Learning from higher-order correlations, efficiently: hypothesis tests, random features, and neural networks
Eszter Szekely ⋅ Lorenzo Bardone ⋅ Federica Gerace ⋅ Sebastian Goldt
2024 Poster
{kind=link}
Abstract
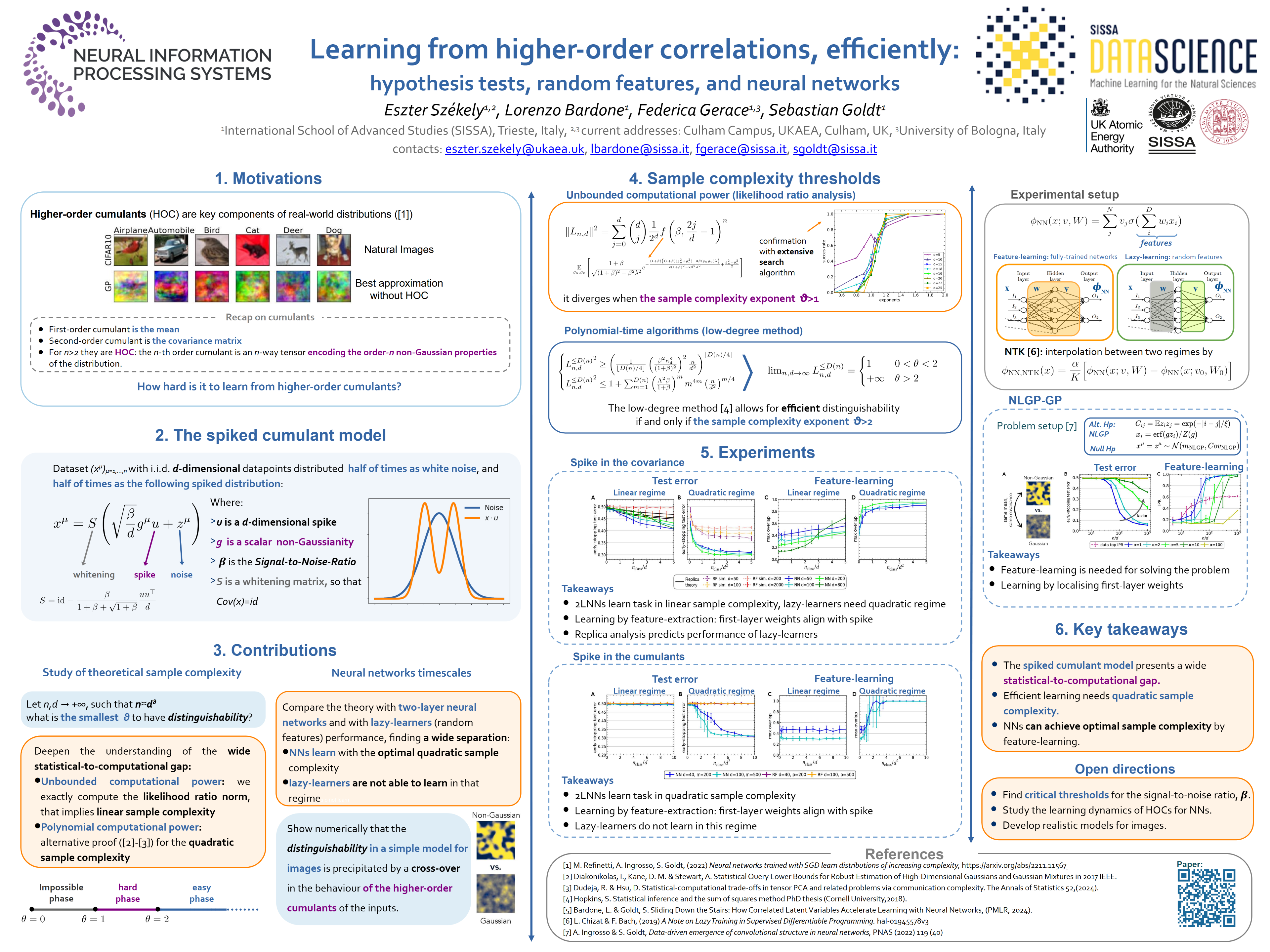
Neural networks excel at discovering statistical patterns inhigh-dimensional data sets. In practice, higher-order cumulants, which quantifythe non-Gaussian correlations between three or more variables, are particularlyimportant for the performance of neural networks. But how efficient are neuralnetworks at extracting features from higher-order cumulants? We study thisquestion in the spiked cumulant model, where the statistician needs to recover aprivileged direction or "spike'' from the order-$p\ge 4$ cumulantsof $d$-dimensional inputs. We first discuss the fundamental statistical andcomputational limits of recovering the spike by analysing the number of samples $n$ required to strongly distinguish between inputs from the spikedcumulant model and isotropic Gaussian inputs. Existing literature established the presence of a wide statistical-to-computational gap in this problem. We deepen this line of work by finding an exact formula for the likelihood ratio norm which proves that statisticaldistinguishability requires $n\gtrsim d$ samples, while distinguishing the twodistributions in polynomial time requires $n \gtrsim d^2$ samples for a wideclass of algorithms, i.e. those covered by the low-degree conjecture. Numerical experiments show that neural networks do indeed learn to distinguishthe two distributions with quadratic sample complexity, while ``lazy'' methodslike random features are not better than random guessing in this regime. Ourresults show that neural networks extract information from higher-ordercorrelations in the spiked cumulant model efficiently, and reveal a large gap inthe amount of data required by neural networks and random features to learn fromhigher-order cumulants.
Video
Chat is not available.
Successful Page Load