Visual Fourier Prompt Tuning
{kind=link}
Abstract
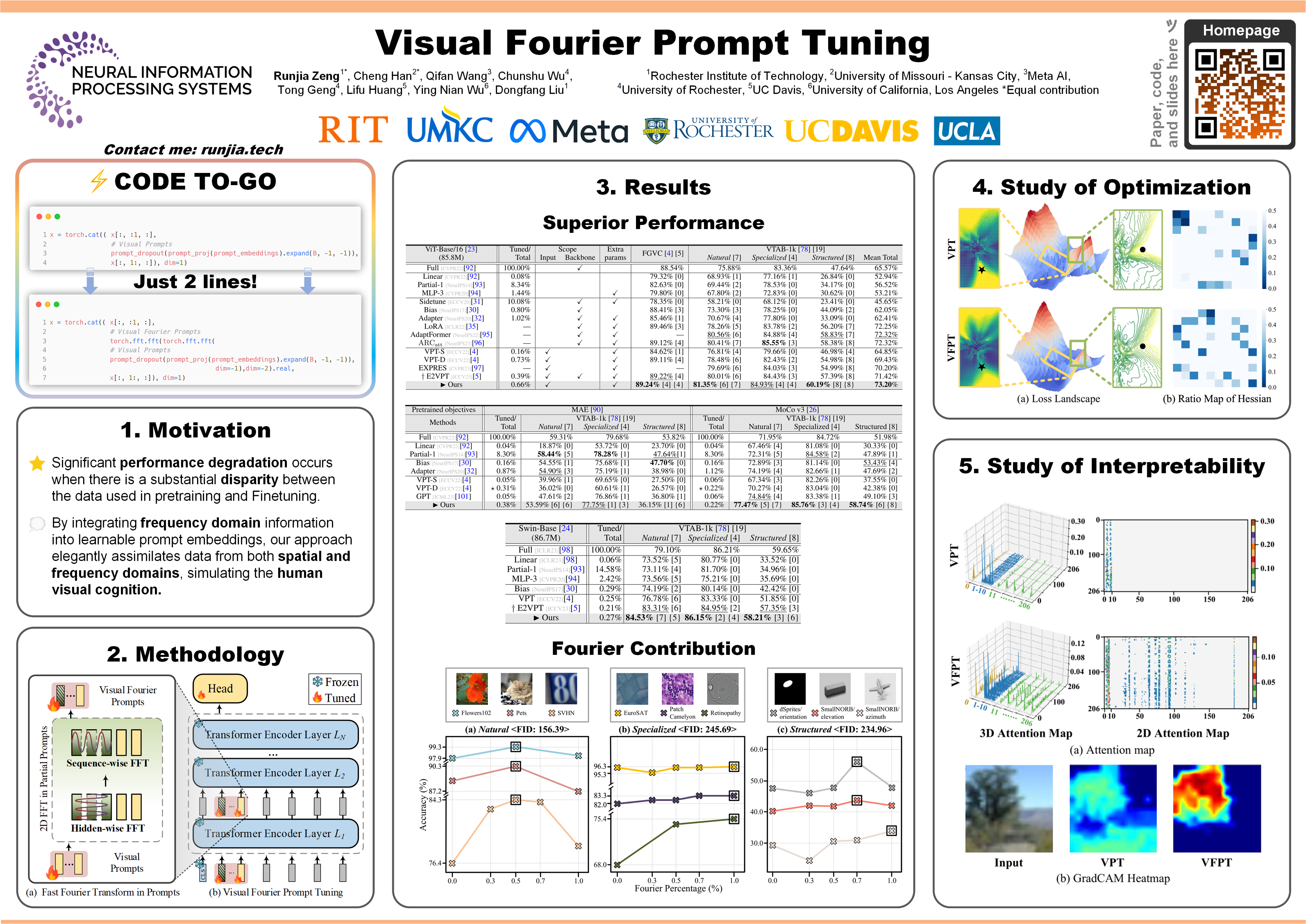
With the scale of vision Transformer-based models continuing to grow, finetuning these large-scale pretrained models for new tasks has become increasingly parameter-intensive. Visual prompt tuning is introduced as a parameter-efficient finetuning (PEFT) method to this trend. Despite its successes, a notable research challenge persists within almost all PEFT approaches: significant performance degradation is observed when there is a substantial disparity between the datasets applied in pretraining and finetuning phases. To address this challenge, we draw inspiration from human visual cognition, and propose the Visual Fourier Prompt Tuning (VFPT) method as a general and effective solution for adapting large-scale transformer-based models. Our approach innovatively incorporates the Fast Fourier Transform into prompt embeddings and harmoniously considers both spatial and frequency domain information. Apart from its inherent simplicity and intuitiveness, VFPT exhibits superior performance across all datasets, offering a general solution to dataset challenges, irrespective of data disparities. Empirical results demonstrate that our approach outperforms current state-of-the-art baselines on two benchmarks, with low parameter usage (e.g., 0.57% of model parameters on VTAB-1k) and notable performance enhancements (e.g., 73.20% of mean accuracy on VTAB-1k). Our code is avaliable at https://github.com/runtsang/VFPT.