Perturbed Quantile Regression for Distributional Reinforcement Learning
{kind=link}
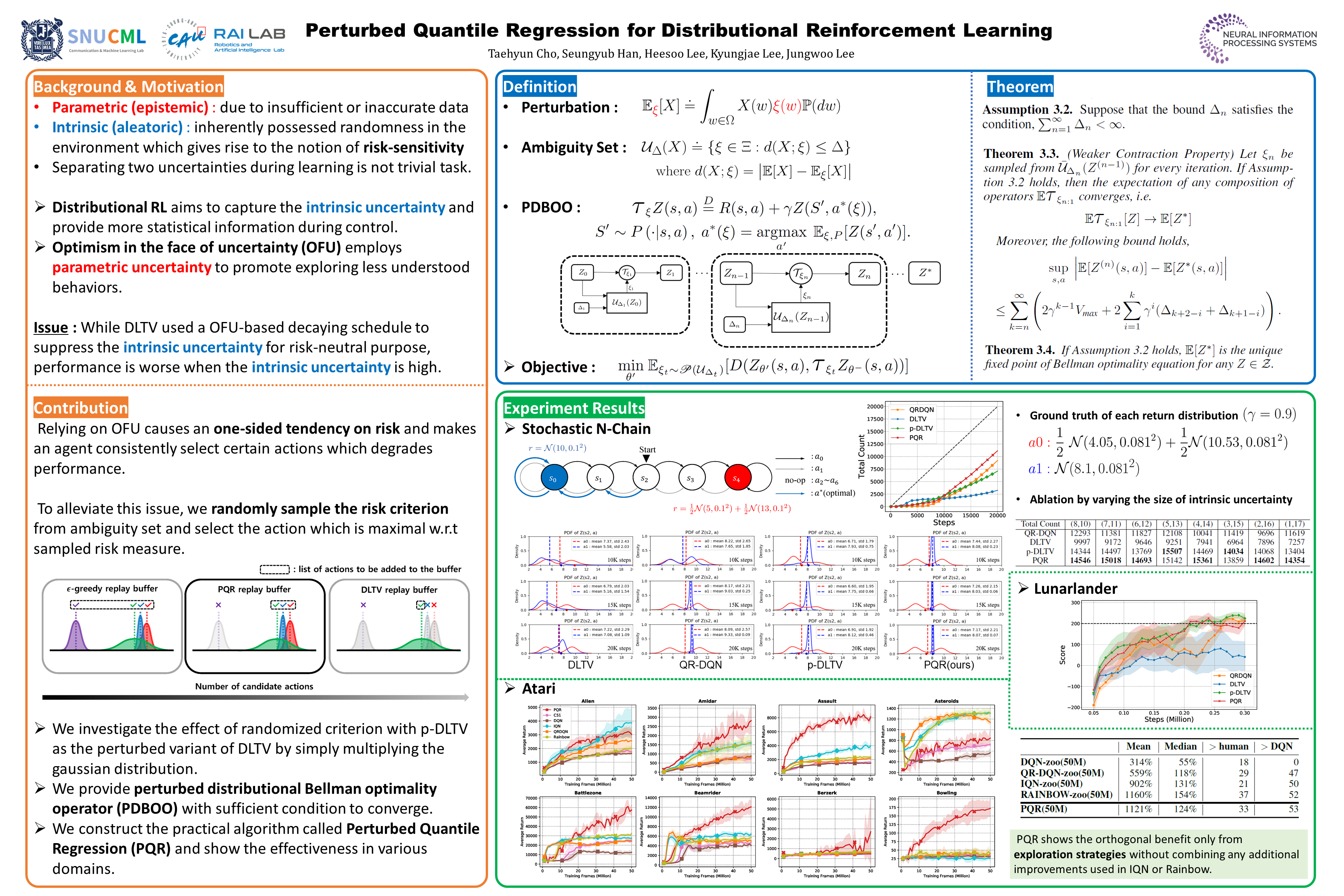
Abstract
Distributional reinforcement learning aims to learn distribution of return under stochastic environments. Since the learned distribution of return contains rich information about the stochasticity of the environment, previous studies have relied on descriptive statistics, such as standard deviation, for optimism in the face of uncertainty. However, using the uncertainty from an empirical distribution can hinder convergence and performance when exploring with the certain criterion that has an one-sided tendency on risk in these methods. In this paper, we propose a novel distributional reinforcement learning that explores by randomizing risk criterion to reach a risk-neutral optimal policy. First, we provide a perturbed distributional Bellman optimality operator by distorting the risk measure in action selection. Second, we prove the convergence and optimality of the proposed method by using the weaker contraction property. Our theoretical results support that the proposed method does not fall into biased exploration and is guaranteed to converge to an optimal return distribution. Finally, we empirically show that our method outperforms other existing distribution-based algorithms in various environments including 55 Atari games.