Data Attribution for Text-to-Image Models by Unlearning Synthesized Images
{kind=link}
Abstract
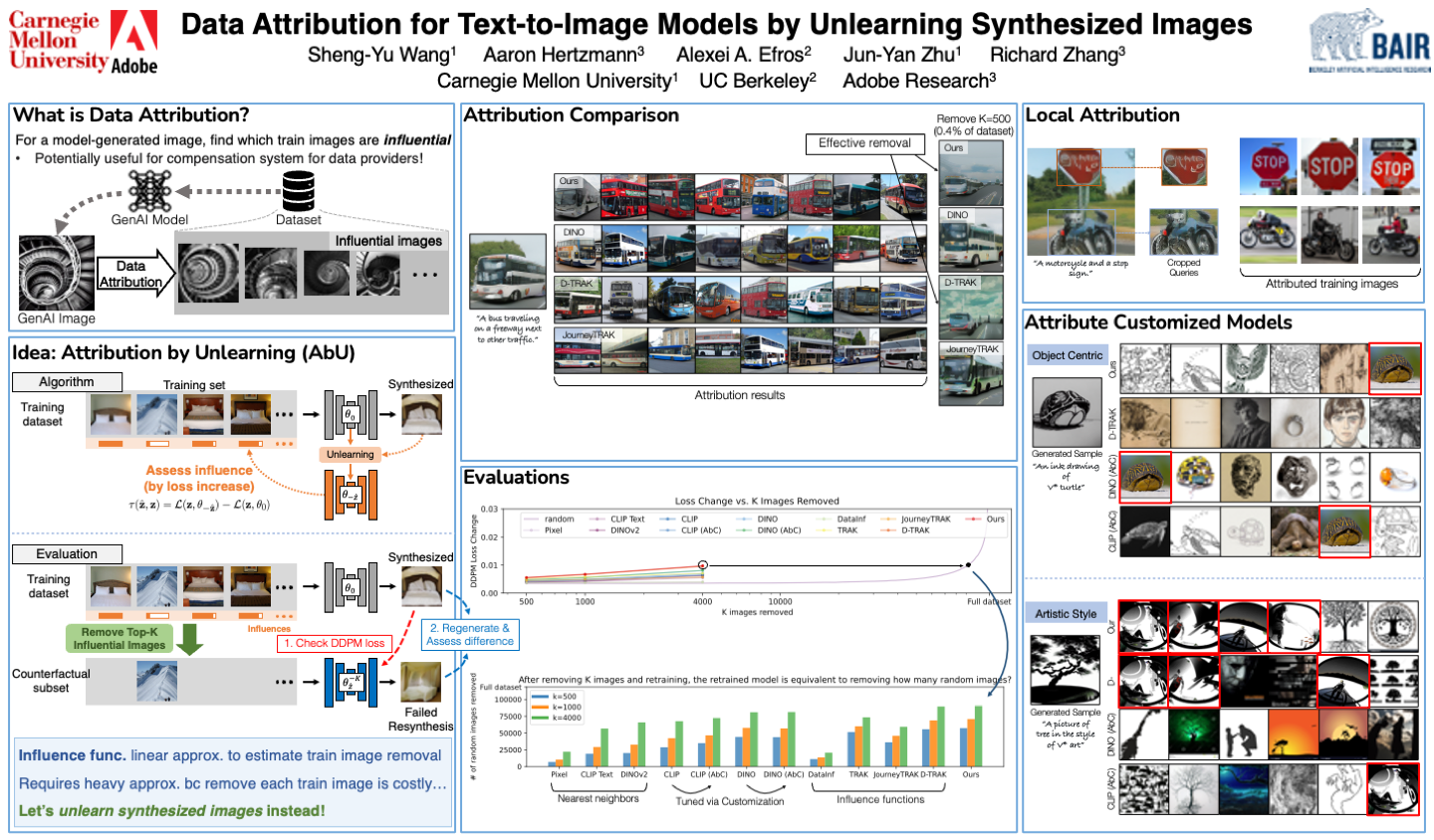
The goal of data attribution for text-to-image models is to identify the training images that most influence the generation of a new image. Influence is defined such that, for a given output, if a model is retrained from scratch without the most influential images, the model would fail to reproduce the same output. Unfortunately, directly searching for these influential images is computationally infeasible, since it would require repeatedly retraining models from scratch. In our work, we propose an efficient data attribution method by simulating unlearning the synthesized image. We achieve this by increasing the training loss on the output image, without catastrophic forgetting of other, unrelated concepts. We then identify training images with significant loss deviations after the unlearning process and label these as influential. We evaluate our method with a computationally intensive but "gold-standard" retraining from scratch and demonstrate our method's advantages over previous methods.