Avoiding Undesired Future with Minimal Cost in Non-Stationary Environments
{kind=link}
Abstract
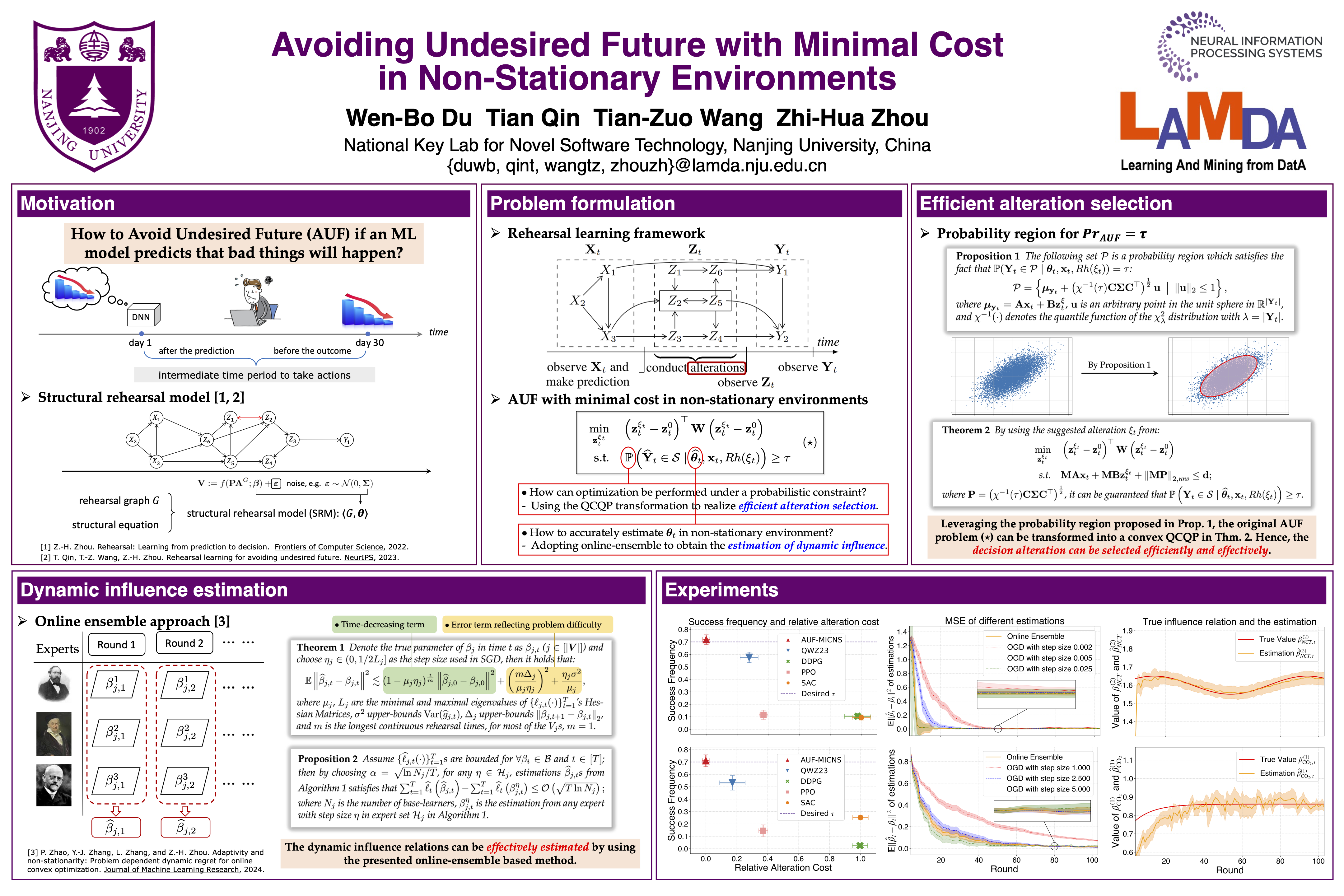
Machine learning (ML) has achieved remarkable success in prediction tasks. In many real-world scenarios, rather than solely predicting an outcome using an ML model, the crucial concern is how to make decisions to prevent the occurrence of undesired outcomes, known as the avoiding undesired future (AUF) problem. To this end, a new framework called rehearsal learning has been proposed recently, which works effectively in stationary environments by leveraging the influence relations among variables. In real tasks, however, the environments are usually non-stationary, where the influence relations may be dynamic, leading to the failure of AUF by the existing method. In this paper, we introduce a novel sequential methodology that effectively updates the estimates of dynamic influence relations, which are crucial for rehearsal learning to prevent undesired outcomes in non-stationary environments. Meanwhile, we take the cost of decision actions into account and provide the formulation of AUF problem with minimal action cost under non-stationarity. We prove that in linear Gaussian cases, the problem can be transformed into the well-studied convex quadratically constrained quadratic program (QCQP). In this way, we establish the first polynomial-time rehearsal-based approach for addressing the AUF problem. Theoretical and experimental results validate the effectiveness and efficiency of our method under certain circumstances.