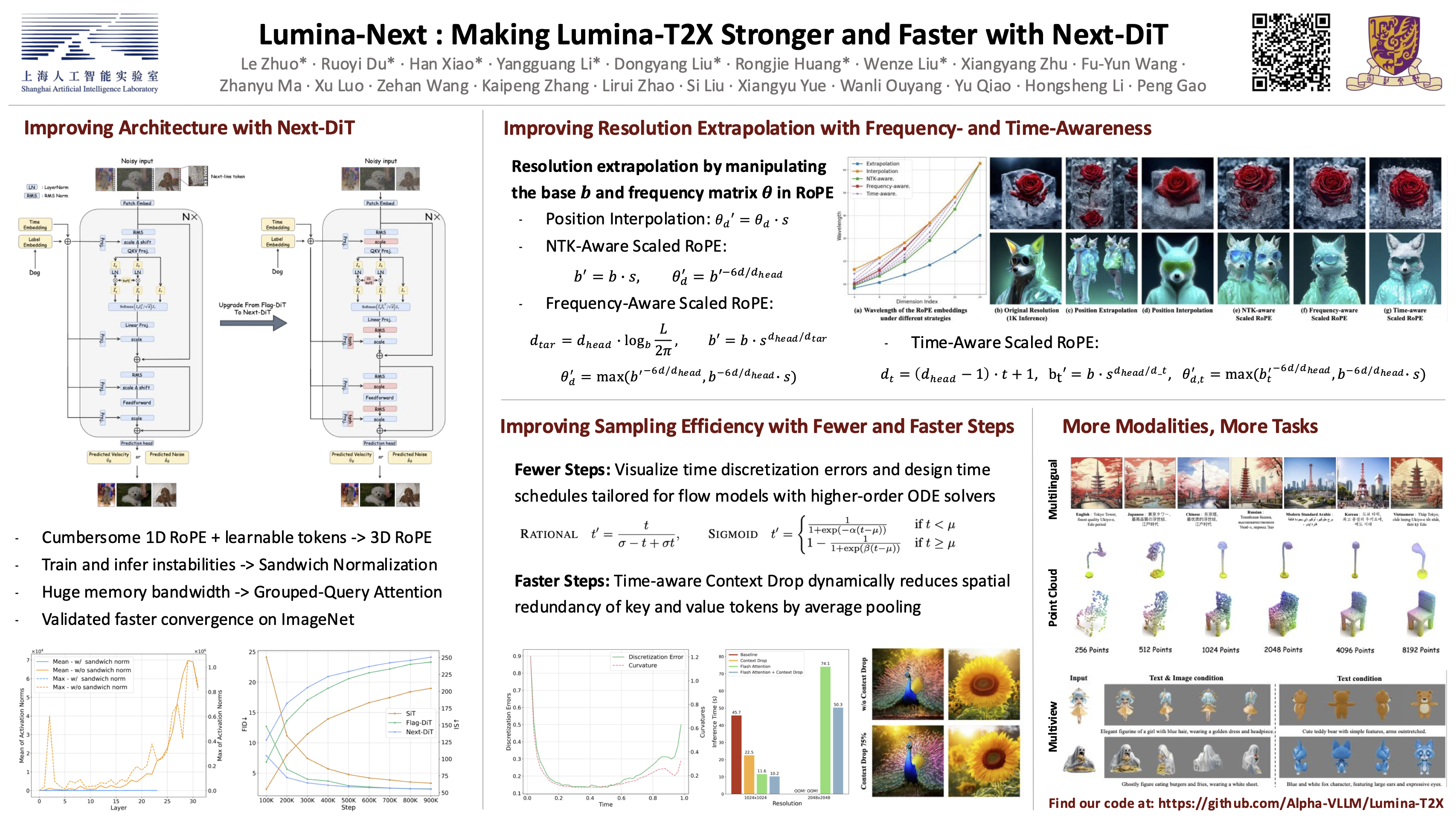
Lumina-T2X is a nascent family of Flow-based Large Diffusion Transformers (Flag-DiT) that establishes a unified framework for transforming noise into various modalities, such as images and videos, conditioned on text instructions. Despite its promising capabilities, Lumina-T2X still encounters challenges including training instability, slow inference, and extrapolation artifacts. In this paper, we present Lumina-Next, an improved version of Lumina-T2X, showcasing stronger generation performance with increased training and inference efficiency. We begin with a comprehensive analysis of the Flag-DiT architecture and identify several suboptimal components, which we address by introducing the Next-DiT architecture with 3D RoPE and sandwich normalizations. To enable better resolution extrapolation, we thoroughly compare different context extrapolation methods applied to text-to-image generation with 3D RoPE, and propose Frequency- and Time-Aware Scaled RoPE tailored for diffusion transformers. Additionally, we introduce a sigmoid time discretization schedule for diffusion sampling, which achieves high-quality generation in 5-10 steps combined with higher-order ODE solvers. Thanks to these improvements, Lumina-Next not only improves the basic text-to-image generation but also demonstrates superior resolution extrapolation capabilities as well as multilingual generation using decoder-based LLMs as the text encoder, all in a zero-shot manner. To further validate Lumina-Next as a versatile generative framework, we instantiate it on diverse tasks including visual recognition, multi-views, audio, music, and point cloud generation, showcasing strong performance across these domains. By releasing all codes and model weights at https://github.com/Alpha-VLLM/Lumina-T2X, we aim to advance the development of next-generation generative AI capable of universal modeling.