Efficient Recurrent Off-Policy RL Requires a Context-Encoder-Specific Learning Rate
{kind=link}
Abstract
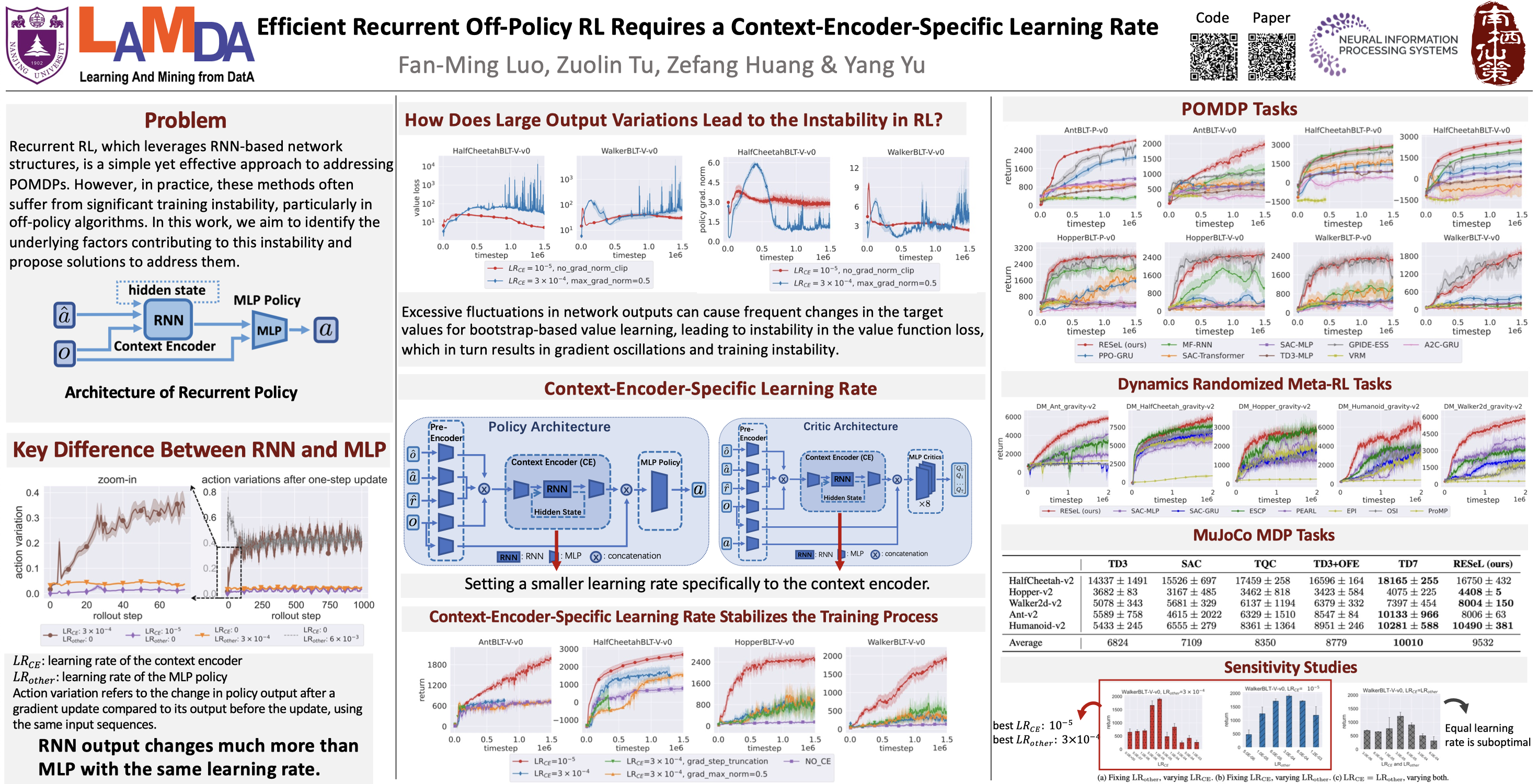
Real-world decision-making tasks are usually partially observable Markov decision processes (POMDPs), where the state is not fully observable. Recent progress has demonstrated that recurrent reinforcement learning (RL), which consists of a context encoder based on recurrent neural networks (RNNs) for unobservable state prediction and a multilayer perceptron (MLP) policy for decision making, can mitigate partial observability and serve as a robust baseline for POMDP tasks. However, prior recurrent RL algorithms have faced issues with training instability. In this paper, we find that this instability stems from the autoregressive nature of RNNs, which causes even small changes in RNN parameters to produce large output variations over long trajectories. Therefore, we propose Recurrent Off-policy RL with Context-Encoder-Specific Learning Rate (RESeL) to tackle this issue. Specifically, RESeL uses a lower learning rate for context encoder than other MLP layers to ensure the stability of the former while maintaining the training efficiency of the latter. We integrate this technique into existing off-policy RL methods, resulting in the RESeL algorithm. We evaluated RESeL in 18 POMDP tasks, including classic, meta-RL, and credit assignment scenarios, as well as five MDP locomotion tasks. The experiments demonstrate significant improvements in training stability with RESeL. Comparative results show that RESeL achieves notable performance improvements over previous recurrent RL baselines in POMDP tasks, and is competitive with or even surpasses state-of-the-art methods in MDP tasks. Further ablation studies highlight the necessity of applying a distinct learning rate for the context encoder. Code is available at https://github.com/FanmingL/Recurrent-Offpolicy-RL.