Converging to Unexploitable Policies in Continuous Control Adversarial Games
{kind=link}
Abstract
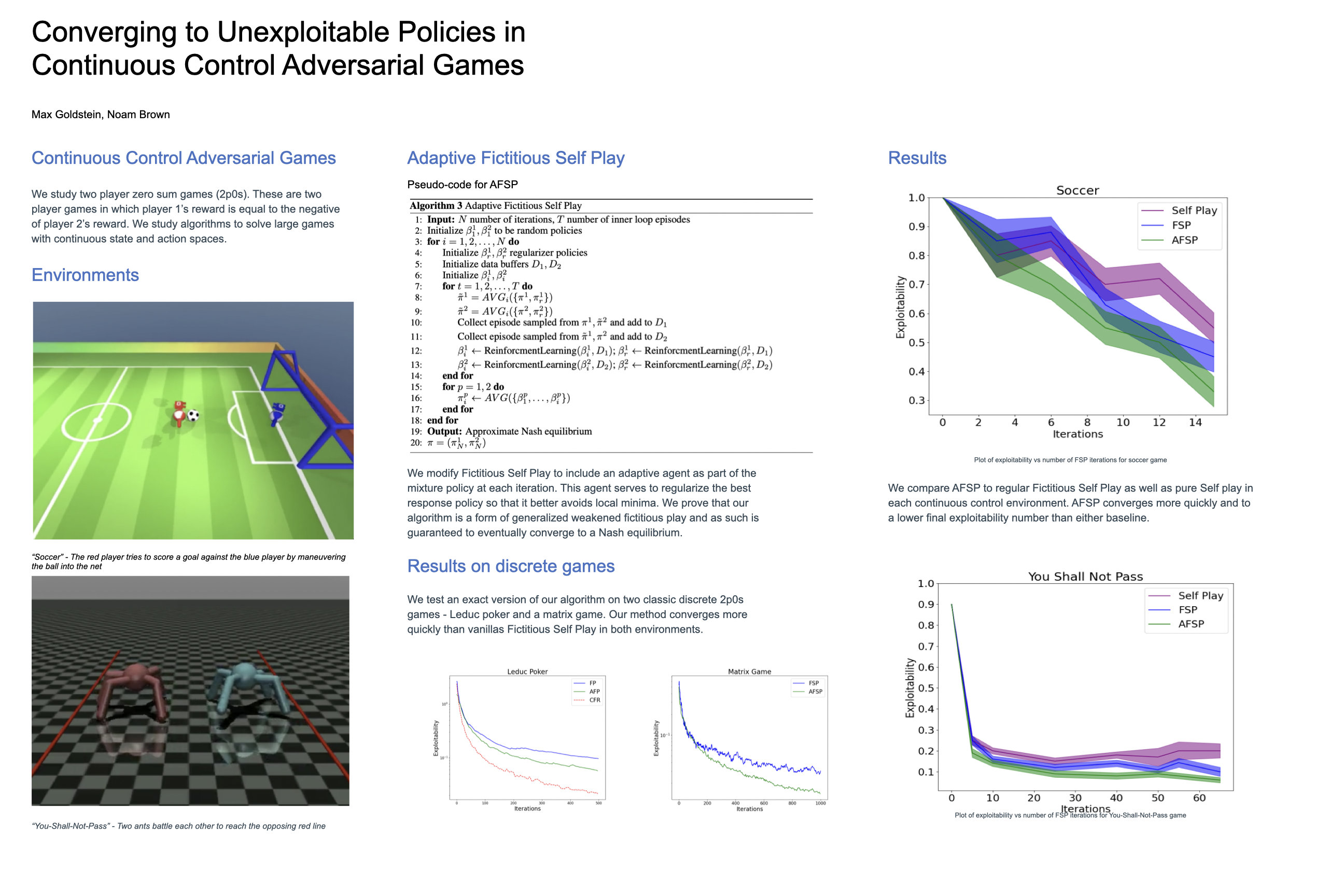
Fictitious Self-Play (FSP) is an iterative algorithm capable of learning approximate Nash equilibria in many types of two-player zero-sum games. In FSP, at each iteration, a best response is learned to the opponent's meta strategy. However, FSP can be slow to converge in continuous control games in which two embodied agents compete against one another. We propose Adaptive FSP (AdaptFSP), a deep reinforcement learning (RL) algorithm inspired by FSP. The main idea is that instead of training a best response only against the meta strategy, we additionally train against an adaptive deep RL agent that can adapt to the best response. In four test domains, two tabular cases--random normal-form matrix games, Leduc poker--and two continuous control tasks--Thou Shall Not Pass and a soccer environment--we show that AdaptFSP achieves lower exploitability more quickly than vanilla FSP.