Bayesian Q-learning With Imperfect Expert Demonstrations
{kind=link}
Abstract
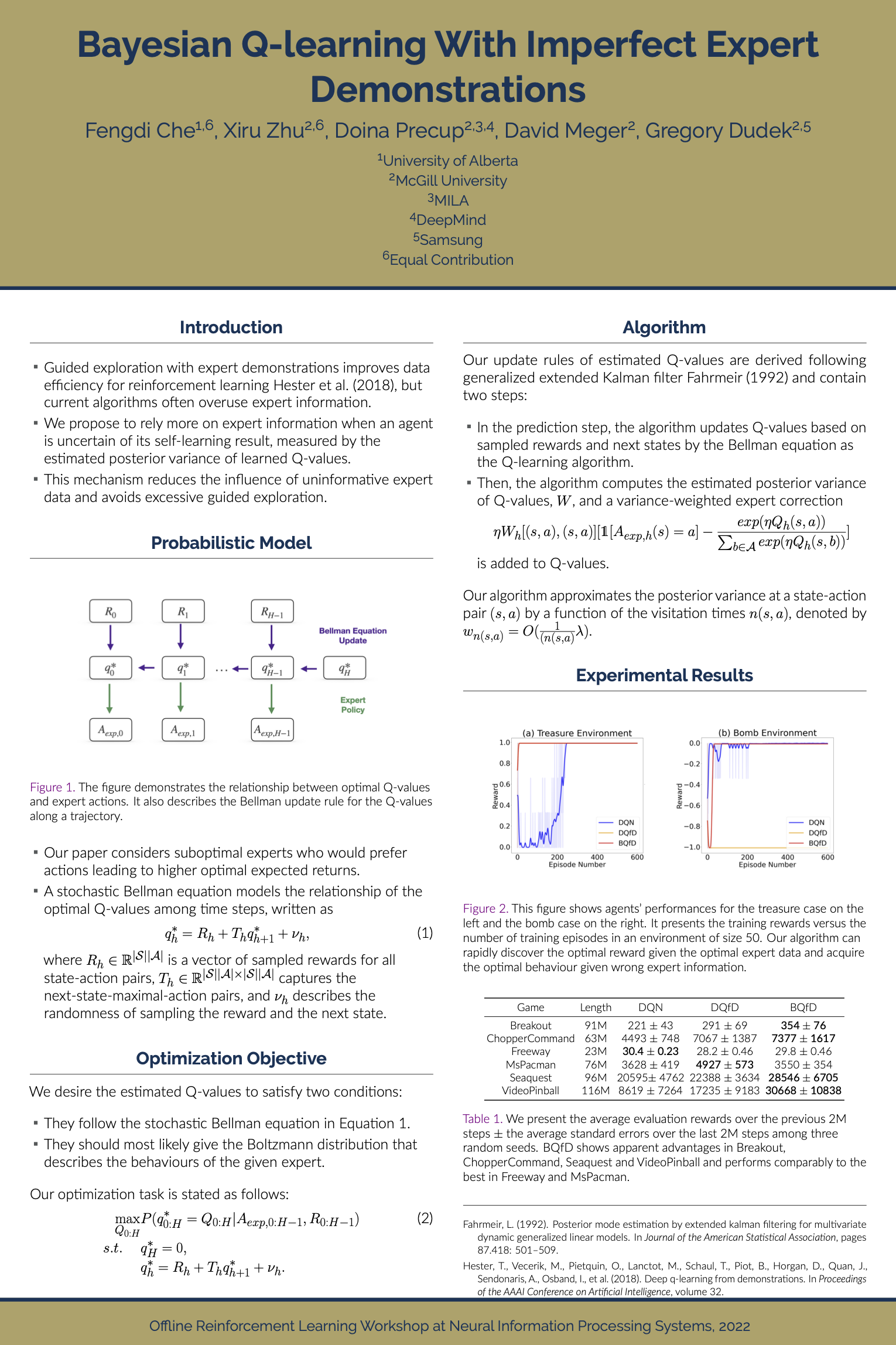
Guided exploration with expert demonstrations improves data efficiency for reinforcement learning, but current algorithms often overuse expert information. We propose a novel algorithm to speed up Q-learning with the help of a limited amount of imperfect expert demonstrations. The algorithm is based on a Bayesian framework to model suboptimal expert actions and derives Q-values' update rules by maximizing the posterior probability. It weighs expert information by the uncertainty of learnt Q-values and avoids excessive reliance on expert data, gradually reducing the usage of uninformative expert data. Experimentally, we evaluate our approach on a sparse-reward chain environment and six more complicated Atari games with delayed rewards. With the proposed methods, we can achieve better results than Deep Q-learning from Demonstrations (Hester et al., 2017) in most environments.