Measuring Dejavu Memorization Efficiently
{kind=link}
Abstract
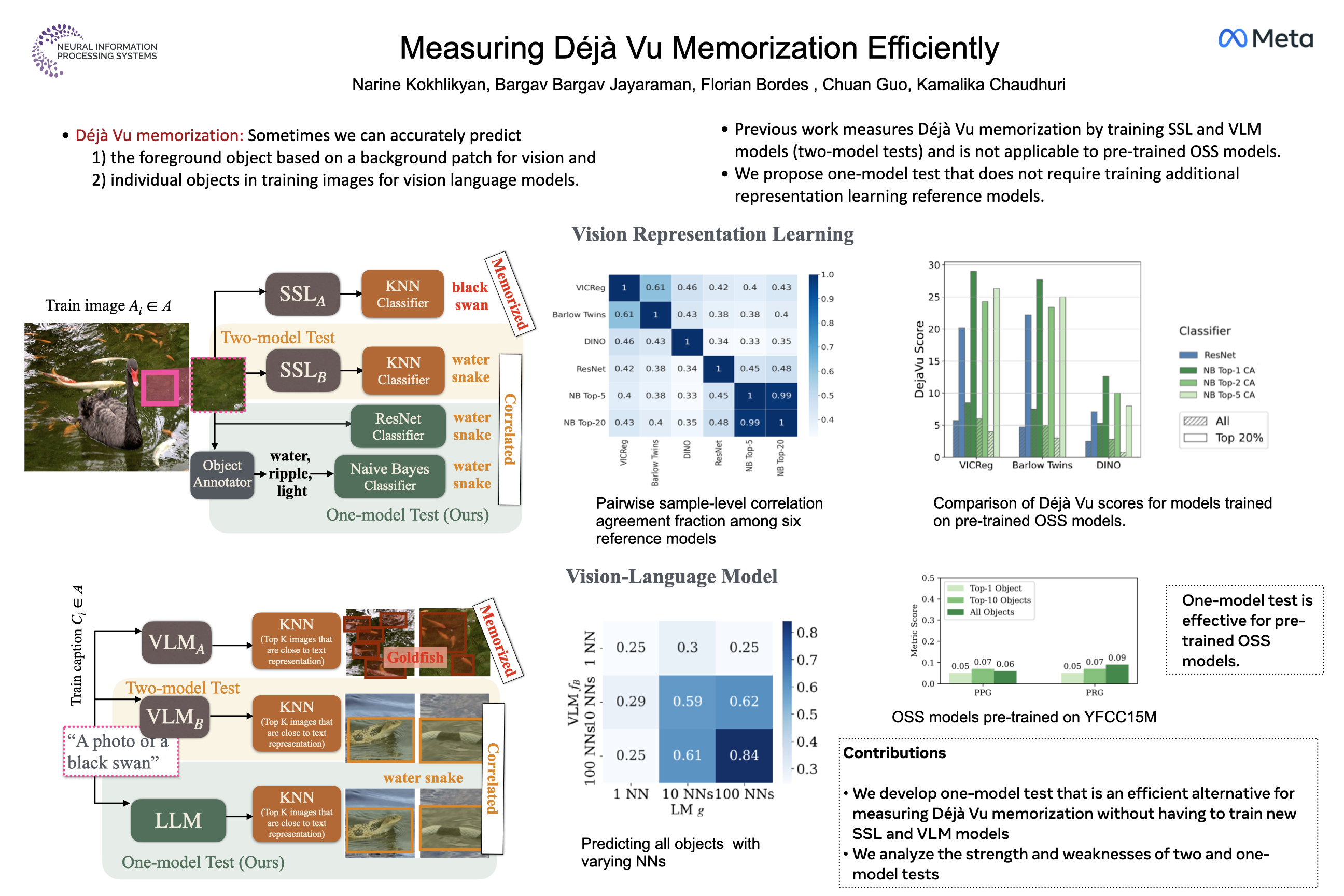
Recent research has shown that representation learning models may accidentally memorize their training data. For example, the déjà vu method shows that for certain representation learning models and training images, it is sometimes possible to correctly predict the foreground label given only the representation of he background – better than through dataset-level correlations. However, their measurement method requires training two models – one to estimate dataset-level correlations and the other to estimate memorization. This multiple model setup becomes infeasible for large open-source models. In this work, we propose alter native simple methods to estimate dataset-level correlations, and show that these can be used to approximate an off-the-shelf model’s memorization ability without any retraining. This enables, for the first time, the measurement of memorization in pre-trained open-source image representation and vision-language models. Our results show that different ways of measuring memorization yield very similar aggregate results. We also find that open-source models typically have lower aggregate memorization than similar models trained on a subset of the data. The code is available both for vision (https://github.com/facebookresearch/DejaVuOSS) and vision language (https://github.com/facebookresearch/VLMDejaVu) models.