Efficient Multi-Task Reinforcement Learning via Selective Behavior Sharing
{kind=link}
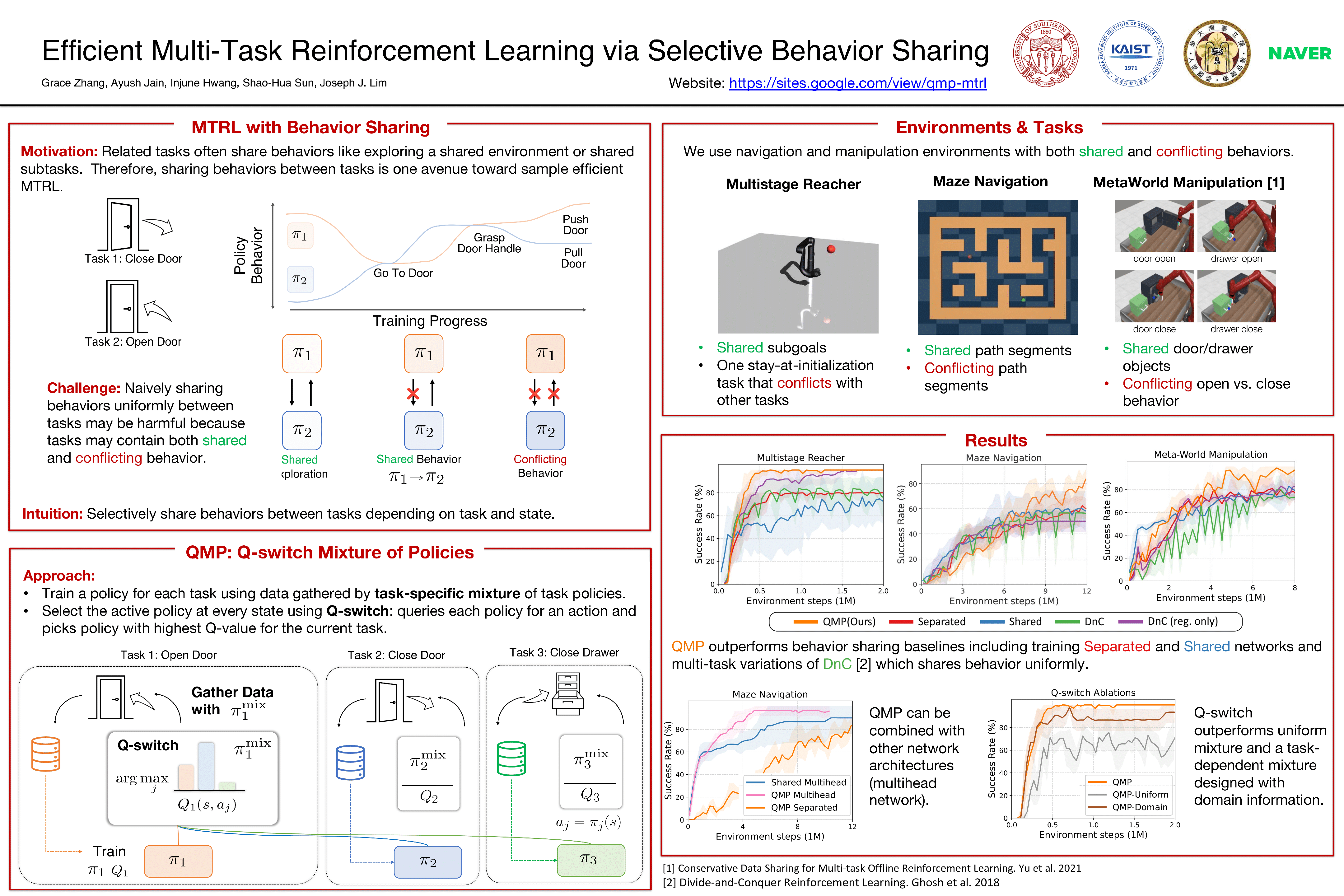
Abstract
The ability to leverage shared behaviors between tasks is critical for sample efficient multi-task reinforcement learning (MTRL). Prior approaches based on parameter sharing or policy distillation share behaviors uniformly across tasks and states or focus on learning one optimal policy. Therefore, they are fundamentally limited when tasks have conflicting behaviors because no one optimal policy exists. Our key insight is that, we can instead share exploratory behavior which can be helpful even when the optimal behaviors differ. Furthermore, as we learn each task, we can guide the exploration by sharing behaviors in a task and state dependent way. To this end, we propose a novel MTRL method, Q-switch Mixture of policies (QMP), that learns to selectively shares exploratory behavior between tasks by using a mixture of policies based on estimated discounted returns to gather training data. Experimental results in manipulation and locomotion tasks demonstrate that our method outperforms prior behavior sharing methods, highlighting the importance of task and state dependent sharing.