Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation
{kind=link}
Abstract
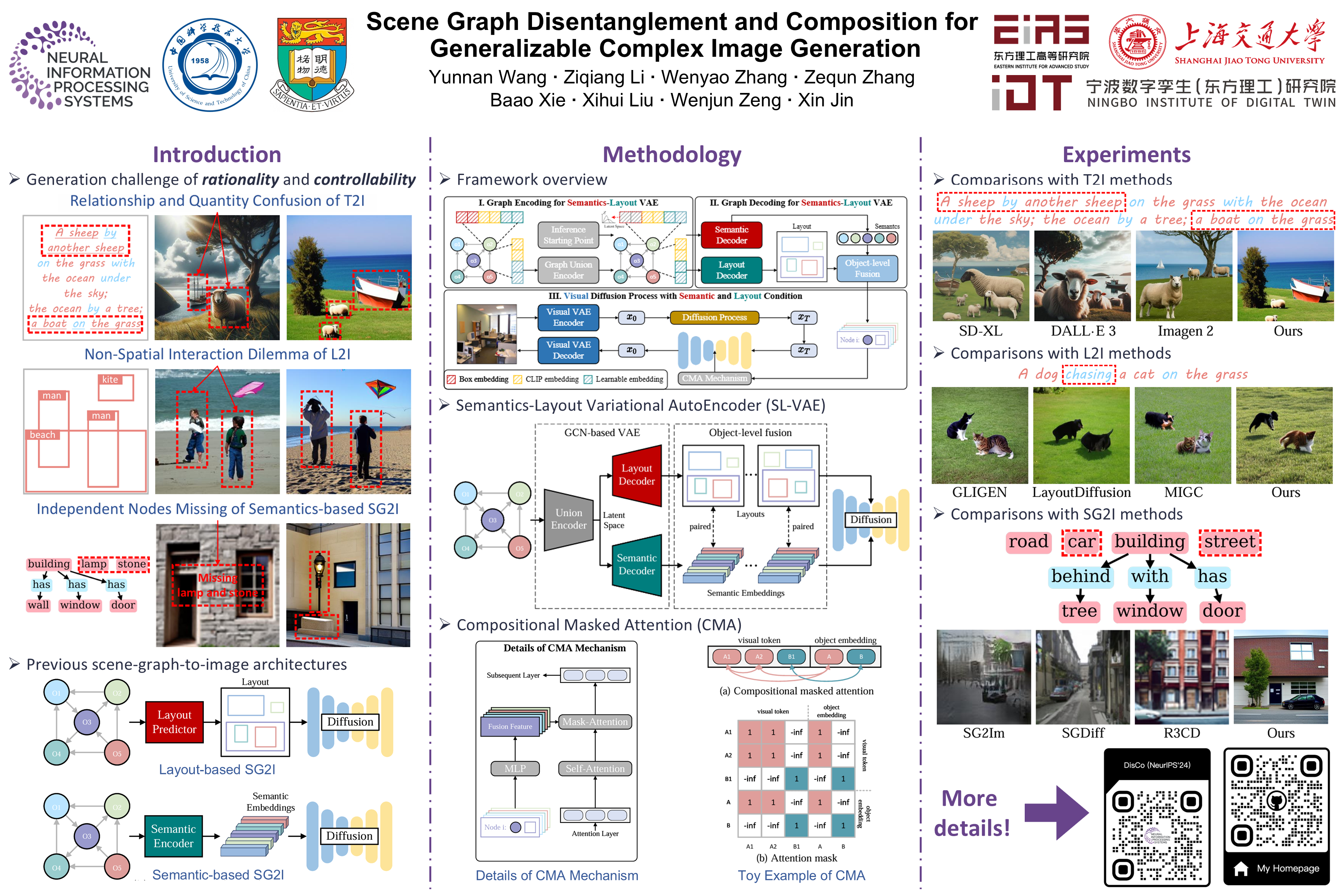
There has been exciting progress in generating images from natural language or layout conditions. However, these methods struggle to faithfully reproduce complex scenes due to the insufficient modeling of multiple objects and their relationships. To address this issue, we leverage the scene graph, a powerful structured representation, for complex image generation. Different from the previous works that directly use scene graphs for generation, we employ the generative capabilities of variational autoencoders and diffusion models in a generalizable manner, compositing diverse disentangled visual clues from scene graphs. Specifically, we first propose a Semantics-Layout Variational AutoEncoder (SL-VAE) to jointly derive (layouts, semantics) from the input scene graph, which allows a more diverse and reasonable generation in a one-to-many mapping. We then develop a Compositional Masked Attention (CMA) integrated with a diffusion model, incorporating (layouts, semantics) with fine-grained attributes as generation guidance. To further achieve graph manipulation while keeping the visual content consistent, we introduce a Multi-Layered Sampler (MLS) for an "isolated" image editing effect. Extensive experiments demonstrate that our method outperforms recent competitors based on text, layout, or scene graph, in terms of generation rationality and controllability.